【读书笔记】概率图模型——基于R语言(三)
文章目录
- 第三章:学习参数
- 通过推断学习
- 极大似然法
- 经验分布和模型分布是怎么关联的?
- 最大似然法R语言实现
第三章:学习参数
本章的所有例子基于条件独立假设(iid)
构建概率图模型大致需要3个步骤:
- 定义随机变量,即图中节点
- 定义图的结构
- 定义每个局部分布的数值参数
设D为数据集,θ为图模型的参数,似然函数为 P ( D ∣ θ ) P(D|θ) P(D∣θ),即给定参数下观测数据集的概率,那么最大似然估计就是要找出参数θ。可以写作 θ ~ = a r g m a x θ P ( D ∣ θ ) \tilde{\theta}=argmax_{\theta}P(D|\theta) θ~=argmaxθP(D∣θ)
如果想要更准确地刻画θ,可以采用贝叶斯方法,这里需要知道参数的先验分布P(θ)。在这个例子中,在这个例子中就是找出 P ( D ∣ θ ) P ( θ ) P(D|\theta)P(\theta) P(D∣θ)P(θ)的最大值。这个过程叫做最大化后验概率
一个鸢尾花的例子:
x = read.csv("https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data", col.names = c("sepal_length", "sepal_width", "petal_length", "petal_width", "class"))
head(x)
mean(x$sepal_length)
var(x$sepal_length)
# 这个包是对R语言的data.frame数据结构进行Split - Apply - Combine操作
library(plyr)
# 每一类所占的比例,算是给出了一个先验吧
y = daply(x, .(class), nrow) / nrow(x)
y
daply(x, .(class), function(n) mean(n$sepal_length))
daply(x, .(class), function(n) var(n$sepal_length))
# 可以进行离散化
# 求分位数
# 0到1,间隔是0.33
q <-quantile(x$sepal_length, seq(0, 1, 0.33))
x$dsw[ x$sepal_length < q['33%']] = "small"
x$dsw[ x$sepal_length >= q['33%'] & x$sepal_length <= q['66%']] = "medium"
x$dsw[ x$sepal_length > q['66%']] = "large"
# 求条件概率分布
p1 <-daply(x, .(dsw, class), function(n) nrow(n))
p1
p1 <-p1/colSums(p1)
p1
结果:
> y
Iris-setosa Iris-versicolor Iris-virginica
0.3288591 0.3355705 0.3355705
> daply(x, .(class), function(n) mean(n$sepal_length))
Iris-setosa Iris-versicolor Iris-virginica
5.004082 5.936000 6.588000
> daply(x, .(class), function(n) var(n$sepal_length))
Iris-setosa Iris-versicolor Iris-virginica
0.1266497 0.2664327 0.4043429
> # 求条件概率分布
> p1 <-daply(x, .(dsw, class), function(n) nrow(n))
> p1
class
dsw Iris-setosa Iris-versicolor Iris-virginica
large NA 14 37
medium 10 31 12
small 39 5 1
> p1 <-p1/colSums(p1)
> p1
class
dsw Iris-setosa Iris-versicolor Iris-virginica
large NA NA NA
medium 0.20 0.62 0.24
small 0.78 0.10 0.02
通过推断学习
我们还是以一个投硬币的模型作为例子θ是正面向上的概率
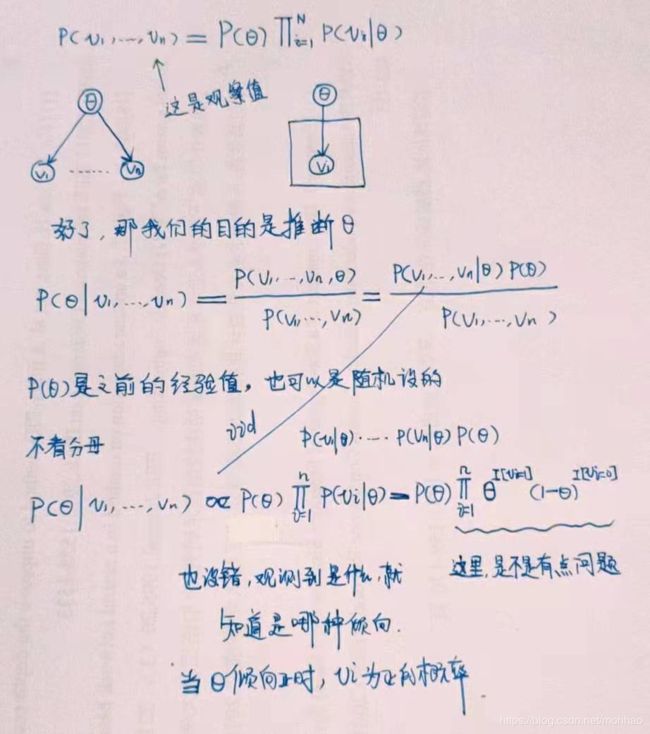
上述贝叶斯推断的程序如下:
# 正面的概率0.2、0.5、0.8(正面不公平、正面公平、反面不公平)
posterior <-function(prob, num_head, num_tail, Theta = c(0.2, 0.5, 0.8)){
x = numeric(3)
for(i in 1:3)
# x[i] = prob[i] * (Theta[i] ^ num_head)((1 - Theta[i]) ^ num_tail)
x[i] = exp(log(prob[i]) + log(Theta[i] ^ num_head) + log((1 - Theta[i]) ^ num_tail))
norm = sum(x)
return(x/norm)
}
# (正面不公平、正面公平、反面不公平)的概率,2+8=10次试验
posterior(c(0.2, 0.75, 0.05), 2, 8)
posterior(c(0.2, 0.75, 0.05), 10, 10)
posterior(c(1/3, 1/3, 1/3), 2, 8)
结果如下,注意不同先验概率与参数更新以后的后验概率的变化:
> posterior(c(0.2, 0.75, 0.05), 2, 8)
[1] 6.469319e-01 3.530287e-01 3.948559e-05
> posterior(c(0.2, 0.75, 0.05), 10, 10)
[1] 0.0030626872 0.9961716410 0.0007656718
> posterior(c(1/3, 1/3, 1/3), 2, 8)
[1] 0.8727806225 0.1270062963 0.0002130812
极大似然法
经验分布和模型分布是怎么关联的?
正确的推导应该是这个:
最大似然法R语言实现
先搞个图:
library(graph)
library(Rgraphviz)
library(plyr)
data0 <-data.frame(
x = c("a","a","a","a","b","b","b","b"),
y = c("t","t","u","u","t","t","u","u"),
z = c("c","d","c","d","c","d","c","d")
)
edges0 <-list(x=list(edges=2), y=list(edges=3), z=list())
g0 <-graphNEL(nodes = names(data0), edgeL = edges0, edgemode = "directed")
plot(g0)
data1 <-read.csv("http://archive.ics.uci.edu/ml/machine-learning-databases/nursery/nursery.data",col.names = c("parents", "has_nurs", "form", "children", "housing", "finance", "social", "health", "class"))
edges1 <-list(parents = list(), has_nurs = list(), form = list(), children = list(), housing = list(), finance = list(), social = list(), health = list(), class = list(edges=1:8))
g1 <-graphNEL(nodes = names(data1), edgeL = edges1, edgemode = "directed")
plot(g1)
会画出来两个图,这里给出一个:
