利用强化学习进行股票操作实战(三)
与上一篇文章相同之处
对于交易策略,与上一篇文章相同,当发出买入指令时,一次性全部买入;当发出卖出指令时,一次性全部卖出。还没有添加加减仓操作。
模型仍然用的是DQN模型。
新增内容
-
在之前的基础上加入了交易手续费、印花税等。
-
在强化学习这个领域中,reward函数是一个需要精心设计的函数。目前暂时没有好的reward设计思路,但还是修改了之前的reward函数。(其实之前的reward的设计也是错的)
首先将第二天的股票价格的涨跌幅当做reward。
reward =(self.trend[self.t + 1] - self.trend[self.t]) / self.trend[self.t]
在股市的涨跌中,很多涨跌其实是无意义的涨跌(小幅度的上涨或小幅度的下跌回调),如果把这些因素考虑进去会造成模型难以提取到一些有效信息。因此,当涨跌幅较小时,我设置了reward进行一定程度的缩小。当涨跌程度较大时,我认为这个可能也会影响模型的判断,我同样设置了reward以一定程度缩小,核心代码如下:
if np.abs(reward)<=0.015:
self.reward = reward * 0.2
elif np.abs(reward)<=0.03:
self.reward = reward * 0.7
elif np.abs(reward)>=0.05:
if reward < 0 :
self.reward = (reward+0.05) *0.1 - 0.05
else:
self.reward = (reward-0.05) *0.1 + 0.05
对于股票的买入卖出或不操作等策略,都会影响reward。当股票卖出,r如果未来上涨了会给一个负向的reward,迫使它下次要买入;类似如果卖出,第二天下跌了就给一个正向的reward。如果股票不进行操作同样会给一个reward,但是这个reward比较小,因为我这边认为模型难以判断未来情况。核心代码如下:
if self.hold_num > 0 or action == 2:
self.reward = reward
if action == 2:
self.reward = -self.reward
else:
self.reward = -self.reward * 0.1
- 在制定交易策略时,经常需要将多个交易策略结合在一起,这样才能让交易策略稳定,风险降低。在进行回测时,我加入了均线策略。如果当日收盘价小于21日均线时,说明该股暂时有一定风险需要进行避险操作。(均线策略在模型训练时不使用)
定义了trick函数获取当日收盘价是否小于21日均线,核心代码如下:
def trick(self):
if self.df['close'][self.t] >= self.df['ma21'][self.t]:
return True
else:
return False
如果模型发出买入指令并且收盘价大于21日均线,买入。如果模型发出不操作指令,但收盘价小于21日均线,卖出。核心代码如下:
if action == 1 and self.hold_money >= (self.trend[self.t]*100 + \
max(self.buy_min, self.trend[self.t]*100*self.buy_rate)) and self.t <(len(self.trend) - self.half_window):
buy_ = True
if my_trick and not self.trick():
# 如果使用自己的触发器并不能出发买入条件,就不买
buy_ = False
if buy_ :
self.buy_stock()
if show_log:
print('day:%d, buyprice:%f, buy num:%d, hold num:%d, hold money:%.3f'% \
(self.t,self.trend[self.t], self.buy_num, self.hold_num, self.hold_money))
elif action == 2 and self.hold_num > 0:
# 卖出股票
self.sell_stock(self.hold_num)
if show_log:
print(
'day:%d, sell price:%f,total balance %f,'
% (self.t,self.trend[self.t], self.hold_money)
)
else:
if my_trick and self.hold_num>0 and not self.trick():
self.sell_stock(self.hold_num)
if show_log:
print(
'day:%d, sell price:%f,total balance %f,'
% (self.t,self.trend[self.t], self.hold_money)
)
测试结果
用000065股票的前1500天数据训练,用后面296天的数据进行测试。
结果如下:
不加均线策略的回测结果:
交易情况:
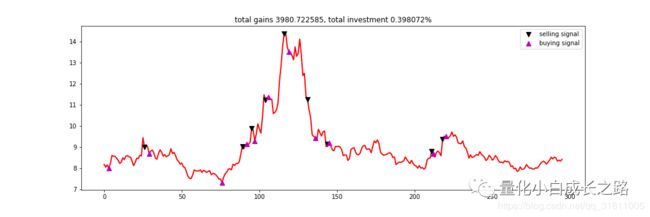
收益情况:
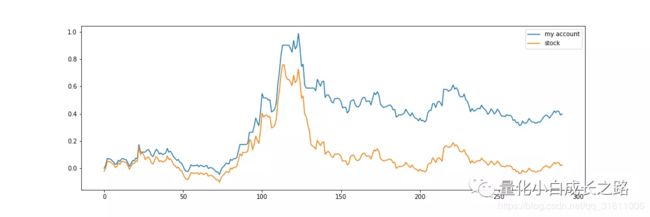
从上图我们可以发现,虽然模型跑过了原股票的涨跌,但模型的回撤还是挺大的。
加均线策略的回测结果:
交易情况:
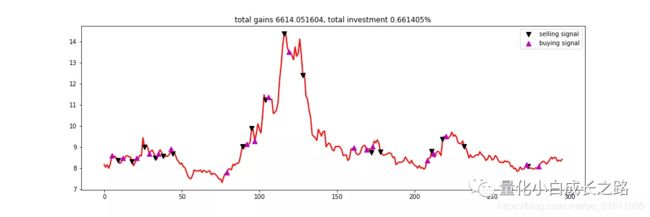
收益情况:
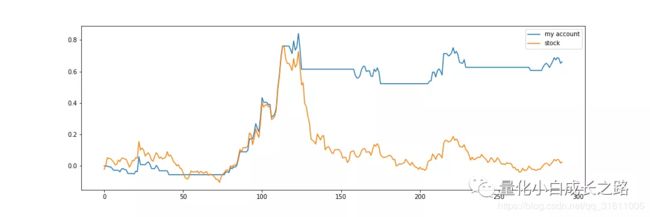
从收益情况来看,虽然账户在前期收益不太好,但是能够抓住一波较大的上涨行情,并且回测比较小。可见加入了均线策略可以较好的控制风险,并且有一个不错的收益。
参数探讨
训练轮数(代码中的max_round这个参数),在进行模型训练时,因为没有加验证集,只能主观的设置训练轮数。(不加验证集的原因在于首先验证集的涨跌情况不一定是未来的涨跌情况,很难通过验证集来表现来调整模型参数,有点玄学)。训练轮数如果太大,模型会有较大的可能把历史涨跌完全记住而比较一般性的规则就会被抛弃。如果训练轮数太小,又学不到有效信息,比较纠结的一个参数。(可能数据多了就没这个顾虑)
Batch_size,在深度学习中batch_size是一个比较重要的参考,太小loss震荡厉害,模型难以学到有效信息,太大容易overfit,在以上实验中我设置了一个比较大的batch_size。
memory_size(DQN中用来存储历史操作的参数),当这个参数较大时会存比较多的历史参数,较小时存的历史参数也会少,在以上实验中,我设置了4000.
Learning_rate,学习率也是一个比较重要的参数,在学习率的设置上还得具体结合loss设计。
以上4个参数是我在调节时候比较纠结的几个参数,这些参数比较重要的(当然其他参数也重要,但是设置一个常规的合理值就行)。强化学习的参数调节目前我也不是特别会,不能给出太多经验。大家跑代码的时候可以调整一下几个参数,然后多多思考为什么会出现这些情况,这样就能对参数有更深的理解了。
未来改进
1、在reward设计上还需要多加考虑,目前,模型还存在这操作过于频繁的缺点,很容易被短期的涨跌影响。
2、没有加减仓操作,目前还是梭哈操作。这个会在未来添加进去。
3、数据太少了,特征也不够,神经网络也需要精心设计一下。(这点可能需要等到回学校再更新,自己的电脑跑不了太复杂的网络,电脑内存也不够)
结语
目前更新有点慢,因为目前主要还是在理论学习阶段,在看别人的文献寻找一些灵感。最近看到好多人说量化在股市上不太行,但我不太信,有些人做出来但是不跟别人说,而大部分人都做不出来,并且做的人比较少。由于受到疫情的影响没办法进行实盘操作(电脑跑不起来),大概在4月份左右就可以进行实盘操作了,对于证策略的实盘收益,敬请期待。
对量化、数据挖掘、深度学习感兴趣的可以关注公众号,本人不定期分享有关这些方面的研究。

个人知乎:
https://www.zhihu.com/people/e-zhe-shi-wo/activities