19[NLP训练营]信息抽取Information Extraction
文章目录
- 信息抽取概要
- Extract Information from Unstructured Text
- Information Extraction(IE)
- 信息抽取应用场景Information Extraction Application
- Extract Key Intormation抽取关键信息
- More Applications
- 命名实体识别介绍Named Entity Recognition
- Case: chat bot
- Case: Extract from News
- Case:Resume Analysis
- 常用工具
- 搭建命名实体识别分类器Create NER Recognizer
- NER方法概述
- 基于规则的方法Rule-based Approach
- 投票模型(Majority Voting)
- Simple Feature Engineering for Supervised Learning
- 特征编码feature encoding
- 关系抽取介绍
- 常见的实体关系:
- 基于规则的方法以提取IS-A为例
- 基于监督学习方法
- Bootstrap方法
- Bootstrap优缺点
- Snowball
- Snowball简介
- Snowball具体算法
- 规则相似度计算
- 规则(模板pattern)的合并
- 生成tuple
- 模板评估
- 记录评估(tuple evaluation)与过滤
- snowball总结
- Distant-supervision方法
- 无(半)监督学习
- 实体消歧Entity Disambiguiation
- 实体统一
- 例子:基于图的实体统一
- 指代消解Co-reference Resolution
- 句法分析Parsing
- 句法树中提取特征Parsing for Feature Extraction
- 给定语法,写出语法树和句子
- 例子:old MT
- From CFG to PCFG
- evaluate syntax tree
- Find the Best Syntax Tree
- CKY算法
- Intuition about CKY Algorithm
- Transforming to CNF(Chomsky Normal Form)
- 1.remove e
- 2.Remove unaries
- remove trinaries
- CKY Algorithm
公式输入请参考: 在线Latex公式
信息抽取概要
Extract Information from Unstructured Text
Unstructured Text包括:
1、图片
2、文本
3、VIDEO
4、音频
这些需要提取特征的处理后才能用模型进行计算。
Information Extraction(IE)
抽取实体(entities):实体是现实生活中存在的事物。
·人(person),地名(location),时间(time)
·医疗领域:蛋白质,疾病,药物.…
·金融领域:申请人,申请表,公司,地址…
可以看出各个垂直领域上有非常鲜明的特点,不能直接用开源的NER来抽取。
抽取关系)(relations)
·位于((locatedin),工作在(work at),部分(is part of)
例子:
文本:张三毕业于北京大学,目前在北京工作。
![19[NLP训练营]信息抽取Information Extraction_第1张图片](http://img.e-com-net.com/image/info8/dda90136dbdb42b4b2d061a52cb24762.jpg)
工业上,通常会把上面的知识图谱加入属性,变成属性图(property graph)
信息抽取应用场景Information Extraction Application
例子:
This hotel is my favorite Hinton Property in NYC! It is located right on 42nd street near Times Square in New York, it is close to all subways, Broadways shows, and next to great restaurants like Junior’s Cheesecake, Virgil’s BBQ and many others.
第一步,抽取实体NER,包括:
hotel
Hinton Property
NYC
42nd street
Times Square
New York
Broadways shows
Junior’s Cheesecake
Virgil’s BBQ
然后标注每个实体的类型:
hotel:ORG
Hinton Property:ORG
NYC:LOC
42nd street:LOC
Times Square:LOC
New York:LOC
Broadways shows:EVENT
Junior’s Cheesecake:RES
Virgil’s BBQ:RES
第二步:关系抽取:
![19[NLP训练营]信息抽取Information Extraction_第2张图片](http://img.e-com-net.com/image/info8/dab0c296a47e40798c39f9d2fbe3a8d3.jpg)
关系抽取一般都只会循环整篇文章抽取某一种关系(如: is a),而不是所有的关系。
注意抽取过程中还会有指代消解,例如:It is located right on 42nd street near Times Square in New York.中的it是指什么?This hotel ?Hinton Property?NYC?用分类的方法找到这个it的对应对象就是指代消解。
当然还有:实体消歧和实体统一算法(后面有具体介绍)
实体消歧是指一词多义的情况,如何确定具体是哪个意思。例如:apple是苹果还是苹果公司。
实体统一是把同一个实体存在不同名称的情况,例如这里的NYC和New York是一样的。另外谷歌学术在中国人作者姓名的实体统一上也做得很好,当然文章的作者应该比较好处理,毕竟还有单位嘛。

![19[NLP训练营]信息抽取Information Extraction_第3张图片](http://img.e-com-net.com/image/info8/adb5525a87df4043a5a199bb4a1b8daa.jpg)
Extract Key Intormation抽取关键信息
和文本摘要有一点点类似。
More Applications
·知识库的搭建
·Google Scholar,CiteSeerX
·用户库:Rapleaf,Spoke
·购物引擎,产品搜索
·专利分析·证券分析
·问答案系统
·简历分析
命名实体识别介绍Named Entity Recognition
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。-来自“百度知道”
Case: chat bot
根据提问进行意图识别,然后是分类,看意图是什么,问地点,时间?还是什么东西,然后是基于规则进行回答,规则做不了的才会用到其他解决方案。
Case: Extract from News
例如:
斯坦福全球AI报告:人才需求两年暴增35倍,中国机器人部署量涨500%。刚刚,斯坦福全球Al报告正式发布。从去年开始,斯坦福大学主导、来自MIT、OpenAl、哈佛、麦肯锡等机构的多位专家教授,组建了一个小组,每年发布Al index年度报告,全面追踪人工智能的发展现状和趋势。“我们用硬数据说话。”报告的负责人、斯坦福大学教授、前任谷歌首席科学家Yoav Shoham谈到这份最新的报告时表示。今年的报告,从学术,工业、开源、政府等方面详细介绍了人工智能发展的现状,并且记录了计算机视觉、自然语言理解等领域的技术进展。
提取后:
产品名:Al Index
组织:斯坦福,MIT,OpenAl,哈佛
公司:麦肯锡,谷歌
人物:Yoav Shoham
也可以自己试试:boson
Case:Resume Analysis
常用工具
English Toolkits
·NLTK NE
·Spacy
·Stanford Parser
Chinese Toolkits
·HanNLP
·HIT NLP
·Fudan NLP
·or yours…
以上工具的缺点是无法进行特定领域的实体识别,例如:医疗、金融等。只能做通用的:人物、时间、事件等。
搭建命名实体识别分类器Create NER Recognizer
·定义实体种类,主要是创建实体的列表
·准备训练数据
下面是一个训练数据的实例,第一列是句子及编号,第二列是词,第三列是词的词性标注,第四列是标注是否我们需要关注的词,不关注标记为O,否则标记为《B-类型》的标签例如:B-geo代表地点,B-per代表人。
![19[NLP训练营]信息抽取Information Extraction_第4张图片](http://img.e-com-net.com/image/info8/25a9dec7617440a8a10fa33b79b808e1.jpg)
如果有多个词组合成一个实体:
![19[NLP训练营]信息抽取Information Extraction_第5张图片](http://img.e-com-net.com/image/info8/8c07db1002eb44c69ab6672c3f44ef3b.jpg)
·训练NER
NER方法概述
利用规则(比如正则)
投票模型(Majority Voting):经常用做baseline
利用分类模型
·非时序模型:逻辑回归,SVM…
·时序模型:HMM,CRF,LSTM-CRF
基于规则的方法Rule-based Approach
例如有一个这样的实体:美国电话
规则可自己写正则表达式,这样定义:
(2:\(?[0-9]{3}\)?[0-9]{3][-.]?[0-9]{4}
也可以利用已有词库,直接匹配。
投票模型(Majority Voting)
统计每个单词的实体类型,记录针对于每个单词,概率最大的实体类型。
例如一个词:BeiJing,出现在4句话中,有三句话标注为geo,一句话标注为loc,根据概率就标注为geo。
这个方法经常用做baseline。
Simple Feature Engineering for Supervised Learning
提取每个单词的最简单的特征,比如单词长度等等。
例子:
The professor Colin proposed a model for NER in 1999.
对于单词Colin我们看有哪些提取特征的方法。
![19[NLP训练营]信息抽取Information Extraction_第6张图片](http://img.e-com-net.com/image/info8/fbedd075afcf425cb241d3bb2b741ea1.jpg)
这里trigram其实太适用,因为太短了。
![19[NLP训练营]信息抽取Information Extraction_第7张图片](http://img.e-com-net.com/image/info8/3fdc1cd9745646548b2f1a71082c642d.jpg)
![19[NLP训练营]信息抽取Information Extraction_第8张图片](http://img.e-com-net.com/image/info8/3da2eede91aa4aaaa827473205268803.jpg)
![19[NLP训练营]信息抽取Information Extraction_第9张图片](http://img.e-com-net.com/image/info8/a8b9522dfe924b8484a719a614738dca.jpg)
以上只是列举特征抽取的方法,并不保证这些特征就很好,要根据具体场景来选,或者用一些方法来进行筛选。
特征编码feature encoding
常见的特征种类有:
连续(continuous)特征;
无序类别(categorical)特征;
有序类别(ordinal)特征。
1、continuous feature
这里直接用有两种方式,一种是归一化后用,一种是转成搞屎分布后用
![19[NLP训练营]信息抽取Information Extraction_第10张图片](http://img.e-com-net.com/image/info8/c5a72d0e9b144d0d8dd2fa8a4dfc6e1c.jpg)
2、categorical feature
可以使用One-hot的方法把每个无序特征转化为一个数值向量。
![19[NLP训练营]信息抽取Information Extraction_第11张图片](http://img.e-com-net.com/image/info8/066cd6bd350b45839becd3edf4e0396a.jpg)
3、ordinal feature
有序类别的特征不能计算每个间隔之间的区别,例如成绩为ABCD
那么不能说A-B=C-D
但是如果用连续特征就可以:100,90,80,70
100-90=80-70表示前面两个学生和后面两个学生之间的差异大致相同。
有序类别的处理第一种就是直接用,第二种方法也是按无序类别的方法使用,用独热编码。
关系抽取介绍
常见的实体关系:
·IS-A(Hypernym Relation):代表的是从属关系,使用这个关系可以整理很多对象的分类。
·Instance-of:略
基于规则的方法以提取IS-A为例
先人工定义规则,例如:
![19[NLP训练营]信息抽取Information Extraction_第12张图片](http://img.e-com-net.com/image/info8/b3ab9b76dc324c69b3018e1b3717120f.jpg)
X和Y是什么东西?这个信息是保存在数据库的表中的,怎么保存?从文章中学习来
例如:apple is a fruit.
从这句话就可以学习到apple 是X,fruit是Y。
还有:car such as Honda.
等等,完了以后,数据库就变成:
| X | Y |
|---|---|
| apple | fruit |
| Honda | car |
等等。。。
我们定义的规则集越丰富,那么从文章中抽取到的信息也就越丰富。
当然这样简单规则集定义后的抽取会得到我们不需要的信息(噪音),例如我们只想知道有哪些水果,结果,把车子也抽取出来了,所以我们在定义规则集的时候可以加上一些限制。
例如:X (is a) Y[fruit].
这样的好处:
![19[NLP训练营]信息抽取Information Extraction_第13张图片](http://img.e-com-net.com/image/info8/ffabb25f6a354036910678e79df92dfb.jpg)
整个基于规则的方法优点:
1、比较准确
2、无需训练
随着数据量的增大,我们可以把基于规则的方法替换为基于模型的方法。
缺点:
1、low recall rate
2、人力成本高
3、规则比较难设计
基于监督学习方法
大概步骤:
1、定义关系类型,例如:疾病与症状的关系、疾病与药物的关系。
2、定义实体类型,例如:疾病、症状、药品
3、训练数据准备
3.1标记好实体及类型;
3.2标记好实体之间的关系。
和之前的NER有些类型,这里要抽取关系也可以转换为分类的问题,只不过之前的NER做分类是针对某个实体,分类目标是将实体归类为某种类型:如地点、人名。现在的关系抽取分类是针对两个实体的,分类目标是将两个实体之间关系归类为某种类型,例如:

可以看到,分类时和NER一样的,也要用到特征工程的方法。抽取关系的特征工程通常有如下方法:
1、bag of word
![19[NLP训练营]信息抽取Information Extraction_第14张图片](http://img.e-com-net.com/image/info8/5cf4248db19c4dbbbc0c860d5d78deee.jpg)
![19[NLP训练营]信息抽取Information Extraction_第15张图片](http://img.e-com-net.com/image/info8/cd4cc6b52ce74fe49076db698ccea5d3.jpg)
分类的搞法,如果要抽取的关系有k类,那么我们需要一个k+1的分类器,因为还有一种类别是无分类(意味两个对象没有关系)。分类算法可以有SVM,NN,GBDT等:
![19[NLP训练营]信息抽取Information Extraction_第16张图片](http://img.e-com-net.com/image/info8/a81edaf533fa4a45b03bf7228103aec8.jpg)
还有一种做法是先把无分类进行过滤(二分类问题),然后再进行分类:
![19[NLP训练营]信息抽取Information Extraction_第17张图片](http://img.e-com-net.com/image/info8/98055cf3715c428f94464555d2cfdefb.jpg)
Bootstrap方法
由于上面两种方法(基于规则和基于监督)在手工设置规则、标记实体上很麻烦,因此在这个方面做了改进。
Bootstrap大概步骤是这样:
先有已知的seed/seeds tuple
![19[NLP训练营]信息抽取Information Extraction_第18张图片](http://img.e-com-net.com/image/info8/97a4b301cf5041f6911db3cf59d56ca6.jpg)
明显这个是隐含了作者和书的关系。
下面第一步:生成规则
用上面的tuple去扫描文本,然后生成规则,具体如下图
![19[NLP训练营]信息抽取Information Extraction_第19张图片](http://img.e-com-net.com/image/info8/b88859c2556045f9bf513f61bd1673d7.jpg)
最后形成一个规则库:
X写了Y
Y是由X写的
第二步:规则库生成tuple
用上面的规则库去扫描文本,可以得到类似的结果:

这里面蕴含了三个新的tuple:
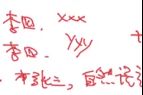
然后把新的tuple加入到之前的seed tuple中,再不断重复这个过程。
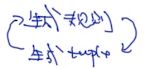
Bootstrap优缺点
优点:自动的方法,不需要太多的人工介入。
缺点:提取的规则可能准确率比较低,例如按上面的例子会提取到:
周志华在做机器学习的研究。-》X在做Y。
这个规则不是作者和书的关系。
这样的缺点但凡是迭代式的算法都有,称为:error accumulation,下面左边是准确率
![19[NLP训练营]信息抽取Information Extraction_第20张图片](http://img.e-com-net.com/image/info8/557a6cef16894dc0b39c466704a2cbf3.jpg)
Snowball
Snowball简介
这个算法是在Bootstrap上的改进。
![19[NLP训练营]信息抽取Information Extraction_第21张图片](http://img.e-com-net.com/image/info8/865cb18febe74ee282bc9b011e1c359c.jpg)
加了两个过滤的步骤
另外在规则匹配上:
![19[NLP训练营]信息抽取Information Extraction_第22张图片](http://img.e-com-net.com/image/info8/7c5b3f4900aa4b56aaf8d1612ece2c40.jpg)
左边是原来的Bootstrap匹配方法。右边是snowball的匹配方法。
这种匹配方法可以计算如下的相似度:

Snowball具体算法
和boottrap一样,先有seed tuple:
![19[NLP训练营]信息抽取Information Extraction_第23张图片](http://img.e-com-net.com/image/info8/e3916de47d0e43109e1d2d9b5186c269.jpg)
然后扫描文本:
![19[NLP训练营]信息抽取Information Extraction_第24张图片](http://img.e-com-net.com/image/info8/5133df014e77439a988841bd15e4d581.jpg)
然后提取规则,这里规则说了和boottrap不一样,这里用的是五元组的方式
如果我们采用的长度为2,那么以第一句话为例:
![19[NLP训练营]信息抽取Information Extraction_第25张图片](http://img.e-com-net.com/image/info8/fb6293330f51404cb0272aaeb36464bb.jpg)
长度为2代表分别往前和往后取2个词,上例中往后没有词,所以是空的,然后把前中后分别命名后转换为向量(用类似TFIDF之类的方法),这样每个规则之间就可以用向量来进行计算。
最后的规则就是这个样子:
![]()
规则相似度计算
假设我们有两个规则(从这里开始规则也叫模板pattern)
P = < L 1 , T 1 , M 1 , T 2 , R 1 > P=
S = < L 2 , T 1 ′ , M 2 , T 2 ′ , R 2 > S=
上面是五元组中LMR是向量,T都是实体标签例如:ORG,LOC等。
计算相似度 s i m ( P , S ) sim(P,S) sim(P,S)
如果 T 1 ≠ T 1 ′ o r T 2 ≠ T 2 ′ T_1\neq T_1'\space or\space T_2\neq T_2' T1=T1′ or T2=T2′那么 s i m ( P , S ) = 0 sim(P,S)=0 sim(P,S)=0
否则:
s i m ( P , S ) = μ 1 L 1 ⋅ L 2 + μ 2 M 1 ⋅ M 2 + μ 3 R 1 ⋅ R 2 μ 1 + μ 2 + μ 3 = 1 sim(P,S)=\mu_1L_1\cdot L_2+\mu_2M_1\cdot M_2+\mu_3R_1\cdot R_2\\ \mu_1+\mu_2+\mu_3=1 sim(P,S)=μ1L1⋅L2+μ2M1⋅M2+μ3R1⋅R2μ1+μ2+μ3=1
μ \mu μ是相似度计算的权重,原论文中中间的权重大,两边权重小: μ 1 = μ 3 = 0.2 , μ 2 = 0.6 \mu_1=\mu_3=0.2,\mu_2=0.6 μ1=μ3=0.2,μ2=0.6
下面接前面的数据看具体例子:
![19[NLP训练营]信息抽取Information Extraction_第26张图片](http://img.e-com-net.com/image/info8/7208840e112e45b08f410e32fd229736.jpg)
注意这里前中后的向量长度都是词库V的长度。
后面那个数字是每个词在向量中的权重,1个词是1,2个词每个是0.75,三个词每个词是0.57
因为他们的平方加起来要等于1.
![19[NLP训练营]信息抽取Information Extraction_第27张图片](http://img.e-com-net.com/image/info8/bed5f61884e74536b15eb0e8c65c9289.jpg)
规则(模板pattern)的合并
相似度计算后,就可以进行规则(模板pattern)的合并了,就是把相似度大的合并起来,使用的就是聚类cluster的方法。
第一步:
用聚类算法对规则(模板pattern)进行合并,常用的算法有:
![19[NLP训练营]信息抽取Information Extraction_第28张图片](http://img.e-com-net.com/image/info8/cfe74566277f4956b5418ea84160b995.jpg)
原论文采用的是逐个比较相似度,如果相似就合并到一起的思路,看图就懂了:
![19[NLP训练营]信息抽取Information Extraction_第29张图片](http://img.e-com-net.com/image/info8/40f182f5716a43a5b2d76f8b582ad297.jpg)
第二步:
把多个规则在一组的进行平均操作(centroid),变成一个规则。
![19[NLP训练营]信息抽取Information Extraction_第30张图片](http://img.e-com-net.com/image/info8/ef16f6f34de84efda73d19757994ff1c.jpg)
生成tuple
有了规则库,就可以生成tuple了:
如下图所示,先扫描文本,用NER找到实体类型要和模板中的一样的,这里是ORG和LOC,然后把发现的抽成五元组和规则库里面的各个规则进行相似度计算,如果大于0.7,那么说明我们扫描到了正确的tuple,加入到下面的表中。
![19[NLP训练营]信息抽取Information Extraction_第31张图片](http://img.e-com-net.com/image/info8/bf98d30f3d384cac9a529b270c3a6c3a.jpg)
模板评估
然后是对模板进行评估,把之前迭代生成的seed tuple作为groud truth。
然后把某条规则(模板)应用到文本上,然后检测出一系列的tuples结果(最下面的表)
然后把结果与groud truth进行比对,计算confidence score。
例子中错1个,对2个,一个没有出现过的忽略掉。
最后根据confidence来判断模板 P i P_i Pi是否要丢弃。
![19[NLP训练营]信息抽取Information Extraction_第32张图片](http://img.e-com-net.com/image/info8/39c823ef0d9c492dba48aa5bb19818b1.jpg)
记录评估(tuple evaluation)与过滤
根据上一步的计算得到每个模板的confidence值要大于某个阈值(上面是0.5,下面的例子用的0.7)得到对应的tuple:
![19[NLP训练营]信息抽取Information Extraction_第33张图片](http://img.e-com-net.com/image/info8/876449ccd25b470096c13b84f55b9fc7.jpg)
把上面的右边的seed tuples记录从上到下记作:tuple1,tuple2,tuple3,tuple4。
从上面可以直接看出来,他们之间的可靠性比较:
tuple1>tuple2:因为生成tuple1的pattern更加reliable(0.8>0.75)。
tuple4>tuple3:因为生成tuple4的pattern更加多。
把上面的事情用数学的方式来表达,新的表达我们叫tuple的confidence score(前面那个是规则的confidence score,注意区别),这个东西越大越好:
c o n f i d e n c e ( t i ) = 1 − ∏ i = 1 k ( 1 − c o n f i d e n c e ( p i ) ) confidence(t_i)=1-\prod_{i=1}^k(1-confidence(p_i)) confidence(ti)=1−i=1∏k(1−confidence(pi))
上式中的后面那项,如果满足的规则越多,这项的乘积就越小。例如:
c o n f i d e n c e ( t 2 ) = 1 − ( 1 − c o n f i d e n c e ( p 2 ) ) = 1 − ( 1 − 0.75 ) = 0.75 confidence(t_2)=1-(1-confidence(p_2))=1-(1-0.75)=0.75 confidence(t2)=1−(1−confidence(p2))=1−(1−0.75)=0.75
c o n f i d e n c e ( t 3 ) = 1 − ( 1 − c o n f i d e n c e ( p 2 ) ) ( 1 − c o n f i d e n c e ( p 3 ) ) = 1 − ( 1 − 0.75 ) ( 1 − 0.81 ) ≈ 0.95 confidence(t_3)=1-(1-confidence(p_2))(1-confidence(p_3))\\=1-(1-0.75)(1-0.81)≈0.95 confidence(t3)=1−(1−confidence(p2))(1−confidence(p3))=1−(1−0.75)(1−0.81)≈0.95
同样,我们也可以设置tuple的confidence score的阈值为0.7来进行过滤
snowball总结
![19[NLP训练营]信息抽取Information Extraction_第34张图片](http://img.e-com-net.com/image/info8/243d3ee97787453ca378307ba8730528.jpg)
Distant-supervision方法
无(半)监督学习
实体消歧Entity Disambiguiation
实体消歧的本质在于一个词很有可能多个意思,也就是在不同的上下文中所表达的含义不太一样。
例如:小米、苹果、还有同名的人。
![19[NLP训练营]信息抽取Information Extraction_第35张图片](http://img.e-com-net.com/image/info8/dc1714b08d1c46658a538183e59c09e8.jpg)
在给定一个实体库(或叫描述库)的情况下,如何高效的判断问题中的实体具体是哪个。
![19[NLP训练营]信息抽取Information Extraction_第36张图片](http://img.e-com-net.com/image/info8/2d8278638eff414898b9d6cf2f4fea98.jpg)
实际上是计算问题中的实体与实体库中的每个对象的相似度的:
![19[NLP训练营]信息抽取Information Extraction_第37张图片](http://img.e-com-net.com/image/info8/556e40bfba7f4aebbdde86e656343c77.jpg)
一提到相似度,先要把词转换为向量(TFIDF、word2vec等等)。这里用的是基于上下文的词向量表示,把文章中出现“苹果”这个词前后各20个词(这个数量可以自己定)一起考虑进来,这样就可以做大小为20+1+20=41大TFIDF向量。然后再和实体库里面的对象做相似度计算。
当然也可以用ELMO,BERT更加niubility的技术来搞。
实体统一
问题定义:给定两个实体,判断是否是指向同一个实体?这个是二分类问题。
举例:给定两个实体:字符串,str1,str2,判断是否两个字符串是否同一个实体。
第一种方法:计算两个字符串的相似度。之前有提到过,两个词的相似度实际上可以用编辑距离来表示(edit distance)
第二种方法:基于规则。
百度有限公司、百度科技有限公司、百度广州分公司其实都是百度,我们通过下面的规则表,把这些不同的名称转换为原型模式(prototype)
![19[NLP训练营]信息抽取Information Extraction_第38张图片](http://img.e-com-net.com/image/info8/4c887661ccec49a8863b2f24fcaf3a90.jpg)
这个过程有点类似把不同时态或是复数形式的英文单词转换为原型单词的过程。
第三种方法:基于有监督的学习方法。
提前就标记好了百度和百度有限公司是同一个实体
![19[NLP训练营]信息抽取Information Extraction_第39张图片](http://img.e-com-net.com/image/info8/a651d18e5dc34a019e3122c902bf616c.jpg)
先用tfidf等方法分别转化为两个向量(特征提取)
接下来可以有两种方法:
1.先拼接再丢到模型进行二分类
![19[NLP训练营]信息抽取Information Extraction_第40张图片](http://img.e-com-net.com/image/info8/1c23d96a98774e84a9c2b4e0e17332f1.jpg)
2.先计算余弦相似度,然后经过逻辑回归模型,得到分类结果。
![19[NLP训练营]信息抽取Information Extraction_第41张图片](http://img.e-com-net.com/image/info8/2203b82ad2d6427bab6c0e86059f5af7.jpg)
以上两个方法可以用准确率来比较选择。当然为了提高准确率,可以添加自己的手工特征,如:V1和V2的编辑距离。
例子:基于图的实体统一
![19[NLP训练营]信息抽取Information Extraction_第42张图片](http://img.e-com-net.com/image/info8/ff79c71355674c1991fe7695db10f78e.jpg)
先构造特征:
![19[NLP训练营]信息抽取Information Extraction_第43张图片](http://img.e-com-net.com/image/info8/5f66e1b01dfd42d89c0d9dd7c02ee454.jpg)
上面的关系相关特征中,只包含的一度邻居,还可以扩展为二度邻居。
![19[NLP训练营]信息抽取Information Extraction_第44张图片](http://img.e-com-net.com/image/info8/6705816c94834f59b959362e3e80810a.jpg)
指代消解Co-reference Resolution
![19[NLP训练营]信息抽取Information Extraction_第45张图片](http://img.e-com-net.com/image/info8/a8a6d24e6bbc4d78902dabbc05a904b2.jpg)
从上面的例子我们知道,这个还是一个分类问题。
1、最简单的方法:把代词关联最近的实体。可以用来做baseline
2、监督学习方法:
2.1收集数据,并标记出对象,例如哪个是人名,哪个是指代的代词
2.2标记数据:类似上面的句子,标注出每个代词属于哪个对象,形成样本。然后构造特征,便于输入到后面的分类器中。
2.2.1形成样本
![19[NLP训练营]信息抽取Information Extraction_第46张图片](http://img.e-com-net.com/image/info8/293053d8a7614be09f9225140794c849.jpg)
2.2.2构造特征
这个步骤有点像snowball算法中构造五元组的过程。
以(张三,A)为例,分别取他们两个的前中后的字符串,用类似TFIDF算法构造成向量(这里没有把张三,A放进去构造向量)有了向量,有了标签,就可以训练分类器了:
![19[NLP训练营]信息抽取Information Extraction_第47张图片](http://img.e-com-net.com/image/info8/6f08b836dd7e4a2882e4097d65af5c4b.jpg)
可以看到,指代消解还没有脱离手工操作,仍然是待解决的问题。
句法分析Parsing
先看人如何理解句子,人理解一个句子,两种方法:
1、从句法分析:主谓宾
2、凭感觉,这个方法类似之前讲过的语言模型。
这里主要看句法分析,用的句法树(语法树 syntax tree)。例如:
Microsoft is located in Redmond
![19[NLP训练营]信息抽取Information Extraction_第48张图片](http://img.e-com-net.com/image/info8/01cc84efc2d546b585b9d2c1e50fd1f3.jpg)
![19[NLP训练营]信息抽取Information Extraction_第49张图片](http://img.e-com-net.com/image/info8/f07df0f10dd444be977ba59128a24453.jpg)
这个树是用CKY算法得来,后面会讲。
上面的语法树中,叶子节点叫terminal node,非叶子节点叫internal node(non-terminal node)
句法树中提取特征Parsing for Feature Extraction
可以根据之前指代消解的方法取两个对象的前中后来构造特征,还可以用语法树来构造特征。
树的特征提取:
1、最短路径
2、用路径上的词性来作为特征,例如Microsoft和Redmond的特征是:N/NP/S/VP/VP/PP/N
下面来如何把句子转换为句法树。
给定语法,写出语法树和句子
![19[NLP训练营]信息抽取Information Extraction_第50张图片](http://img.e-com-net.com/image/info8/46bf3512712f442a93a497478663d793.jpg)
S是句子的开头,e是句子的结束。后面是Terminal节点的例子。例如:根据上面的左边先随机的生成一个语法树,终端节点也随机从上面拿:
![19[NLP训练营]信息抽取Information Extraction_第51张图片](http://img.e-com-net.com/image/info8/dcbb98a01f004dc38ccdb69c13dc9da5.jpg)
例子:old MT
![19[NLP训练营]信息抽取Information Extraction_第52张图片](http://img.e-com-net.com/image/info8/79122ad3b18149648463e0f74158f3c9.jpg)
这个过程需要很强的领域知识:
![19[NLP训练营]信息抽取Information Extraction_第53张图片](http://img.e-com-net.com/image/info8/74648a03351b4a10b4daf49bd4ffc5f3.jpg)
如果换成日文翻译为中文,又要重来。
后来改进,无需人工干预的翻译:
![19[NLP训练营]信息抽取Information Extraction_第54张图片](http://img.e-com-net.com/image/info8/f8537354483348768f29c76d43db8a65.jpg)
From CFG to PCFG
context free grammer
probability context free grammer
看下二者的对比
![19[NLP训练营]信息抽取Information Extraction_第55张图片](http://img.e-com-net.com/image/info8/98421b316485416b87ceab8207d036b7.jpg)
明显的,PCFG比CFG多了概率,里面的概率的特点也很容易看出来,如果一个词性后面能接1种词性,例如S,那么它对应的概率是1,如果一个词性后面能接多种词性,这些词性的概率和为1,具体每种词性对应多少概率可以从训练数据中统计得到(从标记好的树进行统计)。
evaluate syntax tree
给定一个PCFG和一个句子,那么我们就可以生成多个语法树(因为有多种可能。)
然后我们通过一个分数来评估哪个语法树最好,现在看如何设计这个分数?
![19[NLP训练营]信息抽取Information Extraction_第56张图片](http://img.e-com-net.com/image/info8/97d523b3c7134cbc99cc32274d1785e4.jpg)
![19[NLP训练营]信息抽取Information Extraction_第57张图片](http://img.e-com-net.com/image/info8/e6e3a8f8b93f49eab49f9b0b43638c31.jpg)
可以看到,分数就是语法树中的概率的乘积。
Find the Best Syntax Tree
一种就是笨方法,枚举所有可能的语法树,再比较分数,这样时间复杂度相当高。
另外就是CKY算法,是一种DP算法
CKY算法
Intuition about CKY Algorithm
直接枚举太复杂,利用DP的思想,每次把问题拆分成两个子问题来考虑,例如:考虑四个单词的句子,可以有下面几种情况:
![19[NLP训练营]信息抽取Information Extraction_第58张图片](http://img.e-com-net.com/image/info8/03824439e1a04c9fbd906317aecc2aed.jpg)
可以看出,要分成两个子问题,词性后面接的情况不能多于2个。(Binarization二值化)
![19[NLP训练营]信息抽取Information Extraction_第59张图片](http://img.e-com-net.com/image/info8/c0ce7cf6791b4db7af7e3051ea12974d.jpg)
类似红线的那种情况要想办法去掉,或者转换一下。
Transforming to CNF(Chomsky Normal Form)
CNF比上面的二值化要求更加严格:
1、词性对应的值不能大于2;红色
2、词性对应的值不能出现e;黄色
3、词性对应的值不能出现只对应一个词性的值。蓝色
![19[NLP训练营]信息抽取Information Extraction_第60张图片](http://img.e-com-net.com/image/info8/fb54581cc0af433cb5c085912a73fc1b.jpg)
下面看如何转换为CNF,
1.remove e
如下图所示的规则,去掉e后,相当于NP可以指向null
![19[NLP训练营]信息抽取Information Extraction_第61张图片](http://img.e-com-net.com/image/info8/aa20a21f2e1248c59b0d05275858061a.jpg)
那么规则中要新增加之前指向NP的规则,去掉NP→e,就变成了(打钩的是新加的)
![19[NLP训练营]信息抽取Information Extraction_第62张图片](http://img.e-com-net.com/image/info8/5314adcb33b644b3a869c777e5723a30.jpg)
2.Remove unaries
去掉只指向一个值(unaries)的规则,以下面框汇中的规则为例:
![19[NLP训练营]信息抽取Information Extraction_第63张图片](http://img.e-com-net.com/image/info8/a6415444e0d044d9a9dee5a81c39ee88.jpg)
这个规则相当于可以把VP看做S,那么,去掉S→VP后:
VP→V NP
VP→V
VP→V NP PP
VP→V PP
变成
VP→V NP
S→V NP
VP→V
S→V
VP→V NP PP
S→V NP PP
VP→V PP
S→V PP
所以上面的图片,变成:
![19[NLP训练营]信息抽取Information Extraction_第64张图片](http://img.e-com-net.com/image/info8/fb9d1fe5da2e4a7e80f996a6f8971fbc.jpg)
现在来看另外一个单值规则S→V,注意,之前终端规则没有写出来,因为没有涉及到,现在涉及到了,所以显示出来,如果要去掉S→V,可以看做V相当于S,去掉S→V后
![19[NLP训练营]信息抽取Information Extraction_第65张图片](http://img.e-com-net.com/image/info8/020d6d168c114b8a93126f42dc87f71f.jpg)
可以看做V相当于S,去掉S→V后:
![19[NLP训练营]信息抽取Information Extraction_第66张图片](http://img.e-com-net.com/image/info8/c1dba26726784b909dd9e9692bef9388.jpg)
接下来看其他几个单值规则:
![19[NLP训练营]信息抽取Information Extraction_第67张图片](http://img.e-com-net.com/image/info8/0f706c93ec6847b7a8c0433a079d55d3.jpg)
1号是没有什么意义的,直接去掉
2号去掉后,加上NP→P NP
3号处理有点怪,不知道为什么老师讲的时候和前面的例子不一样,他是直接把后面的
N→people
N→fish
N→tanks
N→rods
变成了
NP→people
NP→fish
NP→tanks
NP→rods
并没有保留原来的N,奇怪。。。难道NP和N之间有转换关系?
4号处理去掉后,变成:
PP→with
整理后结果为:
![19[NLP训练营]信息抽取Information Extraction_第68张图片](http://img.e-com-net.com/image/info8/a1df77322a49433a9a5e214c08e7ec74.jpg)
可以看到这个时候右边的规则已经没有单值的规则了。
remove trinaries
![19[NLP训练营]信息抽取Information Extraction_第69张图片](http://img.e-com-net.com/image/info8/b9a3bec27b9544d3be4f51e6fb621c67.jpg)
去掉三值规则很简单,把其中两个值合并,形成新的值。
以上图中红框中的规则为例:
VP→V NP PP,把后面两个NP PP合并起来,并起名:@VP_V,并加入规则:@VP_V→NP PP
最后的形式:
![19[NLP训练营]信息抽取Information Extraction_第70张图片](http://img.e-com-net.com/image/info8/461f3c1e1ec047ffaa1de544e8744428.jpg)
CNF就讲到这里,接下来看CKY算法。。。
CKY Algorithm
考虑一个四个单词的句子组成的树:
这个树顺时针转了45°,是为了书写方便。
![19[NLP训练营]信息抽取Information Extraction_第71张图片](http://img.e-com-net.com/image/info8/6fc14824ac5b43da9e5a43f445193bc0.jpg)
填写叶节点(搞不清为什么左边不是CNF格式。。。):
![19[NLP训练营]信息抽取Information Extraction_第72张图片](http://img.e-com-net.com/image/info8/c07d6327a1f44132830ac3a1c25a8509.jpg)
接下来填上一层
![19[NLP训练营]信息抽取Information Extraction_第73张图片](http://img.e-com-net.com/image/info8/241b40df92fa43d68725407e8f50a07b.jpg)
以红圈位置为例,这个位置是fish,people两个词的父结点,然后要找两个子节点中同时出现的规则,然后计算概率的方式和上面一样,连乘。如果一个对象出现两次,则取概率大的那个。
例如:NP→NP NP=(NP→NP NP)× (NP→N这个是fish格子的)×(NP→N这个是people格子的)=0.1× 0.14× 0.35=0.0049
还没有完,还要看在规则中有没有单独出现的,例如上图中有:
VP→V NP=0.5× 0.6× 0.35=0.105
由于规则库中还有S→VP,所以还要把它加进来,由于有两个S→ 我们要保留概率比较大的那个
这个S→VP=0.1× 0.105=0.0105
上面的S→NP VP=0.9× 0.14× 0.01=0.00126(这个比较小,要去掉)
以此类推:
![19[NLP训练营]信息抽取Information Extraction_第74张图片](http://img.e-com-net.com/image/info8/ab8c45d207fc43d892dd0254e30f4e04.jpg)
接下来再要往上算:
![19[NLP训练营]信息抽取Information Extraction_第75张图片](http://img.e-com-net.com/image/info8/93b106be67924e85ba7ad8d8e37659c2.jpg)
这里相当于要考虑三个单词例如:
fish people fish可以有两种情况
fish +( people fish)就是相当于红色箭头。箭头尾部是fish,箭头顶端是( people fish)
(fish people)+ fish相当于与黄色箭头
然后计算的方式与上面一样,也是用概率相乘。结果如下:
![19[NLP训练营]信息抽取Information Extraction_第76张图片](http://img.e-com-net.com/image/info8/21da0e4d11c146549bfa6589c2175954.jpg)
接下来填最右上角的空格,这里相当于要考虑四个单词:
fish people fish tank
有三种情况
fish +(people fish tank):红圈组合
(fish people) +(fish tank):蓝圈组合
(fish people fish)+ tank:黄圈组合
![19[NLP训练营]信息抽取Information Extraction_第77张图片](http://img.e-com-net.com/image/info8/0bf810e8144c4c24bdb789f81ef46e28.jpg)
最后结果:
![19[NLP训练营]信息抽取Information Extraction_第78张图片](http://img.e-com-net.com/image/info8/c051c082335a4ac78b3fbb10b45910a9.jpg)
有了这个树,我们现在就可以进行反推。例如,一句话是S开头,就可以从根结点反推。