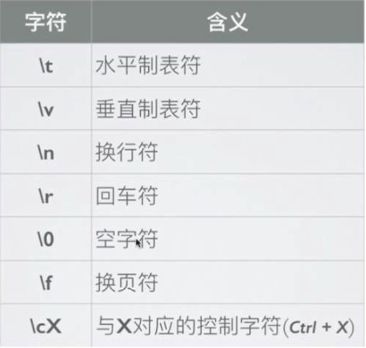
正则表达式中字符分类:
- 原意文本字符: 表达字符本身含义的字符,如a,b,c,1,2,3...
- 元字符: 有特殊含义的非字母字符,如 . + ? * | \ [] () {}...
元字符:
- 字符类: [],将 [] 中的内容归为一类,表示‘其中之一’,如 [abc]表示匹配a或者b或者c
'a1b2c3d478'.replace(/[abc]/g,'X'); // "X1X2X3d478"
- 反向字符类: [^],字符类取反,表示 ‘不是其中之一’, 如 [^abc]表示匹配除abc以外的内容
'a1b2c3d478'.replace(/[^abc]/g,'X'); // "aXbXcXXXXX"
- 范围类:[a-z]表示a到z之间的任意字符,[0-9]表示0到9,共10个数字……
'a1b2c3d4A-B-C-D567'.replace(/[a-zA-Z]/g, 'X'); // "X1X2X3X4X-X-X-X567"
'a1b2c3d4A-B-C-D567'.replace(/[a-z-]/g, '$'); // "$1$2$3$4A$B$C$D567"
- 预定义类

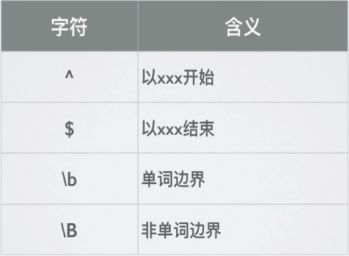
- 边界字符
'He is a boy,This is a toy,Is she?'.replace(/is/g, '0');
// "He 0 a boy,Th0 0 a toy,Is she?"
'He is a boy,This is a toy,Is she?'.replace(/\bis\b/g, '0');
// "He 0 a boy,This 0 a toy,Is she?"
'He is a boy,This is a toy,Is she?'.replace(/\Bis\b/g, '0');
"He is a boy,Th0 is a toy,Is she?"
'@123@456@'.replace(/@./g, 'X');
// "X23X56@"
'@123@456@'.replace(/^@./g, 'X');
// "X23@456@"
'@123@456@'.replace(/.@/g, 'X');
// "@12X45X"
'@123@456@'.replace(/.@$/g, 'X');
// "@123@45X"
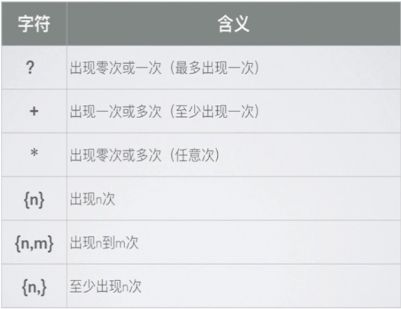
- 量词
贪婪模式:
JavaScript中的正则会尽可能多的匹配,知道匹配失败,称之为贪婪模式。例如:
'12345678'.replace(/\d{3,6}/g, 'X'); // "X78"
上面的例子中,要匹配3 - 6个数字,12345678有可能被匹配到123, 1234,12345, 123456,实际上,JavaScript采用贪婪模式,总是按照能匹配到的最多字符的模式进行匹配。
相应的,如果想采用非贪婪模式,只需在量词后面加 ? 即可,如:
'12345678'.replace(/\d{3,6}?/g, 'X'); // "XX78"
在非贪婪模式下,JavaScript尽可能少的匹配,一旦有匹配成功,则马上停止,不会继续尝试匹配,上面的例子中,在可以是匹配3个,4个,5个,6个数字的情况下,JavaScript只会去匹配3个数字的情况,先匹配到‘123’,替换为‘X’,继续匹配到‘456’,替换为‘X’,接着匹配‘78’,发现匹配失败,所以最终返回 ‘XX78’
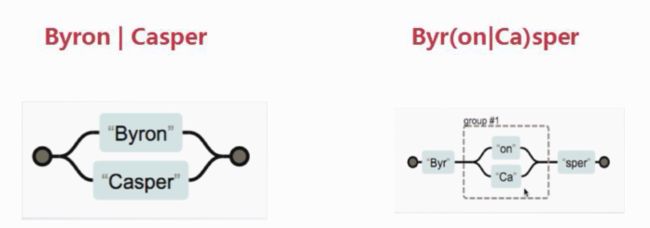
分组:
使用()可以起到分组的作用,使量词作用于分组,如 :
/(luichooy){3}/g // 表示匹配 luichooy 3次
/luichooy{3}/g // 表示匹配字母 y 3次
- 反向引用: $1,$2,$3……
// 将2018-03-30 转为 03/30/0218
'2018-03-30'.replace(/(\d{4})-(\d{2})-(\d{2})/g, '$2/$3/$1');
// "03/30/2018"
- 忽略分组:只需在分组内加上 ?: 就可以了,JavaScript不会捕获分组内的内容
// 将2018-03-30 转为 03/30
'2018-03-30'.replace(/(?:\d{4})-(\d{2})-(\d{2})/g, '$1/$2');
// "03/30"
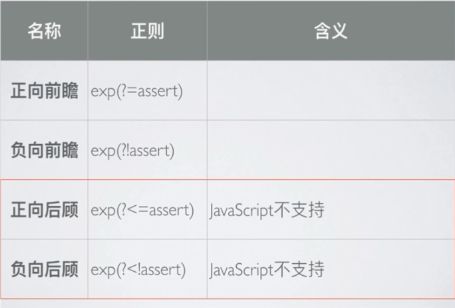
前瞻和后顾:
正则表达式从文本头部向文本尾部开始解析,所以文本尾部叫做前,文本头部叫做后。
前瞻就是正则表达式在匹配到规则的时候,向前检查是否符合断言;
后顾方向相反。
通俗的说:
前瞻即匹配到某个字符的时候,还要看它前面的内容是否符合某个规则,如:当查找一个小数的时候,当匹配到小数点的时候,还要看看小数点后面是不是还有数字;
后顾即匹配到某个字符的时候,还要看它口面的内容是否符合某个规则,如:当查找一个小数的时候,当匹配到小数点的时候,还要看小数点前面是否有数字;
JavaScript不支持后顾
符合某个断言称为正向(积极)匹配
不符合某个断言称为负向(否定)匹配
'f45dsf46f'.replace(/\w(?=\d)/g, 'X');
// "XX5dsXX6f"
'f45dsf46f'.replace(/\w(?!\d)/g, 'X');
// "f4XXXf4XX"
正则对象属性:
- global 是否全文搜索,默认false
- ignoreCase 是否大小写敏感,默认false
- multiline 是否多行搜索,默认false
- lastIndex 当前表达式匹配内容的最后一个字符的下一个位置
- source 正则表达式的文本字符串
正则对象的方法:
- RegExp.prototpe.test(str) 是否匹配,返回值为 Boolean
- RegExp.prototpe.exec(str) 匹配失败,返回null,匹配成功,返回结果数组
字符串对象的方法:
String.prototype.search(str | RegExp)
在字符串中检索参数指定的子字符串或者与正则匹配的子字符串
如果检索到了,返回第一个匹配结果的index,否则返回-1
seach方法不执行全局搜索,并且会忽略正则中的g标志,并且总是从字符串的开始进行检索String.prototype.match(str | RegExp)
在字符串中检索参数指定的子字符串或者正则匹配的子字符串
有没有g标志对结果影响很大
没有匹配到返回null,匹配到则返回一个数组,该数组中存放了与匹配到的文本相关的内容String.prototype.split(str | RegExp)
String.prototype.replace(str | RegExp,str | function)
'a1b2c3d4'.replace(/\d/g,function(match,index,source){
console.log(index); // 1 3 5 7
return parseInt(match) + 1;
});
// "a2b3c4d5"
'a1b2c3d4e5'.replace(/(\d)(\w)(\d)/g,function(match,group1,group2,group3,index,source){
console.log(index); // 1 5
return group1 + group3;
});
// "a12c34e5"