OpenMP for Android初学记录

1. 资料整理与收集
1.1 国外资料
(1). Wiki上的介绍:http://en.wikipedia.org/wiki/OpenMP
(2). OpenMP教程: http://www.llnl.gov/computing/tutorials/openMP
(3). 并行计算介绍:https://computing.llnl.gov/tutorials/parallel_comp/
(4). 官方指定参考书:《Using OpenMP》CSDN上的下载链接
1.2 国内资料
(1). OpenMP编程指南:http://blog.csdn.net/drzhouweiming/article/details/4093624
(2). OpenMP教程翻译:http://blog.csdn.net/gengshenghong/article/category/925589
2. OpenMP介绍
OpenMP是一种应用程序接口(API),支持多平台共享内存的C/C++/Fortran多处理器编程,可以运行在绝大多数处理器架构和操作系统上,包括Solaris, AIX, HP-UX, GNU/Linux, Mac OS X和Windows平台。它由编译器指令集、库函数和环境变量组成,影响运行时行为。
OpenMP使用一种可移植、可伸缩的模型,给予编程者一个简单和灵活的接口来开发并行应用。
OpenMP是多线程的一种实现,一种通过一个主线程fork一些指定数目从线程的并行化方法,任务在它们之间分解。线程然后同时运行,通过运行时环境分配线程到不同的处理器。
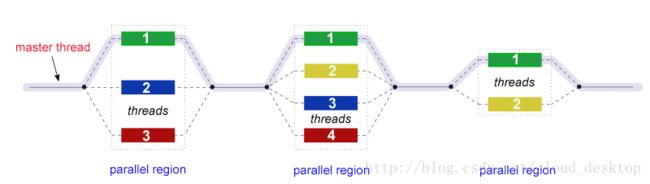
并行执行的代码部分相应地被标记,放置一条预处理指令在并行执行部分之前,引起线程的形成。每个线程有一个附带的id,可以使用函数omp_get_thread_num()获取到。线程id是个整数,主线程的id为0。并行化代码执行后,线程join回到主线程,继续向着程序的结尾前进。
默认地,每个线程独立地执行代码的并行化部分。工作共享结构可以被用于在线程之间分解任务,从而使每个线程执行代码所分配的部分。以这种方式使用OpenMP,任务并行和数据并行都可以被实现。
运行时环境根据使用情况,机器负载和其它因素,分配线程到处理器。线程的数目可以被运行时环境赋值,基于环境变量或在代码中使用函数。OpenMP函数在C/C++中被包括在头文件omp.h中。
3. OpenMP核心元素
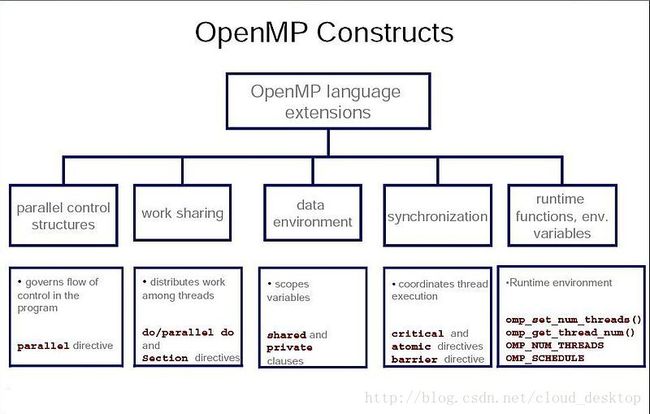
OpenMP的核心元素是线程创建、工作负载分布(工作分享)、数据环境管理、线程同步、用户级运行时函数和环境变量。
3.1 线程创建
编译器指令omp parallel被用于fork附加的线程来并行地执行附带在结构上的工作。原始的线程会被表示为主线程以线程ID 0。
样例(C程序):显示“Hello, world.”使用多线程。
#include
int main(void)
{
#pragma omp parallel
printf("Hello, world.\n");
return 0;
} $ gcc -fopenmp hello.c -o helloHello, world.
Hello, world.
Hello, wHello, woorld.
rld.3.2 工作共享结构
被用于指定如何指定独立的工作给一个或所有的线程。
>omp for或omp do: 被用于分解循环迭代到线程,也称为循环结构;
> sections: 指定连续的但独立的代码块到不同的线程
> single: 指定一个代码块,仅被一个线程执行,最后隐含一个屏障(barrier);
> master: 与single类似,但是代码块只会被主线程执行,最后没有隐含屏障
样例:以并行化的方式初始化一个大数组的值,每个线程做工作的一部分。
int main(int argc, char *argv[]) {
const int N = 100000;
int i, a[N];
#pragma omp parallel for
for (i = 0; i < N; i++)
a[i] = 2 * i;
return 0;
}3.3 OpenMP条款
因为OpenMP是个共享内存编程模型,大多数OpenMP代码中的变量默认对所有线程可见。但是有时候私有变量是必要的以避免竞争条件,并且有需要在串行部分和并行部分区域之间传值,因此数据环境管理被介绍为数据共享属性条款,通过附加它们到OpenMP指令上。
3.3.1 数据共享属性条款
> shared:数据在并行区域内是共享的,这意味着可以同时对所有线程可见和可访问。默认地,所有变量在工作共享区域是共享的,除了循环迭代计数器。
> private:数据在并行区域内对每个线程私有,这意味着每个线程会有一份本地拷贝,并且作为临时变量使用。一个私有变量没有被初始化,并且值在并行化区域之外并不会被维护使用。默认,OpenMP循环结构中的循环迭代计数器是私有的。
> default:允许编程者声明在并行区域内的默认数据范围,对于C/C++来说,可选shared或none。none选项强制编程者声明并行区域中的每个变量,使用数据共享属性条款。
> firstprivate:类似private,除了被初始化为原始值。
> lastprivate: 类似private,除了原始值是在结构之后更新。
> reduction:一种在结构之后连接所有线程的方式。
3.3.2 同步条款
> critical:包含的代码块在一个时间只会被一个线程执行,不会同时由多个线程执行。它常会被用于在竞争条件下保护共享数据。
> atomic:在接下来的指令中的内存更新(写,或读-修改-写)会被原子地执行。它不会使得整个声明原子化;只有内存更新时原子的。编译器可能使用特殊硬件指令以获得更好的性能,相比使用critical。
> ordered:结构化模块会被顺序执行,以顺需循环中迭代的顺序。
> barrier:每个线程等待直到同一组中所有其它线程都已到达这一点。一个工作共享结构在最后都有一个隐含的barrier同步。
> nowait:指定线程完成分配的任务后可以继续,而不是等待所有同一组中其它线程完成。没有这一条款,线程在工作共享结构的最后会遇到一个barrier同步。
3.3.3 调度条款
> schedule(type, chunk):如果工作共享结构是个do循环或for循环,这是有用的。工作共享结构中的迭代是被赋值给线程,根据这个条款定义的调度方式。三种类型的调度是:
1.static:这里,在执行循环迭代之前,所有线程被分配迭代。默认迭代在线程之间相等地分配。然而,为参数chunk指定一个整数会分配chunk数目个连续的迭代到一个特定的线程。
2.dynamic:这里,其中一些迭代被分配给更小数目的线程。一旦一个特定线程完成分配给它的迭代,它返回来从剩下的迭代中获取另一个。参数chunk定义了一个线程每次连续迭代的数目。
3.guided:一大块连续的迭代被动态地分配给每个线程(如上)。块的大小以指数方式递减,每次连续分配的最小大小在参数chunk中被指定。
3.3.4 IF控制
> if:它会引起线程来并行化仅当条件被满足时。否则代码块串行执行。
3.3.5 初始化
> firstprivate:数据对每个线程私有,但是初始化使用来自主线程的同名变量的值。
> lastprivate:数据对每个线程私有。如果当前迭代是并行化循环中的最后一次迭代,这一私有数据的值会被拷贝到一个全局变量,后者在并行区域之外使用相同的名字。一个变量可以同时是firstprivate和lastprivate的。
> threadprivate:数据是个全局数据,但是在每个并行化区域的运行时期间它是私有的。threadprivate与private的不同之处在于,全局范围内与threadprivate相关联,并且保存的值跨并行区域。
3.3.6 数据拷贝
> copyin:类似于private变量的firstprivate,threadprivate变量不会被初始化,除非使用copyin从相应的全局变量来传值。copyout是不必要的,因为一个threadprivate变量的值在整个程序的执行期间被维护。
> copyprivate:与single一起使用,以支持在同一组内的一个线程(single线程)中来自私有对象的数据值到其它线程相应对象的拷贝。
3.3.7 Reduction
> reduction(operator | intrinsic : list):这个变量在每个线程中都有一份本地拷贝,但是本地拷贝的值会被汇总(减少)到一个全局共享变量中。如果一种数据类型的一个特定的操作(在此特定条款的operator中被指定)反复迭代地运行,特定迭代的的值取决于前一次迭代的值。从根本上说,导致增量操作的步骤是并行化的,但是线程收集在一起,在更新数据类型之前等待,顺序更新数据类型从而避免竞争条件。这会是被需要的,在并行化的数值积分函数和差分方程,作为一个常见的例子。
3.3.8 其它
>flush:这个变量的值从寄存器恢复到内存,为了在并行化部分的外面使用这个值
>master:只被主线程执行。没有隐含的barrier;其它组内成员(线程)不需要到达。
3.4 用户级运行时例程
用于修改/检查线程的数目,检查执行上下文是否在并行区域,当前系统有多少个处理器,设置/复位锁,定时函数,等等。
3.5 环境变量
修改OpenMP应用执行特性的一种方式。被用于控制循环迭代调度,线程的默认数量,等等。例如,OMP_NUM_THREADS被用于为一个应用指定线程的数目。
4 样例程序
在此部分,提供一些样例程序来阐述前面解释的概念。
4.1 Hello World
一个基本的程序,执行parallel,private和barrier指令,和函数omp_get_thread_num与omp_get_num_threads(别混淆了)。
4.1.1. C语言版本
编译使用:gcc -o test test.c -fopenmp
#include
#include
#include
int main (int argc, char *argv[]) {
int th_id, nthreads;
#pragma omp parallel private(th_id)
{
th_id = omp_get_thread_num();
printf("Hello World from thread %d\n", th_id);
#pragma omp barrier
if ( th_id == 0 ) {
nthreads = omp_get_num_threads();
printf("There are %d threads\n",nthreads);
}
}
return EXIT_SUCCESS;
} 4.1.2. C++版本
编译使用:g++ -o test test.c -fopenmp -Wall
注意:IOstreams库不是线程安全的。因此,例如,cout调用必须在临界区域执行,或者是只被一个线程执行(例如主线程)。
#include
using namespace std;
#include
int main(int argc, char *argv[])
{
int th_id, nthreads;
#pragma omp parallel private(th_id) shared(nthreads)
{
th_id = omp_get_thread_num();
#pragma omp critical
{
cout << "Hello World from thread " << th_id << '\n';
}
#pragma omp barrier
#pragma omp master
{
nthreads = omp_get_num_threads();
cout << "There are " << nthreads << " threads" << '\n';
}
}
return 0;
} 4.2 工作共享结构(C/C++)中的条例
下面的代码片段通过对数组a中元素执行简单地操作更新数组b中的元素。并行化由OpenMP指令#pragma omp完成。任务的调度是动态的。注意迭代计数器j和k必须是private的,每个线程在它的执行栈创建它自己版本的j和k,因此做分配给它的全任务,与其它线程一样同时更新数组b的分配部分。
#define CHUNKSIZE 1 /*defines the chunk size as 1 contiguous iteration*/
/*forks off the threads*/
#pragma omp parallel private(j,k)
{
/*Starts the work sharing construct*/
#pragma omp for schedule(dynamic, CHUNKSIZE)
for(i = 2; i <= N-1; i++)
for(j = 2; j <= i; j++)
for(k = 1; k <= M; k++)
b[i][j] += a[i-1][j]/k + a[i+1][j]/k;
}
#define N 10000 /*size of a*/
void calculate(long *); /*The function that calculates the elements of a*/
int i;
long w;
long a[N];
calculate(a);
long sum = 0;
/*forks off the threads and starts the work-sharing construct*/
#pragma omp parallel for private(w) reduction(+:sum) schedule(static,1)
for(i = 0; i < N; i++)
{
w = i*i;
sum = sum + w*a[i];
}
printf("\n %li",sum);...
long sum = 0, loc_sum;
/*forks off the threads and starts the work-sharing construct*/
#pragma omp parallel private(w,loc_sum)
{
loc_sum = 0;
#pragma omp for schedule(static,1)
for(i = 0; i < N; i++)
{
w = i*i;
loc_sum = loc_sum + w*a[i];
}
#pragma omp critical
sum = sum + loc_sum;
}
printf("\n %li",sum);5 正反两方面
5.1 正面
> 可移植多线程代码(C/C++和其它语言,典型地必须调用平台相关的原语以获得多线程)
> 简单:不必处理像MPI中那样的消息传递
> 数据的布局和分解由指令自动处理
> 相比MPI,在共享内存系统上可伸缩
> 增量的并行性:同时在程序的一部分上工作,不必大幅修改代码
> 串行和并行应用的统一化的代码:OpenMP结构在串行编译器使用时被当成注释
> 通常,最初(串行)代码声明不必修改,在用OpenMP并行化时。这减少了不经意间引入bug的机会。
> 粗粒度和细粒度的并行化都是有可能的
> 对于不规则多场地的应用,不完全遵守的SPMD模式计算,OpenMP的灵活性相比MPI具有很大的优势
> 可以被用于多种加速器,例如GPGPU
5.2 反面
> 引入难以调试的同步化bug和竞争条件的风险
> 当前仅在共享内存多核平台有效运行
> 需要编译器支持OpenMP
> 可扩展性受内存架构限制
> 不支持比较并交换(compare-and-swap,在多线程中实现同步原子操作)
> 没有可靠地错误处理
> 缺少细粒度机制来控制线程到处理器的映射
> 编写假共享代码的机会上升
> 多线程可执行文件通常引发更长的启动时间,相比单线程应用,因此,如果程序的运行时间足够短,做成多线程并没有优势
> 经常的情况是,多线程被使用时,没有多少好处但是确定仍然存在。
6 性能期望
有人可能会期望在一个有N个处理器平台上运行的使用OpenMP并行化的程序,会提升N倍的速度。然而,这几乎不会发生,因为这些原因:
> 当一个依赖存在时,一个过程必须等待直到它依赖的数据被计算
> 当多个过程共享一个非并行资源(像一个写入的文件)时,它们的请求会被顺序执行。因此,每个线程必须等待其它线程释放资源
> 程序的一大部分可能不会被OpenMP并行化,这意味着根据Amdahl定律,速度的理论上限是受限的
> 在对称多处理器中的N个处理器可能会有N倍的计算能力,但是内存带宽通常不会按比例增加N倍。经常的情况是,原始的内存路径被多核处理器共享,当它们竞争共享内存带宽时,性能下降就可能会观察到。
> 很多其它常见的,会影响并行计算中的最终提速的问题,也适用于OpenMP,像负载平衡和同步开销
7 线程关联
一些厂商推荐在OpenMP上设置处理器关联,以使线程与特定处理器核相关联。这最小化处理器核之间的线程移动和上下文切换开销。它也提高了数据的局部性,减少了处理器核心之间的缓存一致性移动。