win10下YOLO v3训练自己的数据集
一、YOLO v3的下载与编译
1、安装VS(YOLOv3支持vs2012、2013、2015,其他版本需要下载工具集)
去https://visualstudio.microsoft.com/downloads/?lang=en下载vs,YOLOv3支持vs2012、2013、2015,其他版本需要下载工具集(本人使用VS2017),下载工具集步骤:在电脑搜索框输入vi,点击Visual Studio Installer。
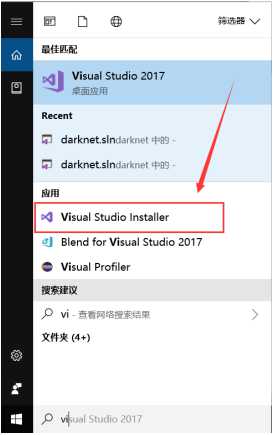
出现如下界面,点击修改,如图:
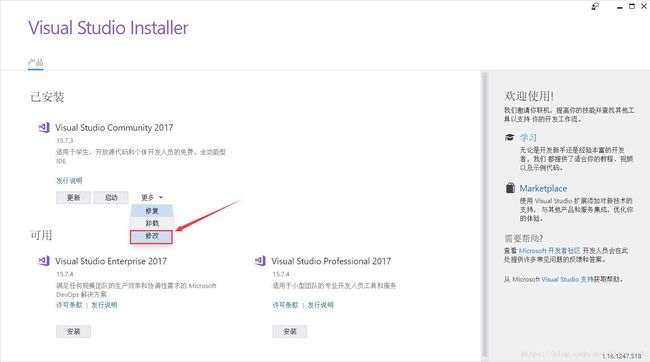
出现以下界面,找到v140工具集,选中,点击修改即可,如图:
2、安装cuda(版本 >= 7.5)
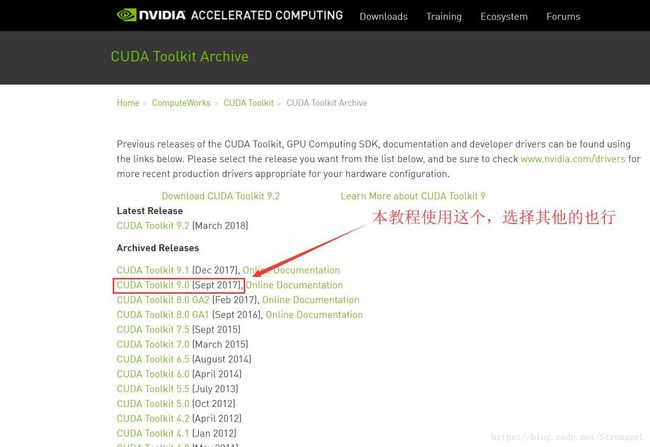
cuda下载地址
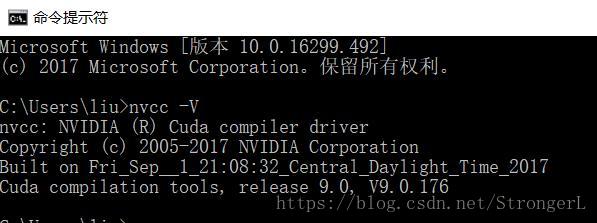
下载完成后双击安装,安装成功后在命令行输入nvcc -V,出现以下界面则安装成功(自定义目录最终还是会下载在C盘):
3、安装CUDA对应的cuDNN(下载页会显示对应关系)
cuda使用说明
下载前需要先注册账号,完成后执行如下操作(其实就是将cudnn文件夹下的文件复制到cuda对应目录下)
将
将
将
4、下载opencv(OpenCV 2.x.x 或者 OpenCV <= 3.4.0)
官网下载速度极慢,此处在如下网址下载:https://zh.osdn.net/projects/sfnet_opencvlibrary/releases/
选择需要的版本下载即可,此处使用opencv-3.4.0-vc14_vc15.exe,不能高于此版本。下载后运行,选择提取目录,opencv将会被提取到该目录:
接着配置opencv环境变量:
我的电脑--->属性--->高级系统设置--->高级--->环境变量--->系统变量--->path--->编辑
将OpenCV安装目录的bin目录添加进去
5、下载darknet并生成darknet.exe
下载地址:https://github.com/AlexeyAB/darknet
5.1、修改darknet.vcxproj文件
进入
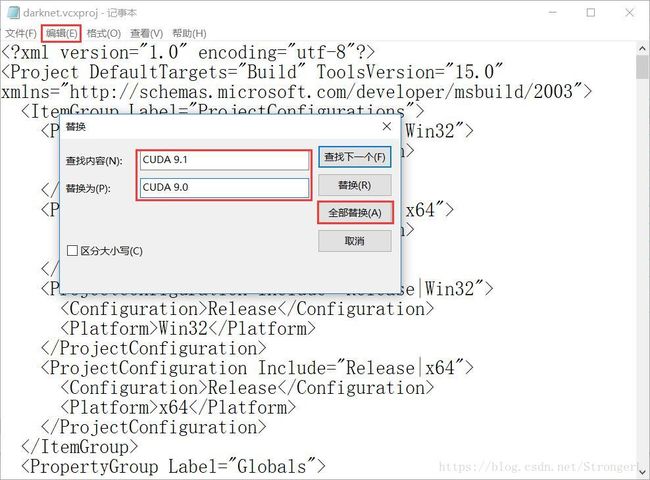
另外,还要将compute_75和sm_75分别改为compute_70和sm_70,因为cuda9.0不支持75。
5.2、进入\darknet-master\build\darknet中,没有GPU的打开darknet_no_gpu.sln,有GPU的打开darknet.sln。将项目修改为Release x64。如果是VS2017,需要重定向项目:右键项目-->重定向项目(不升级)
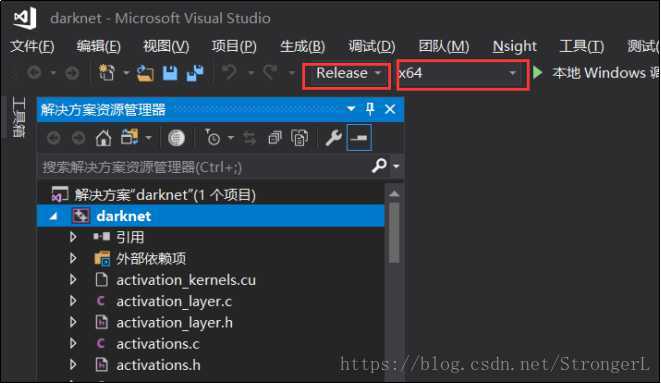
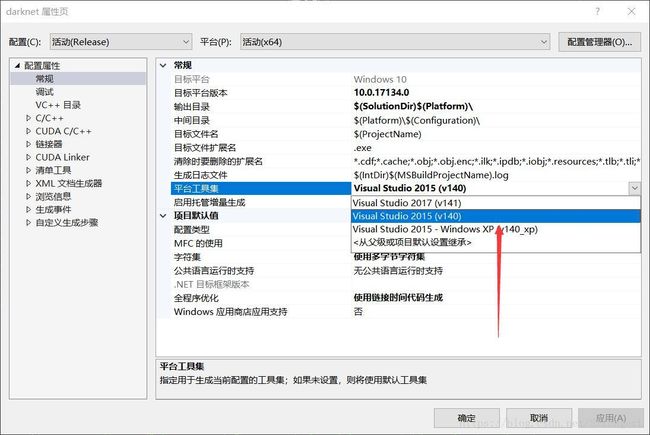
如果是VS2017,需要修改工具集(下载工具集过程见1.1),修改如下:右键项目-->属性:
5.3、配置包含目录 + 库目录 + 链接器(位置已经用红框框出)
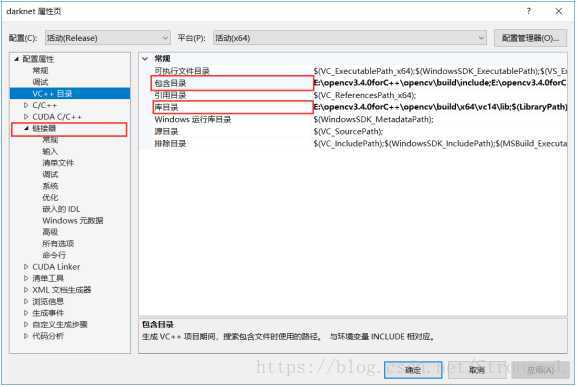
包含目录:在darknet项目上点击鼠标右键->属性,弹出如下界面:然后VC++目录-->包含目录-->编辑
添加的目录:...\opencv\build\include(...代表opencv的安装路径,下文同理)
...\opencv\build\include\opencv
...\opencv\build\include\opencv2
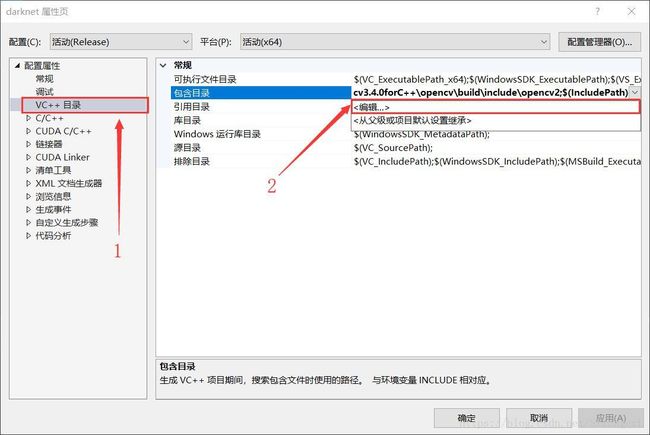
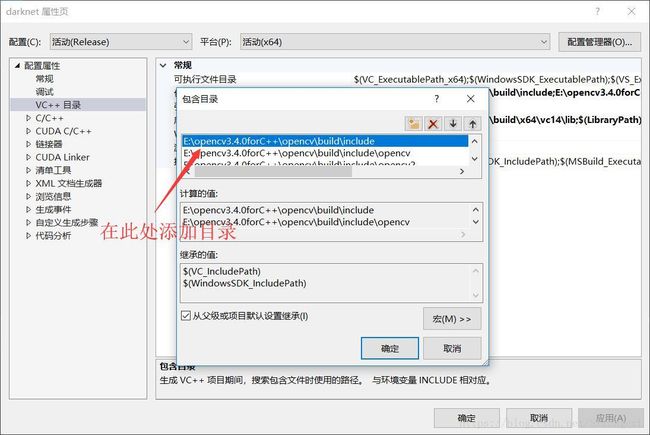
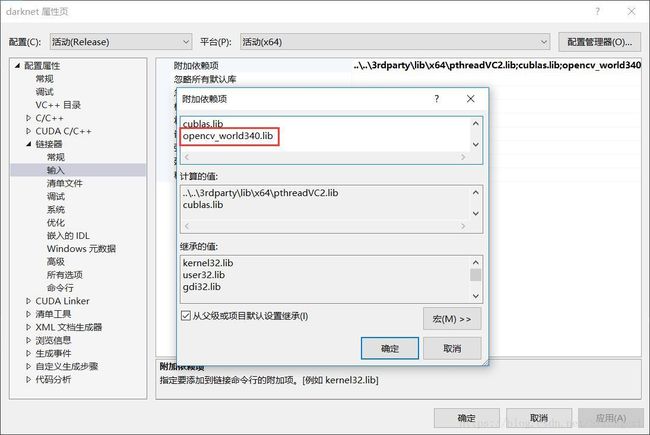
库目录:方法与包含目录类似,添加的目录为:...\opencv\build\x64\vc14\lib
链接器:添加目录...\opencv\build\x64\vc14\lib下库的名字:opencv_world341.lib
5.4、拷贝CUDA 9.0.props等文件:
CUDA 9.0.props 等文件就在cuda的安装目录下,本教程路径是:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0\extras\visual_studio_integration\MSBuildExtensions
拷贝所有文件到C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\v140\BuildCustomizations
如果直接输入路径无法找到,可以一步一步对照着找,因为可能有部分不太一样的地方。
右键项目,生成,成功后会生成一个darknet.exe在...\darknet-master\build\darknet\x64目录下,然后将..\opencv\build\x64\vc14\bin下的opencv_world340.dll 和opencv_ffmpeg340_64.dll 复制到 darknet.exe的同级别目录下。
做完上述步骤之后,可以测试下环境是否搭建成功:
在github上下载作者训练好的模型,网址:https://github.com/AlexeyAB/darknet/blob/master/README.md
懒的话直接点这里下载https://pjreddie.com/media/files/yolov3.weights
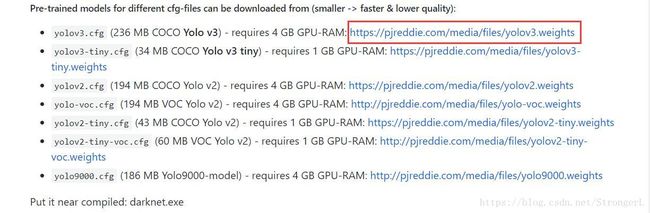
下载后放在darknet-master\build\darknet\x64下,打开该目录,双击darknet_yolo_v3.cmd会出现以下结果,表明成功编译。
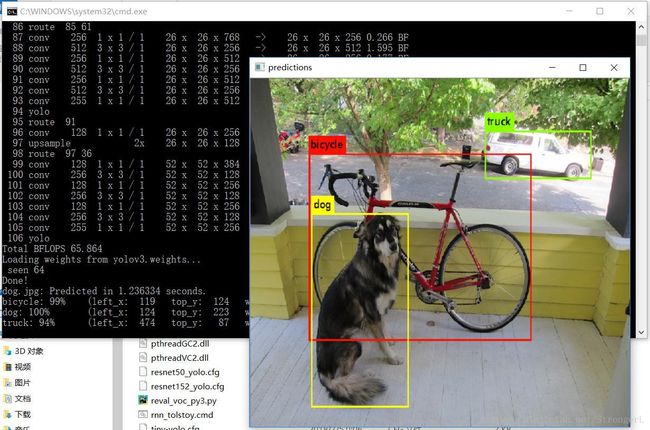
二、用YOLO v3训练自己的数据
1、制作自己的数据集
1.1、框图
首先准备好自己的图片,然后框图打标签,使用方法非常简单,打开你就会用了。
链接:https://pan.baidu.com/s/12uFzIisR1WBuf7286hyA-Q
提取码:85s6
1.2、把xml文件转化为txt
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
classes = ["person","cat"]#这里是你的所有分类的名称
myRoot = r'C:\Users\Desktop\myyolov3\mytrain'#这里是你项目的根目录
xmlRoot = myRoot +r'\Annotations'
txtRoot = myRoot + r'\labels'
imageRoot = myRoot + r'\JPEGImages'
def getFile_name(file_dir):
L=[]
for root, dirs, files in os.walk(file_dir):
print(files)
for file in files:
if os.path.splitext(file)[1] == '.jpg':
L.append(os.path.splitext(file)[0]) #L.append(os.path.join(root, file))
return L
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open(xmlRoot + '\\%s.xml' % (image_id))
out_file = open(txtRoot + '\\%s.txt' % (image_id), 'w') # 生成txt格式文件
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
#image_ids_train = open('D:/darknet-master/scripts/VOCdevkit/voc/list.txt').read().strip().split('\',\'') # list格式只有000000 000001
image_ids_train = getFile_name(imageRoot)
# image_ids_val = open('/home/*****/darknet/scripts/VOCdevkit/voc/list').read().strip().split()
list_file_train = open(myRoot +r'\ImageSets\Main\train.txt', 'w')
#list_file_val = open('boat_val.txt', 'w')
for image_id in image_ids_train:
list_file_train.write(imageRoot + '\\%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file_train.close() # 只生成训练集,自己根据自己情况决定
# for image_id in image_ids_val:
# list_file_val.write('/home/*****/darknet/boat_detect/images/%s.jpg\n'%(image_id))
# convert_annotation(image_id)
# list_file_val.close()
2、修改配置文件
项目根目录如下:
已经放在我的github上https://github.com/kk123k/myYOLOv3
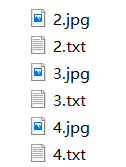
2.1、把所有的样本图片和对应的txt文件放到:darknet-master\build\darknet\x64\data\obj\下面,一张图对应一个txt。
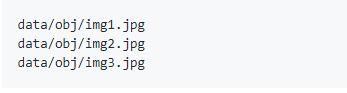
2.2、在darknet-master\build\darknet\x64\data\下新建train.txt
把训练图片的路径写在文件里面,每行一个路径,如图
当然,也可以写绝对路径。
刚刚上面的代码也已经包含了自动写入train.txt(执行前先在myRoot\ImageSets\Main\下新建一个train.txt)
2.3、将darknet的预训练权重放入darknet-master\build\darknet\x64
链接:https://pan.baidu.com/s/1Gdo2gj1bggjUtW9CyYkIpQ 密码:x5ht
2.4、在darknet-master\build\darknet\x64 新建yolo-obj.cfg文件(可以直接复制yolov3.cfg,然后重命名为yolo-obj.cfg)
修改这个文件内容:
batch 改成64 :batch=64
subdivisions 改成8 :subdivisions=8
训练的时候如果出现内存溢出错误(Out of memory),可以,将batch改小些(64,32,16,8),将random改成0关闭多尺度训练。
查找每个yolo下(共有3处)的classes改成你自己的类的数量 :classes = N
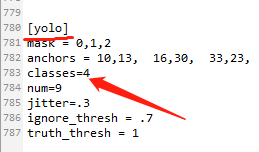
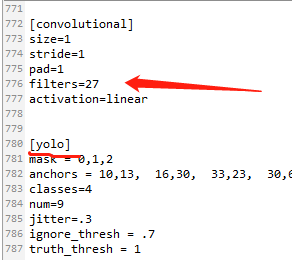
查找每个yolo上面第一个convolutional下的filters(如图)改成你自己的大小,计算方法是: filters=(classes + 5)x3 ,由于我的是4类,所以我的filters=27. (这个也是只有3处)
2.5、在darknet-master\build\darknet\x64\data\下新建obj.names文件,里面写入你的要检测的分类的类名,每个类名占一行。
2.6、在darknet-master\build\darknet\x64\data\下新建obj.data文件,像这样

2.7、修改网络配置文件Makefile(在\darknet-master路径下)

3、开始训练
Win+R打开终端,cd进入darknet-master\build\darknet\x64路径,下面命令开始训练:
darknet.exe detector train data/obj.data yolo-obj.cfg darknet53.conv.74
训练时,每训练100轮,都会生成一个权重文件在build\darknet\x64\backup\ 下,文件名例如:yolo-obj_100.weights(后面的100是训练100轮是的权重)。
如果训练的时候IOU出现全是-nan(ind),这应该是你的数据集有问题了,仔细检查下图片或txt文件的路径有没有写对或放对。可以在labels下放置图片标签txt文件试试。
4、测试
输入:同意cd进入darknet-master\build\darknet\x64路径,然后输入
darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_100.weights(最后的权重改为自己的权重)。
然后终端会提醒你输入图片路径,然后你输入测试图片的绝对路径即可看到效果。
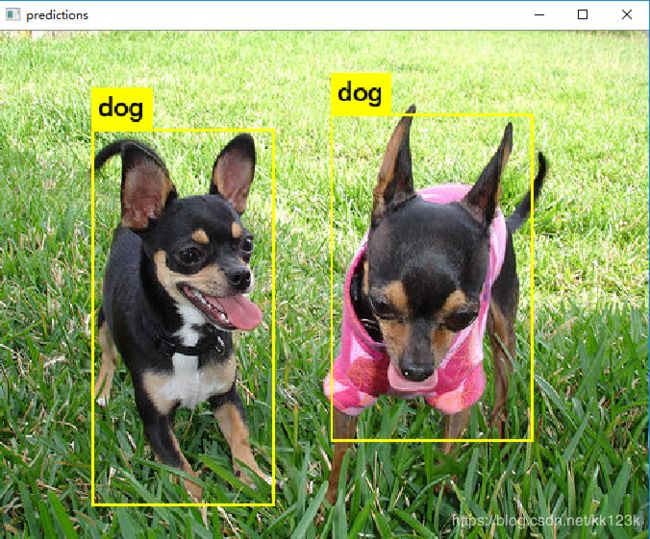
参考:
https://blog.csdn.net/StrongerL/article/details/81007766
https://blog.csdn.net/Yvette_Lucifer/article/details/82999061