SqueezeNet系列是比较早期且经典的轻量级网络,SqueezeNet使用Fire模块进行参数压缩,而SqueezeNext则在此基础上加入分离卷积进行改进。虽然SqueezeNet系列不如MobieNet使用广泛,但其架构思想和实验结论还是可以值得借鉴的。
来源:晓飞的算法工程笔记 公众号
SqueezeNet
论文: SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size

Introduction
在深度学习崭露头角时候,很多研究都关注如何提高网络的准确率,而SqueezeNet则是早期开始关注轻量化网络的研究之一。论文的初衷是通过优化网络的结构,在与当前流行网络的准确率相差不大的情况下,大幅减少模型的参数。
SqueezeNet: Preserving Accuracy with Few Parameters
Architectural Design Strategies
论文的轻量级网络设计主要包含以下策略:
- 替换$3\times 3$卷积为$1\times 1$卷积,由于$1\times 1$卷积比$3\times 3$卷积有9倍的参数减少。
- 减少$3\times 3$卷积的输入维度,$3\times 3$卷积的总参数量为(number of input channels)(number of filters)(3*3),使用squeeze layers降低输入维度,能够降低整体的计算量。
- 下采样操作尽量安排在网络较后的阶段,这样卷积层能够有较大的特征图,保存更多的信息,从而提高准确率。
策略1和策略2主要为了减少网络的参数但保持准确率,策略3则是为了在有限的参数下最大化准确率。
The Fire Module
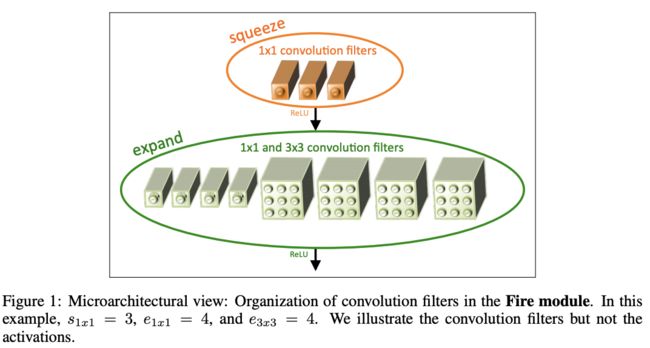
SqueezeNet的核心模块为Fire模块,结构如图1所示,输入层先通过squeeze卷积层($1\times 1$卷积)进行维度压缩,然后通过expand卷积层($1\times 1$卷积和$3\times 3$卷积混合)进行维度扩展。Fire模块包含3个参数,分别为squeeze层的$1\times 1$卷积核数$s_{1x1}$、expand层的$1\times 1$卷积核数$e_{1x1}$和expand层的$3\times 3$卷积核数$e_{3x3}$,一般$s_{1x1}<(e_{1x1}+e_{3x3})$
The SqueezeNet Architecture
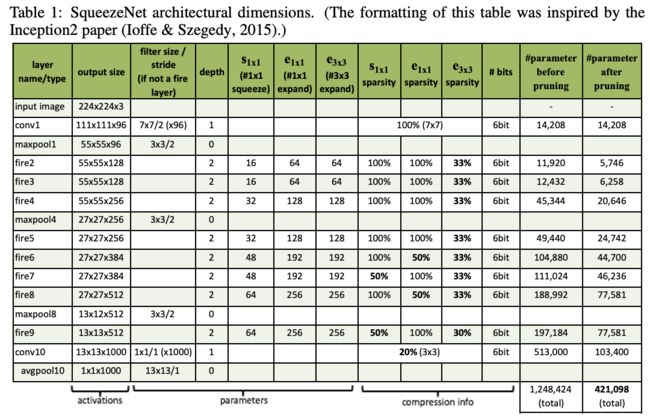
SqueezeNet的结构如表1所示,在conv1、fire4、fire8和conv10后添加池化层进行池化操作,网络中逐步提高输出维度。每个squeeze层和expand层的输出都通过ReLU激活,而fire9模块后面会接50%的Dropout。
Evaluation of SqueezeNet

与AlexNet相比,相同准确率下,SqueezeNet仅需要1/50的参数量,量化后,最多可以缩小到1/510的参数量。
CNN Microarchitecture Design Space Exploration

论文对Fire模块的设定进行了探索实验,主要对比squeeze层的压缩比例以及expand层中的$3\times 3$卷积占比。
CNN Macroarchitecture Design Space Exploration
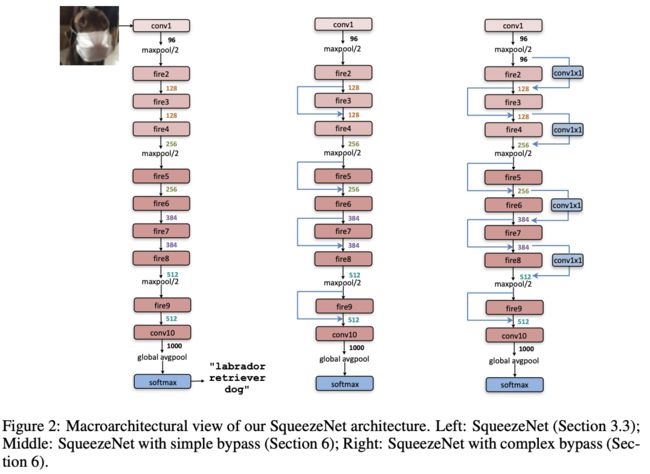

论文对网络的微架构进行了探索实验,主要是研究短路连接对网络的影响,对比的网络结构如图2所示。
Conclusion
SqueezeNet作为早期的轻量级网络研究工作,虽然准确率对比的是AlexNet,但其网络压缩比是相当可观的,Fire模块的设计也十分新颖。
SqueezeNext
论文: SqueezeNext: Hardware-Aware Neural Network Design

Introduction
SqueezeNext是SqueezeNet实战版升级,直接和MobileNet对比性能。SqueezeNext全部使用标准卷积,分析实际推理速度,优化的手段集中在网络整体结构的优化。
SqueezeNext Design
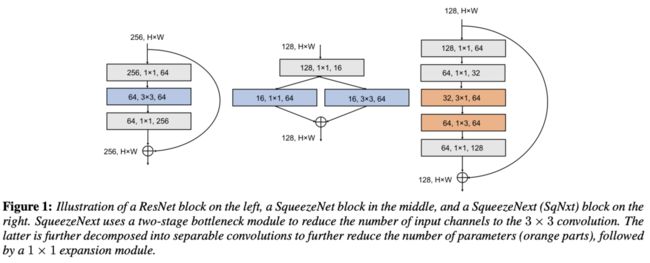
SqueezeNext的设计沿用残差结构,没有使用当时流行的深度卷积,而是直接使用了分离卷积,设计主要基于以下策略:
- Low Rank Filters
低秩分解的核心思想就是将大矩阵分解成多个小矩阵,这里使用CP分解(Canonical Polyadic Decomposition),将$K\times K$卷积分解成$K\times 1$和$1\times K$的分离卷积,参数量能从$K^2$降为$2K$。
- Bottleneck Module
参数量与输入输出维度有关,虽然可以使用深度卷积来减少计算量,但是深度卷积在终端系统的计算并不高效。因此采用SqueezeNet的squeeze层进行输入维度的压缩,每个block的开头使用连续两个squeeze层,每层降低1/2维度。
- Fully Connected Layers
在AlexNet中,全连接层的参数占总模型的96%,SqueezeNext使用bottleneck层来降低全连接层的输入维度,从而降低网络参数量。
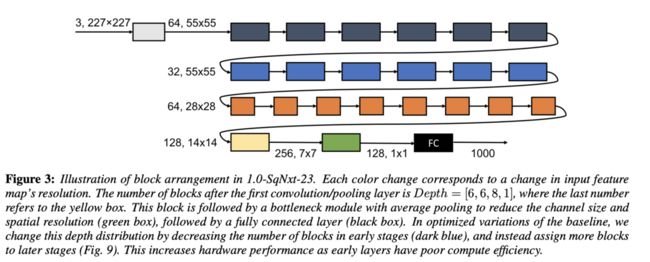
基础的1.0-SqNxt-23结构如图3所示,中间的block均为SqueezeNext block,第一个block为正常的卷积,最后两个block分别为bottleneck模块以及全连接层。
Result
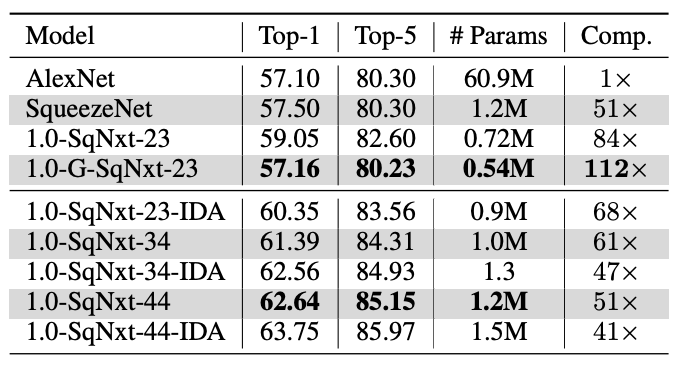
论文对比了不同网络以及不同版本的SqueezeNext,包括不同的网络长度,以及加入不同的结构。表中的1.0代表基础的层维度设置,G代表卷积的group size设置为2,后面的数字为总层数,IDA代表使用Iterative Deep Aggregation,融合多层进行输出。
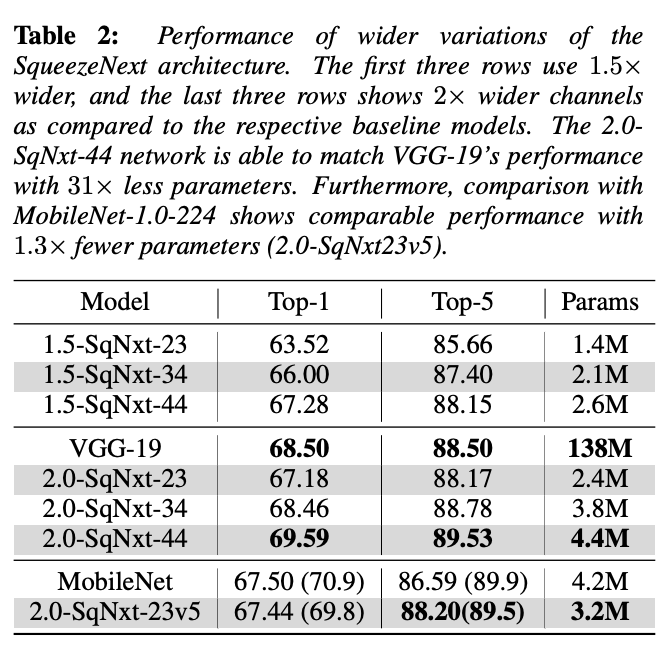
另外论文也对比了更宽的网络的性能,对维度进行了倍数放大。
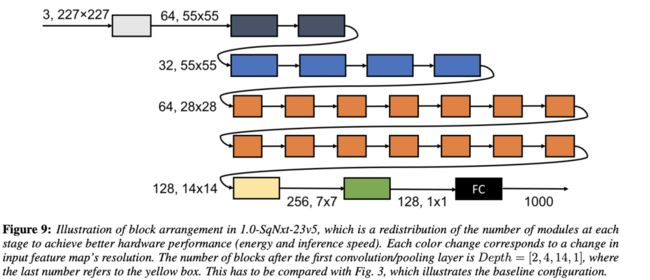
v5的结构如图9,在模拟硬件性能实验结果中发现,维度越低,计算性能也越低效,于是将更多的层操作集中在维度较高的block。
Conclusion
SqueezeNext在SqueezeNet的压缩思想上,结合分离卷积进行参数压缩改进,文中的模拟硬件推理性能的实验做的很精彩,可以看到作者如何一步一步地改进网络的整体结构,有兴趣的可以去看看原文。
CONCLUSION
SqueezeNet系列是比较早期且经典的轻量级网络,SqueezeNet使用Fire模块进行参数压缩,而SqueezeNext则在此基础上加入分离卷积进行改进。虽然SqueezeNet系列不如MobieNet使用广泛,但其架构思想和实验结论还是可以值得借鉴的。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
