【SCIR论文】ACL20 基于对话图谱的开放域多轮对话策略学习
论文名称:Conversational Graph Grounded Policy Learning for Open-Domain Conversation Generation
论文作者:徐俊,王海峰,牛正雨,吴华,车万翔,刘挺
原创作者:哈工大 SCIR 博士生 徐俊
出处:哈工大SCIR
1 简介
论文中提出用图的形式捕捉对话转移规律作为先验信息,用于辅助开放域多轮对话策略学习。为此,研究人员首先从对话语料库中构建了一个对话图谱(Conversational Graph),其中节点表示“What to say”和“How to say”,边表示当前句(对话上文中的最后一个语句)与其回复句之间的自然转换。然后,论文中提出了一个基于对话图的策略学习框架,该框架通过图遍历进行对话流规划,学习在每轮从对话图中识别出一个“What”节点和“How”节点来指导回复生成。
这样可以有效地利用对话图谱来促进策略学习,具体如下:
• 可以实现更有效的长期奖励设计;
• 提供高质量的候选操作;
• 让我们对策略有更多的控制。在两个基准语料库的实验结果表明了帮了我了所提框架的有效性;
2 方法
论文中提出了基于对话图谱(CG)的开放域多轮对话策略模型。其中,对话图谱用来捕捉对话中的局部合适度以及全局连贯度信息。直观上,策略模型以图中的What节点 (关键词)作为可解释的离散状态,进而模型得以主动规划对话内容,进而提升多轮连贯度和可控性。
图1是本文方法的框架图,实线椭圆代表“What”节点,实线圆形代表“How”节点。对于当前句(图中Message),策略模型首先将其定位到图中的“What”节点(图中绿色关键词),进而主动规划要聊的内容(图中橙红色的两个节点),再经由生成模型产出回复句(图中Response)。
 图1 基于对话图谱的开放域多轮对话策略模型
图1 基于对话图谱的开放域多轮对话策略模型
对话图谱的构建主要包含点(What-节点和How-节点)的构建,以及边的建设两部分。首先,研究人员从对话语料中抽取关键词作为What-节点,关键词使用开源的基于词性等特征的工具抽取,分别挖掘语料上下句中的关键词,组成关键词对,再基于共现频率在What-节点之间建边。
同What-节点直接表达“说什么”不同,How-节点代表“怎么说”,这类节点无法直接从语料中抽取。研究人员基于MMPMS[1]模型学习到的表达方式(隐变量)为How节点集合,再统计What-节点经常使用哪些How-节点解码(表达出来),基于共现频率建边。
抽取工具地址:
http://github.com/squareRoot3/Target-Guided-Conversation
策略模型首先基于映射来做对话理解,根据对话当前句中出现的关键词映射到对话图中的What-节点,召回全部What-节点的所有一阶What-节点邻居提供给Policy;之后,Policy选择其中一个What-节点确定回复内容,再选择该What-节点的一个How-节点,确定回复方式;NLG负责生成具体回复句。论文中将基于对话图谱的策略模型称之为CG-Policy。
为了训练CG-Policy,我们设计了多种来源的奖励信号:
基于句子的奖励
句间相关度:我们使用对话下的多轮检索模型[2]为每轮生成的回复句进行相关度打分;
句间重复惩罚:我们鼓励多样的内容规划生成,当有超过60%的生成的回复句中的词语在上文中任意一句中同时出现,则判定为重复;
基于图结构的奖励
全局连贯度:TransE空间下选中/提及What节点间的平均cosine距离;
可持续性:我们鼓励主动聊内容丰富的节点,这样未来可聊的内容会相对更对,具体而言我们使用PageRank打分;
此外,CG-Policy可控性也很好(如要求聊到特定的对话目标节点上),但需要设计相应的奖励函数。具体而言,我们增加了下面的奖励函数:
可控性奖励
目标相似度:选定What节点和目标节点在语义空间的cosine距离,该距离表征当前到目标还是多远;
到目标节点的图上最短距离;
3 实验设置
我们在常用的公开数据集Weibo[3]和Persona[4]上开展实验。对于基线模型,我们选用下述三个代表性模型。
• LaRL[5]:SOTA 基于隐变量的强化学习对话模型
• ChatMore[6]:关键词增强的生成式对话模型
• TGRM[7]:关键词增强的检索式对话模型
我们在训练LaRL、CG-Policy(本文所提模型)使用MMPMS模型[1]作为用户模拟器,用户模拟器在策略学习过程中参数不变。此外,在机机对话时,所有模型共享该用户模拟器。
为了综合评估模型的效果,我们在多轮和单轮两个层面从以下几个维度分别进行评估:
多轮评估指标
全局连贯度(Cohe.)
多样性 (Dist-2)
单轮评估指标
适合度 (Appr.),信息丰富度 (Info.)
4. 实验结果
首先,我们在微博语料下分别进行机机、人机实验,从微博语料中抽取构建的对话图谱含有4000个What-节点和10个How-节点,What-节点之间有74,362条边,其中有64%的边经过人工评估表明捕捉了合适的对话转移规律。如表1所示,结果表明CG-Policy在多轮连贯性上显著超越基线。
表格1:微博语料下机机和人机对话实验结果

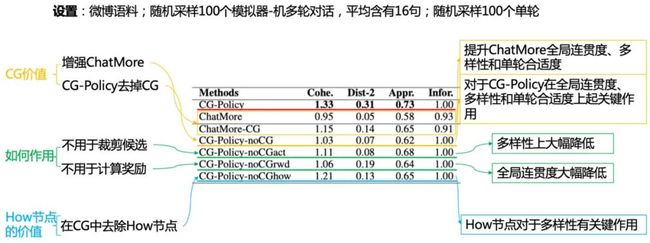
其次,为了说明CG-Policy中CG的价值、CG如何起作用以及How节点的价值,我们进行了消融实验。实验设置和结果如表2所示。
表格2:消融实验
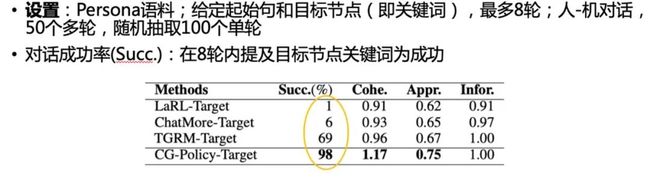
表格3:可控性实验
5 对话样例

6 结论
我们提出用对话图谱的形式捕捉对话转移规律作为先验信息,以图中“What-vertex” (关键词)作为可解释的离散状态,用于辅助开放域多轮对话策略学习,生成更加连贯和可控的多轮对话。
参考文献
[1]. Chaotao Chen, Jinhua Peng, Fan Wang, Jun Xu, and Hua Wu. 2019. Generating multiple diverse responses with multi-mapping and posterior mapping selection. Proceedings of IJCAI.
[2]. Antoine Bordes, Nicolas Usunier, Alberto GarciaDuran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multirelational data. In Advances in neural information processing systems, pages 2787–2795.
[3]. Lifeng Shang, Zhengdong Lu, and Hang Li. 2015. Neural responding machine for short-text conversation. In Proceedings of ACL-IJCNLP, volume 1, pages 1577–1586.
[4]. Saizheng Zhang, Emily Dinan, Jack Urbanek, Arthur Szlam, Douwe Kiela, and Jason Weston. 2018a. Personalizing dialogue agents: I have a dog, do you have pets too? In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22042213.
[5]. Zhao, T.; Xie,K.; and Eskenazi, M. 2019. Rethinking action spaces for reinforcement learning in end-to-end dialog agents with latent variable models. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long andShort Papers), 12081218.
[6]. Lili Yao, Ruijian Xu, Chao Li, Dongyan Zhao, and Rui Yan. 2018. Chat more if you like: Dynamic cue words planning to flow longer conversations. arXiv preprint arXiv:1811.07631.
[7]. Jianheng Tang, Tiancheng Zhao, Chenyan Xiong, Xiaodan Liang, Eric P. Xing, and Zhiting Hu. 2019. Target-guided open-domain conversation. In Proceedings of ACL.
本期责任编辑:张伟男
本期编辑:王若珂
添加个人微信,备注:昵称-学校(公司)-方向,即可获得
1. 快速学习深度学习五件套资料
2. 进入高手如云DL&NLP交流群

记得备注呦
