【知识星球】模型压缩和优化板块火热更新中
欢迎大家来到《知识星球》专栏,这里是网络结构1000变小专题,最近星球开始上线模型压缩相关内容。
作者&编辑 | 言有三
1 模型优化与压缩
模型优化与压缩涉及到紧凑模型的设计,量化与剪枝以及相关的工业界使用技巧共3个大方向。最近会集中上线一些内容,已有内容欢迎大家预览。
有三AI知识星球-网络结构1000变
Deep Compression
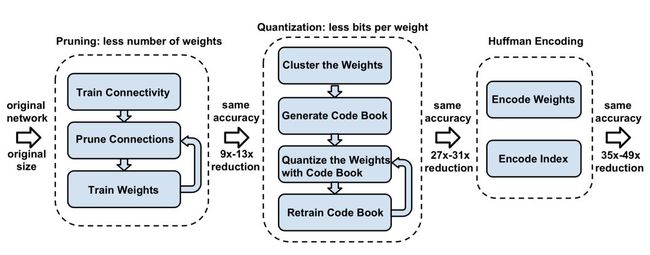
Deep Compression是一个模型量化和压缩框架,
包含剪枝(pruning), 量化(trained quantization)和编码(Huffman coding)三个步骤。
作者/编辑 言有三
Deep Compression综合应用了剪枝、量化、编码三个步骤来进行模型压缩,是2016 ICLR最佳论文。在不影响精度的前提下,把500M的VGG压缩到了11M,使得深度卷积网络移植到移动设备上成为可能。
如上所示,包括三个步骤:
(1) 网络剪枝
即移除不重要的连接,包括3个步骤,分别是普通网络训练,删除权重小于一定阈值的连接得到稀疏网络,对稀疏网络再训练,这是一个反复迭代的过程。这一步对于AlexNet和VGG-16模型,分别将参数降低为原来的1/9和1/13。
(2) 权重量化
权值量化是把网络的连接权值从高精度转化成低精度的操作过程,例如将32位浮点数float32转化成8位定点数int8或二值化为1bit,转换后的模型准确率等指标与原来相近,但模型大小变小,运行速度加快。一般操作是先训练模型,再进行量化,测试时使用量化后的模型。
如下图,这是一个4×4的权值矩阵,量化权重为4阶,即2bit,分别对应浮点数-1.0,0,1.5,2.0。
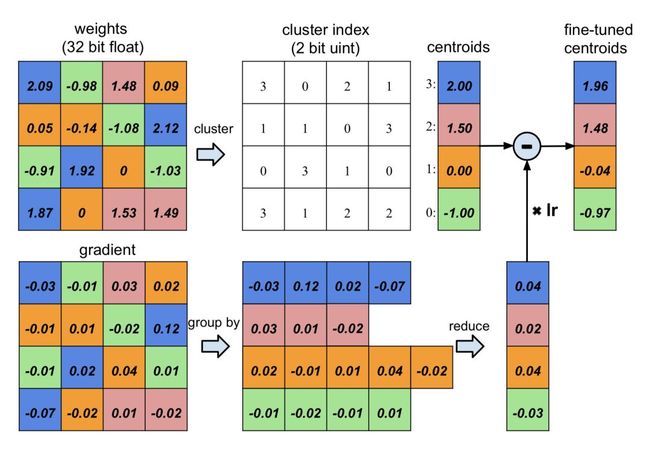
对weights矩阵采用cluster index进行存储后,原来需要16个32bit float,现在只需要4个32bit float,与16个2bit uint,参数量为原来的(16×2+4×32)/(16×32)=0.31。
这就完成了存储,那如何对量化值进行更新呢?事实上,文中仅对码字进行更新,也就是量化后的2bit的权重。
将索引相同的地方梯度求和乘以学习率,叠加到码字,这就是不断求取weights矩阵的聚类中心。原来有成千上万个不同浮点数的weights矩阵,经过一个有效的聚类后,每一个值都用其聚类中心进行替代,作者的研究表明这样并不会降低网络的效果。而聚类的迭代过程,通过BP的反向传播完成。
(3) 霍夫曼编码
霍夫曼编码是一种成熟的编码技巧,与CNN无关,它有效地利用了权重的有偏分布,可以进一步减少需要存储的参数体积。
性能如何呢?下表展示了LeNet,AlexNet,VGG的结果。
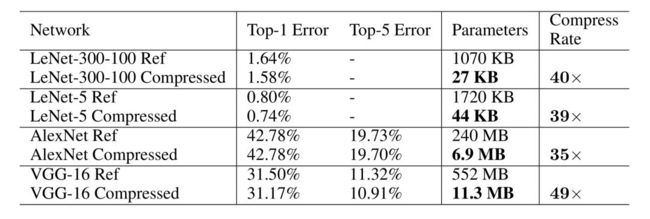
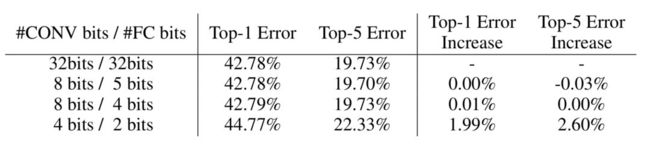
可知道在不降低精度的前提下,LeNet-5,AlexNet,VGG的压缩倍率分别达到了40,35,49。在卷积层和全连接层的量化阶数分别为8/5,8/4的配置下,模型性能几乎无损,验证了这是一种非常优异的模型压缩技巧。
[1] Han S, Mao H, Dally W J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding[J]. arXiv preprint arXiv:1510.00149, 2015.
有三AI知识星球-网络结构1000变
DeepRebirth
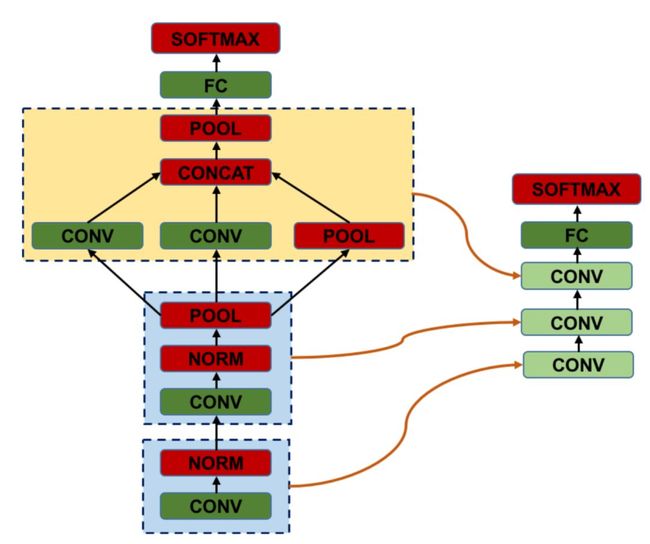
在深度学习模型中有许多的非tensor网络层虽然参数很少,但是有较大的计算量,因此模型在最终部署到移动端时经常合并这些网络层从而进一步提高推理速度。
作者/编辑 言有三
模型压缩有许多的方法,比如使用小卷积,多尺度,去除全连接层,瓶颈结构等思路设计紧凑的网络,也有对权重进行量化剪枝等方法,而DeepRebirth则采用了另外一种思路,即将Non-tensor layer(包括pooling、BN、LRN、ReLU等)合并到tensor层中,因为它们虽然参数不多,但是有很大的计算量,下面首先看看经典网络中这些层的计算时间比例:
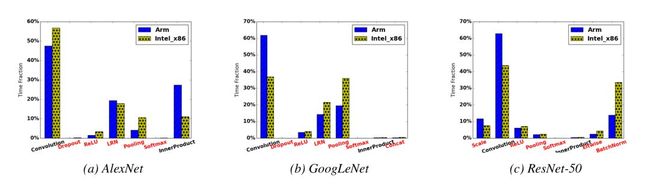
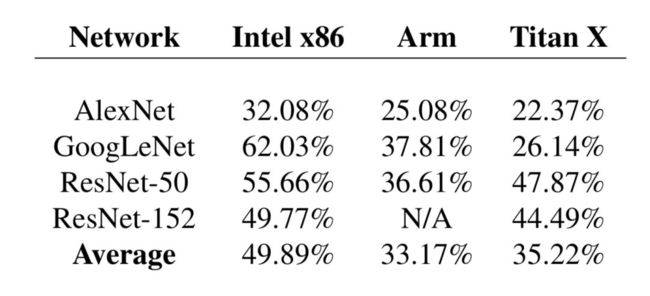
可以看出这些非卷积层占据了很大比例的计算时间,在Intel x86上甚至能占到一半,如果能够将其去除将大幅度的提升模型的运算速度。
作者提出了两种思路,分别是StreamLine Merging和Branch Merging。
StreamLine Merging是一种串行的合并方式,如下:
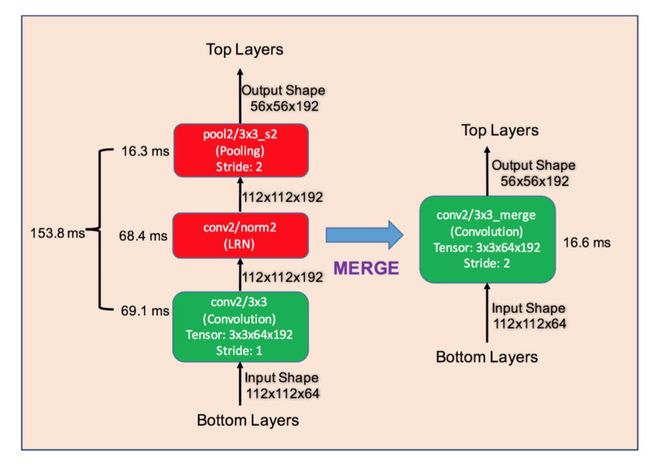
通常来说,就是将Pooling、LRN,BN等网络层与相邻近的Conv层进行合并,上图的案例中经过合并后从153.8ms直接降低到了16.6ms。这里卷积本身的计算时间也大大降低,是因为pool2融合进了conv,使其步长从1变为2。
现今更为常见的情况是将BN,Scale等网络层和相邻的Conv层合并,也能降低不少计算量。
Branch Merging是一个分支的合并方式,如下:
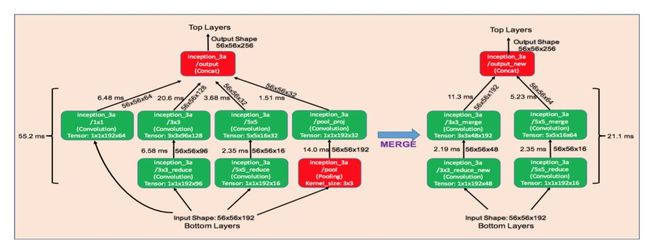
如上图,将1*1卷积层以及Pooling层分支分别合并到和它并行的3*3卷积和5*5卷积分支中。另外考虑到3*3卷积和5*5卷积分支输出通道增加会增大参数量和运算量,因此调整这些分支的输入通道进行压缩。
在进行以上的合并后,模型的性能通常会降低,所以需要重新训练,作者采用的方式是合并得到的新层使用标准的初始化方式,将其他层的参数固定不变,然后将新层的学习率设置为其他层的10倍后进行finetuning。
那么实验效果如何呢?以GoogLeNet为基准模型的实验结果如下:

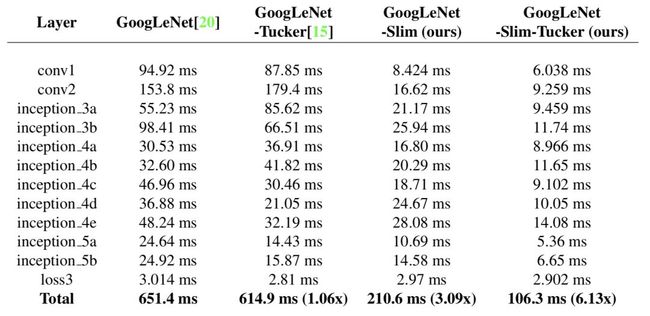
上表展示了对不同的网络层使用以上合并策略,可以发现各种网络层的速度都有很大提升,在精度只降低0.4%的时候,能有超过3倍的速度提升。
这是非常实用且强大的一个提升模型运行速度的方法,在实际进行模型部署时,常常会对BN等网络层进行合并。
[1] Li D, Wang X, Kong D. Deeprebirth: Accelerating deep neural network execution on mobile devices[C]//Thirty-Second AAAI Conference on Artificial Intelligence. 2018.
更多紧凑模型设计可见。

更多模型剪枝和量化可见。

2 如何掌握网络设计和数据使用
关于如何系统性学习网络结构设计和数据使用,可以阅读我们对星球生态的介绍,有三风格的干货,相信你不会失望。
如何系统性掌握深度学习模型设计和优化
如何系统性掌握深度学习中的数据使用
有三AI知识星球的内容非常多,大家可以预览一些内容如下。



以上所有内容
加入有三AI知识星球即可获取
来日方长
点击加入
不见不散
更多精彩
每日更新

转载文章请后台联系
侵权必究

往期精选
揭秘7大AI学习板块,这个星球推荐你拥有
有三AI 1000问回归,备战秋招,更多,更快,更好,等你来战!
【知识星球】做作业还能赢奖金,传统图像/机器学习/深度学习尽在不言
【知识星球】颜值,自拍,美学三大任务简介和数据集下载
【知识星球】数据集板块重磅发布,海量数据集介绍与下载
【知识星球】猫猫狗狗与深度学习那些事儿
【知识星球】超3万字的网络结构解读,学习必备
【知识星球】视频分类/行为识别网络和数据集上新
【知识星球】3D网络结构解读系列上新
【知识星球】动态推理网络结构上新,不是所有的网络都是不变的
【知识星球】Attention网络结构上新,聚焦才能赢
【知识星球】几个人像分割数据集简介和下载
【知识星球】总有些骨骼轻奇,姿态妖娆的模型结构设计,不知道你知不知道,反正我知道一些
【知识星球】从SVM对偶问题,到疲劳驾驶检测,到实用工业级别的模型压缩技
【知识星球】图像降噪模型和数据集内容开启更新,经典问题永垂不朽