行为识别
行为识别
行为识别常用深度网络
光流的作用
On the Integration of Optical Flow and Action Recognition(2017) (2018CVPR)
大多数表现优秀的动作识别算法使用光流作为“黑匣子”输入。 在这里,我们更深入地考察光流与动作识别的结合,并研究为什么光流有帮助, 光流算法对动作识别有什么好处,以及如何使其更好。
实验结果表明: 当前体系结构中光流的大部分价值在于它对场景表示的表观不变(invariant to appearance), 也表明运动轨迹不是光流成功的根源,并且建立有用的运动表示仍然是光流自身无法解决的一个悬而未决的问题。
由于光流是从图像序列计算出来的,所以有人可能会争辩说,训练有素的网络可以学习如何计算光流,如果光流是有用的,则不需要明确计算光流。
尽管使用显式运动估计作为涉及视频任务的输入可能看起来很直观,但人们可能会争辩说使用运动并不是必需的。 一些可能的论点是,当前数据集中的类别可以从单帧中识别出来,并且可以从单帧中识别视觉世界中更广泛的许多对象和动作.
C3D
C3D能把 ImageNet 的成功(迁移学习)复制到视频领域吗?
目前Action Recognition的研究方向(发论文的方向)分为三大类。
1 Structure
2 Inputs
3 Connection
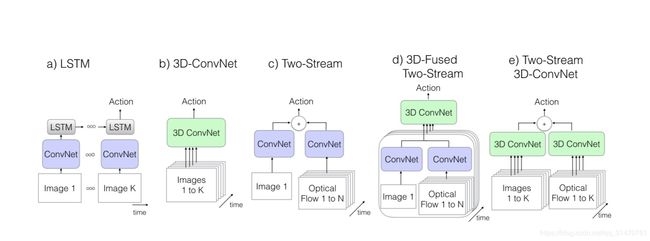
这里的结构主要指网络结构。目前,主流的结构都是基于 Two-Stream Convolutional Networks和 C3D 发展而来,所以这一块内容也主要讨论这两种结构的各种演化中作为benchmark的一些结构。
1
首先讨论TSN模型,这是港中文汤晓鸥组的论文,也是目前的benchmark之一,许多模型也是在TSN的基础上进行了后续的探索。
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition【ECCV2016】
该论文继承了双流网络的结构,但为了解决long-term的问题,作者提出使用多个双流网络,分别捕捉不同时序位置的short-term信息,然后进行融合,得到最后结果。
2
Deep Local Video Feature for Action Recognition 【CVPR2017】
TSN改进版本之一。
改进的地方主要在于fusion部分,不同的片段的应该有不同的权重,而这部分由网络学习而得,最后由SVM分类得到结果
3
Temporal Relational Reasoning in Videos
TSN改进版本二。
这篇是MIT周博磊大神的论文,作者是也是最近提出的数据集 Moments in time 的作者之一。
该论文关注时序关系推理。对于哪些仅靠关键帧(单帧RGB图像)无法辨别的动作,如摔倒,其实可以通过时序推理进行分类。如下图。

除了两帧之间时序推理,还可以拓展到更多帧之间的时序推理
通过对不同长度视频帧的时序推理,最后进行融合得到结果。
该模型建立TSN基础上,在输入的特征图上进行时序推理。增加三层全连接层学习不同长度视频帧的权重,及上图中的函数g和h。
除了上述模型外,还有更多关于时空信息融合的结构。这部分与connection部分有重叠,所以仅在这一部分提及。这些模型结构相似,区别主要在于融合module的差异
4.Two-Stream I3D
I3D[DeepMind]
动作在单个帧中可能不明确,然而, 现有动作识别数据集的局限性意味着性能最佳的视频架构不会明显偏离单图分析,因为他们依赖在ImageNet上训练的强大图像分类器。
数据集: Kinetics
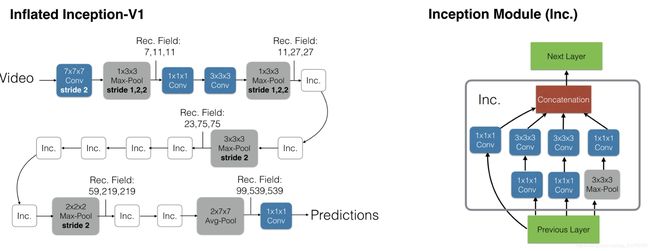
即基于inception-V1模型,将2D卷积扩展到3D卷积。
I3D 性能更好的原因:
一是 I3D的架构更好,
二是 Kinetic 数据集更具有普适性
5.
T3D
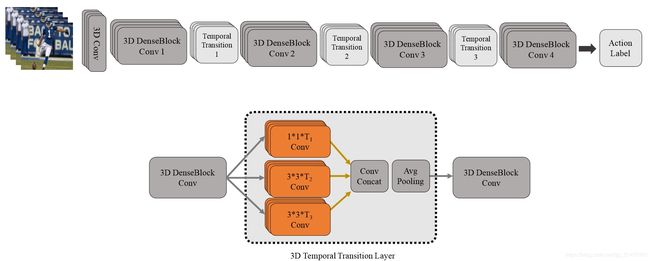

该论文值得注意的,一方面是采用了3D densenet,区别于之前的inception和Resnet结构;另一方面,TTL层,即使用不同尺度的卷积(inception思想)来捕捉讯息。
6.
P3D[MSRA]
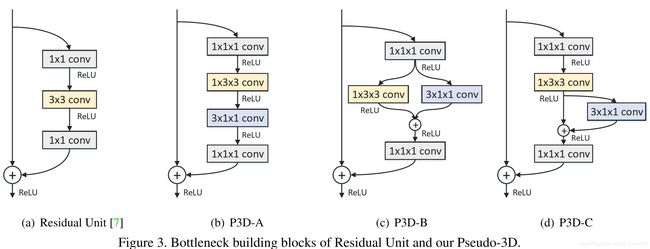
改进ResNet内部连接中的卷积形式。然后,超深网络,一般人显然只能空有想法,望而却步
7.
Temporal Pyramid Pooling
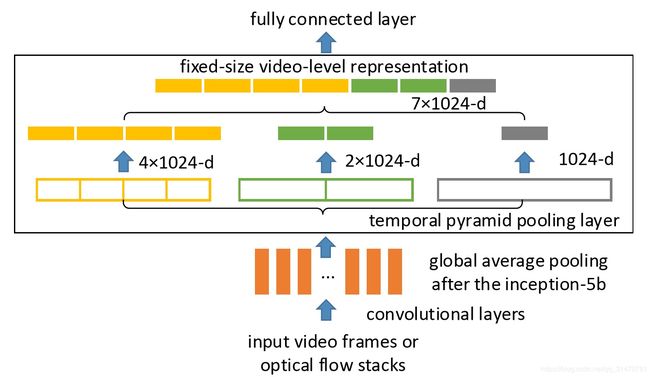
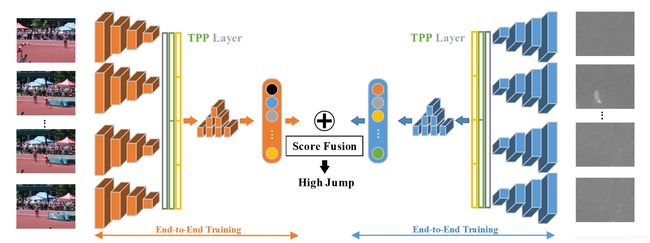
Pooling。时空上都进行这种pooling操作,旨在捕捉不同长度的讯息。
In this paper, we propose Deep networks with Temporal Pyramid Pooling (DTPP), an end-to-end video-level representation learning approach.
Finally, DTPP achieves the state-of-the-art performance on UCF101 and HMDB51, either by ImageNet pre-training or Kinetics pre-training.
8.TLE
TLE层的核心.

TLE层在双流网络中的使用。
TLE层在C3D结构网络中的使用。
Connection
这里连接主要是指双流网络中时空信息的交互。一种是单个网络内部各层之间的交互,如ResNet/Inception;一种是双流网络之间的交互,包括不同fusion方式的探索,目前值得考虑的是参照ResNet的结构,连接双流网络。
这里主要讨论双流的交互。不同论文之间的交互方式各有不同
9.
Spatiotemporal Multiplier Networks for Video Action Recognition【CVPR2017】
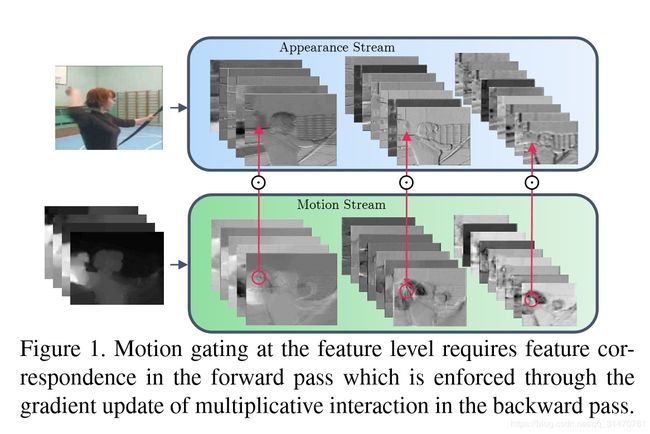
网络的结构如上图。空间和时序网络的主体都是ResNet,增加了从Motion Stream到Spatial Stream的交互。论文还探索多种方式。
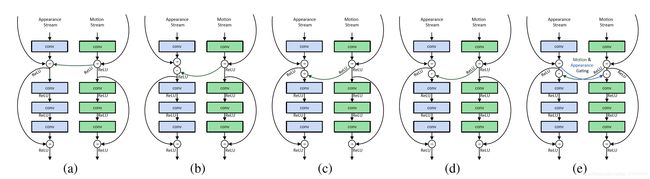
10.
Spatiotemporal Pyramid Network for Video Action Recognition 【CVPR2017】

论文作者认为,行为识别的关键就在于如何很好的融合空间和时序上的特征。作者发现,传统双流网络虽然在最后有fusion的过程,但训练中确实单独训练的,最终结果的失误预测往往仅来源于某一网络,并且空间/时序网络各有所长。论文分析了错误分类的原因:空间网络在视频背景相似度高的时候容易失误,时序网络在long-term行为中因为snippets length的长度限制容易失误。那么能否通过交互,实现两个网络的互补呢
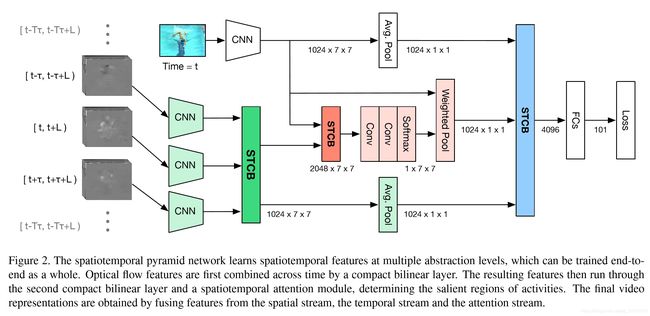
该论文重点在于STCB模块,详情请参阅论文。交互方面,在保留空间、时序流的同时,对时空信息进行了一次融合,最后三路融合,得出最后结果。
Attentional pooling for action recognition 【NIPS2017】
ActionVLAD for video action classification 【CVPR2017】
这两篇论文从pooling的层面提高了双流的交互能力,这两篇笔者还在看,有兴趣的读者请自行参阅论文。后期会附上论文的解读。
Deep Convolutional Neural Networks with Merge-and-Run Mappings
这篇论文也是基于ResNet的结构探索新的双流连接方式。
论文:Non-local Neural Networks for Video Classification
论文链接:https://arxiv.org/abs/1711.07971
代码链接:https://github.com/facebookresearch/video-nonlocal-net
通过特征学习到特征与特征之间的关系,这样类似于对全局特征做了attention,对于多帧的输入,不管是2D还是3D卷积,都提供了更多帮助学习action的信息。作者开源了代码,应该是目前的state-of-the-art。
总结:
在motion特征被理解之前,双流网络可能仍然是主流。
时空信息交互仍然有探索的余地,个人看来也是最有可能发论文的重点领域。
输入方面,替代光流的特征值得期待。
15.R(2+1)D
S3D?
P3D?
我们的研究动机源于观察到这样一个现象, 在动作识别中, 基于视频的单帧的2D CNN在仍然是不错的表现。
基于视频单帧的 2D CNN(RESNET-152[1])的性能非常接近的Sport-1M基准上当前最好的算法。这个结果是既令人惊讶和沮丧,因为2D CNN 无法建模时间和运动信息。基于这样的结果,我们可以假设,时间结构对的识别作用并不是至关重要,因为已经包含一个序列中的静态画面已经能够包含强有力的行动信息了。
研究目标: 我们表明,3D ResNets显著优于为相同的深度2D ResNets, 从而说明时域信息对于动作识别来说很重要.
16.ECO
论文标题:ECO: Efficient Convolutional Network for Online Video Understanding, ECCV 2018
github主页:https://github.com/mzolfaghari/ECO-efficient-video-understanding(提供了一个实时预测的接口)
主要贡献:
-
采用离散采样的方法减少冗余帧,实现了online video understanding,轻量化网络的处理速度可以达到237帧/秒(ECO Lite-4F,Tesla P100,UCF-101 Accuracy为87.4%)。
-
使用2D+3D卷积完成帧间信息融合。
备注:
-
以下是ECO Lite的网络结构:
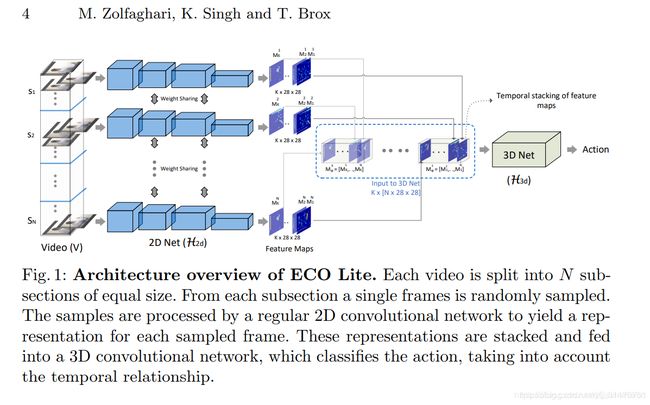
首先,将一段视频分成等长的N段,再从每一段中随机选取一帧输入网络(S1~SN);输入图像首先经过共享的2D卷积子网络得到962828的feature map,然后输入到一个3D卷积子网络中,得到对应动作类别数目的一维向量。 -
关于帧间信息融合的部分,作者还尝试了使用2D与3D卷积相结合的方案(ECO Full),如下图所示:
