Deep learning—Yann LeCun, Yoshua Bengio & Geoffrey Hintonxi
一、背景知识
1.传统方法:
- 构建一个模式识别或机器学习系统需要领域专家的帮助设计一个特征提取器
2.表示学习:
- 一系列允许机器接收原始数据并自动转换成监测或分类任务能处理的形式的方法
3.深度学习方法:
- 多层表示的表示学习方法,由简单的非线性模块组成,上一层的转换结果作为下一层的输入继续进行转换表示,提升抽象层次
4.深度学习的关键:
- 特征层不是专家工程师设计的,而是使用学习算法从数据中学到的
二、卷积神经网络基础
1.输入信号的维度:
- 1D:序列和信号,包括语言信息等
- 2D:平面图像、音频图谱等
- 3D:视频信号、立体图像等
2.卷积神经网络的关键:
- 信号的局部连接
- 共享权重
- 降采样
- 多层网络结构
3.卷积神经网络的主要层次结构:
卷积层:
- 卷积的输出被称作特征映射(Feature Map)
- 卷积核(Kernel) 共享权重
- 卷积神经网络具有稀疏交互性(Sparse Interaction)
这样设计的好处:
1.数组形式的数据(例如图像),局部数值之间具有高度相关性,形成容易被检测的各种局部图像
2. 图片和其他信号数据的局部统计特征具有位置不变性
池化层:
- 将邻域内语义相近的特征进行融合
- 常见的池化操作:Max-pool、Average-pool
- 当前一层特征组件发生位置变化或者表现变化时,降低当前层的表征变化
通常将2-3个卷积层+非线性激活函数+池化层作为一个模块;
一个模型通常含有多个这种模块
4.卷积神经网络多级结构的功能:
- 图像低级特征到高级特征:边缘->纹理->组件->物体
- 接近输入的特征图:检测边缘、简单纹理
- 层次加深:语义信息提升,理解组件或物体的表征
5.卷积神经网络的反向传播计算
- 卷积神经网络的反向传播计算和常规的深度网络计算一样简单,都是通过链式法则不断地反向计算梯度
三、经典卷积神经网络
LeNet
来自Yann lecun,卷积神经网络的开山之作,用于解决手写数字识别的视觉任务

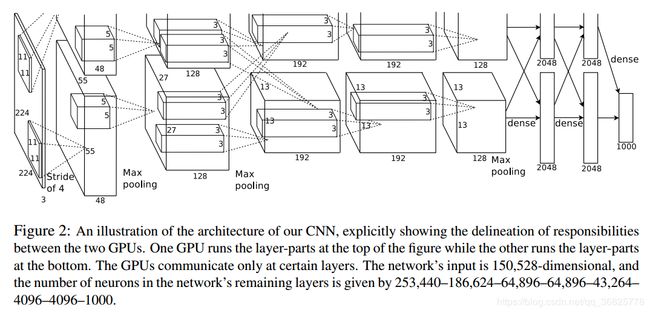
AlexNet
在2012年ImageNet竞赛中以超过第二名10.9个百分点的绝对优势一举夺冠
VGG
由牛津大学VGG组提出,2014年ImageNet竞赛定位任务第一名和分类任务第二名

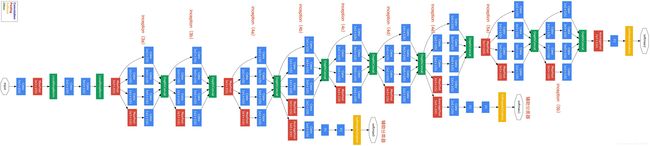
GoogLeNet
2014年的ImageNet分类任务上击败了VGG-Nets夺得冠军
ResNet
2015年何恺明推出的ResNet在ISLVRC和COCO上横扫所有选手夺冠

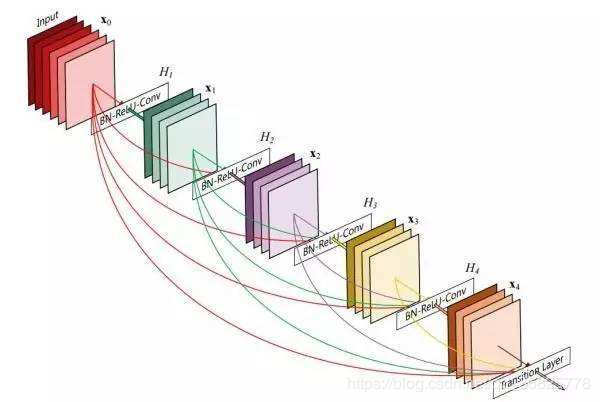
DenseNet
CVPR 2017 最佳论文 DenseNet
四、基于CNN的图像理解
人脸识别:
- 利用CNN提取人脸特征向量,与人脸库中的人脸进行判别,返回最相似的
- 经典的人脸识别框架或网络有FaceNet,DeepFace,SphereFace,etc

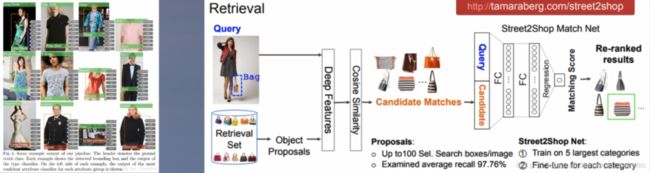
服装识别:
- 利用CNN网络,提取图像中的服装特征,单分类或多分类完成服装属性的识别
- DeepFashion数据集
五、分布式特征表示&语言处理
1.分布式特征表示
分布式特征表示是深度学习的一个核心概念:发现数据之间的语义相似性

2.深度网络两个巨大优势
1.分布式特征表示能够提升算法重新组合学习过的特征的泛化能力
2.深度网络特征表示组成的网络能够带来例如指数级深度的其他优势
示例: 预测语句中的下一个单词?
1.输入:文本内容,每个单词输入到网络中为1/n的向量
2.输出:下一个单词是什么?
3.学习:word-vector,网络挖掘深层语义特征,作为输入-输出的连接关系
从给定的文本中学习到单词的向量表示,这个向量表示也就代表了深度神经网络的一个分布式特征表示方法
3.Word-embedding
Question:
杭州 [0,0,0,0,1,0,…,0,0,0,0]
上海 [0,0,1,0,0,0,…,0,0,0,0]
宁波 [0,0,0,0,0,0,…,0,0,1,0]
北京 [0,0,0,0,1,0,…,0,0,0,1]
在语料库中,杭州、上海、宁波、北京各对应一个向量,向量中只有一个值为1,其余都为0,所有向量都表现出非常稀疏的特性,所以,能不能把词向量的维度变小?
Word-embedding:
- 将高维词向量嵌入一个低维空间,即用分布式特征表示来表示较短的词向量
- 能够较容易地分析词之间的关系

如图,将三个不同维度上的词向量同时映射到一个嵌入空间,这三个词都可以在这个二维的嵌入空间表示,这样就成功地将高维的词向量嵌入到了一个低维空间,那么在二维空间中就可以更好、更容易地分析出这三个词之间的关系
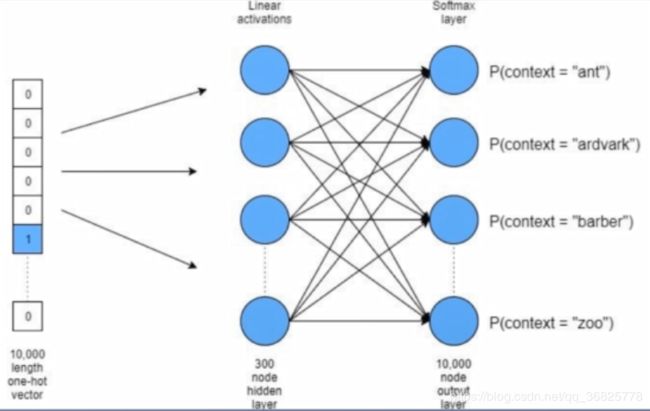
4.Word2Vec
Word2Vec:
- 简化的神经网络
- 输入时One-Hot Vector
- Hidden Layer 没有激活函数,也就是线性的单元
- Output Layer 维度 = Input Layer 维度,Softmax回归
- 训练后只需要隐藏层的权重矩阵
- 分为CBOW 和 Skip-gram 两种模型
5.N-grams
N-grams:
- 在分布式特征表示学习方法出现之间被广泛使用
- 指文本或语音中连续出现的n个"部分"
- N元语法是基于(N-1)阶马尔科夫链的一种概率语言模型
- "部分"通常包括:音素、音节、字母、单词或基本词组等
- 当N=1,2,3时,分别称为"一元语法"、“二元语法”、“三元语法”
- 还可以用于:计算字符串距离
六、循环神经网络
1.RNN
- 适用于序列化输入,如语音和语言
- 一次处理一个输入序列元素
- 维护隐单元中的“状态向量”,这个向量隐式地包含过去时刻序列元素的历史信息
- 训练过程中反传梯度在每一个时刻会增长或下降,长时间迭代后会出现梯度爆炸或消失
- 基于其网络结构和训练的特点,RNNs在预测文本中下一个字符或序列中下一个单词这个两个方面具有很好的表现
- RNNs也可以应用于更加复杂的任务中
- 一旦展开,可以把它当做一个所有层共享权值的前馈神经网络
- 理论上和经验上的证据都证明很难学习并长期保存信息

如上图所示,W回环发挥着维护隐单元中“状态向量”的作用,它能够将过去时刻的状态保留下来,在下一时刻计算时,就会考虑到前一时刻的状态是什么样子的。将回环展开来看,给定一个输入,首先通过t-1时刻得到一个输出,t-1时刻会传入t时刻,t时刻就会同时考虑当时间为t时刻和t-1时刻的计算结果,t+1时刻同理
示例:
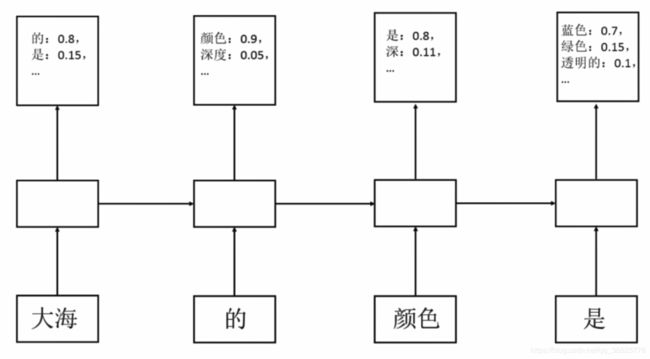
第一时刻,给定了单词“大海”,它通过卷积神经网络计算出一个向量,这个向量返回下一个词的概率,选取其中概率最大的“的”为下一时刻的词,所以第二时刻是“的”,它预测下一时刻概率最大的词是“颜色”,那么“颜色”预测下一个词概率最大的是“是”,最后“是”预测下一个词中概率最大的是“蓝色”。
因此,循环神经网络可以达到预测下一个时刻单词或者序列数据的能力
2.LSTM
- 输入门、遗忘门、记忆单元、输出门
- 遗忘门:控制是否遗忘,以一定的概率控制是否遗忘上一层的隐藏细胞状态
- 输入门:处理当前序列位置的输入
- 细胞状态:前面的遗忘门和输入门的结果都会作用于细胞状态C(t)

六、未来展望
1.无监督学习(Unsupervised Learning)

无监督学习问题可以进一步分为聚类问题和关联问题
- 聚类问题:希望在数据中发现内在的分组,比如以购买行为对顾客进行分组
- 关联问题:想发现数据的各部分之间的联系与规则,例如购买X物品的顾客也喜欢购买Y物品
2.强化学习(Reinforcement Learning)
下图是强化学习过程的一个简单展示:

强化学习的基本机制:机器会给出一个动作 α \alpha α释放到环境中,环境中会有一个状态x反馈到机器,同样,根据反馈的状态x会有一个奖赏r也给到机器,机器会根据状态x和奖赏r去不断地更新动作 α \alpha α
强化学习通常用马尔科夫决策过程来描述:
- 机器处于环境E中,状态空间为X,其中每个状态x ∈ \in ∈X是机器感知到的环境的描述
- 机器能采取的动作构成动作空间A
- 转移函数P将使得环境从当前状态按某种概率转移到另一个状态
- 转移到另一个状态时,环境会根据潜在"奖赏"函数R反馈给机器一个奖赏
- E =
3.GAN网络

生成式对抗网络(GAN网络)是深度学习或图像识别中的一个经典领域
GAN网络有两个主要组件:
- 生成器:从一个随机数中对目标图像进行不断地生成
- 鉴别器:鉴别生成的图像与真实图像之间的差距