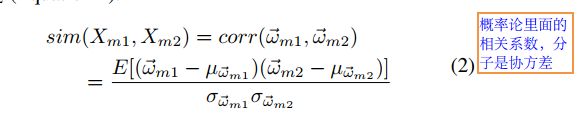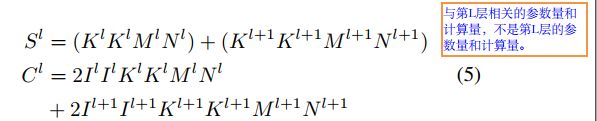Paper Reading :模型剪枝
在入坑模型压缩与加速(即求解最优子网络,)后,阅读相关论文的个人总结。
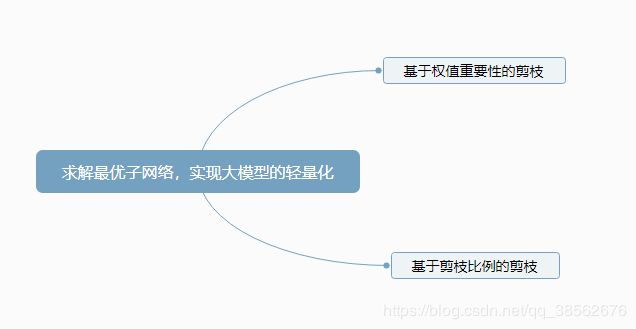
神经网络结构化剪枝方面的问题大体可以分为三个步骤:
- 剪多少?即剪枝比例的确定,也即是确定子网络结构,实际是在大模型结构的搜索空间中,求模型结构的最优解。目前的方法有人工实验逐层确定比例(偷懒整个模型就一个比例),把结构当作一个超参数使用贝叶斯优化,RL,AutoML中的NAS和Metalearning 等进行自动搜索。当然,剪多少的问题是在有大模型的框架下存在,为了摆脱这个框架依赖,可以大量使用NAS对于结构的最优解求解(不过摆脱后模型可靠性有待研究,需要CNN可解释)。得到子网络结构后可以通过训练得到子网络权重。
- 剪哪些?即剪枝评判标准,在冗余大模型上找到相对重要权值作为子网络的权值。有范数上的,距离相关性上的,BN层上的gama参数引导稀疏,泰勒展开式等。通过权值的重要性来剪掉冗余参数,实现轻量化,求解子网络的最优解。之前是通过阈值来实现确定子网络结构,不过阈值设定较为复杂,后来通过剪枝比例来确定。
- 怎么剪?即剪枝流程,在确定目标剪枝比例过后,使用什么流程进行实现。比如使用软剪枝比使用硬剪枝要好,模型容量上损失小,不依赖预训练模型。还有使用one-shot剪枝,iterative剪枝等。当然更重要的是全局剪枝和局部剪枝,全局剪枝把整个网络的所有过滤器进行排序后裁剪,如BN层gamma指导剪枝(稀疏+全局)。局部剪枝如同设置每一层剪枝比例的L1剪枝等。一般来说,全局剪枝的效果都比局部剪枝更好。因为这样很好的解决了每层冗余情况不同的问题。
但最近有研究指出继承大模型的权值的方式不是必须的(Pruning from scratch等)即合理的初始权重不重要,可以在得到最优子网络结构后通过训练得到子网络权值,并且在确定剪枝评判标准后还是要确定剪枝比例。也可能是因为最优子网络的结构要比权重更容易固定并找到,因此越来越多的研究在剪枝比例上做研究。但结构化剪枝(隐式结构搜索)还是有必要的,在过参导致的泛化强或者如:https://www.zhihu.com/search?type=content&q=%E6%A8%A1%E5%9E%8B%E5%8E%8B%E7%BC%A9%E5%89%AA%E6%9E%9D
也有人提出了一些边训练边剪枝(软剪枝)的方法,可以省去预训练的操作,但是网络的权重是在训练过程中随时变化的,按照评判标准的方法去剪枝只能在网络收敛时(需要预训练模型)才知道需要剪掉哪些部分,边训练边剪枝的方法必须要预先确定好剪枝的比例,然后再边训练边剪枝,预先定比例就是说不知道剪哪些filter,先把比例定好。对于其他比例的剪枝又要重新边训练边剪枝。
不同的剪枝比例上对结构(隐式结构)还是权重(预热权重)的依赖程度不一样。在剪枝比例相对较低时,网络对结构和权重的丢失都不是很敏感,重新训练之后都可以使得模型恢复精度(估计因为还在过参状态)。相对来说低剪枝比例下,拥有合理初始权值的网络比丢失权重信息的网络收敛更快。在剪枝比例较大时(0.9,丢失过参化),收敛快慢相反。因此,无论怎样,若存在预训练模型给出的合理权重和基于规则产生的稀疏合理结构,则至少会让收敛加快。首先要保证参数的过参化(结构),然后再保证合理的参数,加速收敛。
第一阶段:阅读综述,从综述或者硕博毕业论文入门是很好的选择。
1.深度神经网络压缩与加速综述_纪荣嵘 (很不错)
2.深度神经网络压缩综述_李青华
3.深度网络模型压缩综述_雷杰
第二阶段:剪枝论文阅读,由于非结构化剪枝无法在通用环境下进行加速和压缩,所以看的结构化剪枝比较多。
1.韩松-Deep Compression(ICLR2016) :非结构化剪枝,这篇论文主要是介绍了怎么存储加速非结构化剪枝后的网络,将低于某阈值的权重置为0,使用CSC,CSR进行存储,然后使用量化进行参数共享,最后使用霍夫曼进行编码。在专用的硬件和加速包下对于非结构化稀疏网络加速效果很好。但通用平台上,无法实现相应加速效果。
2.PRUNING_FILTERS_FOR_EFFICIENT_CONVNETS (ICLR2017):结构化剪枝,使用L1准判断每个filter的重要性,论文认为对每层的敏感度是不同的,中间的敏感度较低,可以剪掉更多filter。还提出了逐层剪枝(剪一层训练一次),和多层剪枝等剪枝策略。通过逐层剪枝可以找到最好的剪枝比例结构。在VGG和Resnet上都有实现,是比较经典的一篇文章。
3.MetaPruning (ICCV2019):将meta-learning 引入结构化剪枝,实现自动剪枝,把不同结构的编码作为输入的训练任务,传到MetaPruing辅助网络,输出相应的权值,不断训练辅助网络输出权值的能力,使得辅助网络输出的权重越来越少,以此来代替传统剪枝的不停的finetune。在搜索阶段使用遗传算法和网格搜索进行优化,找出相应条件下最佳的结构。得到结构然后再重头开始训练。这个方法在VGG和Resnet上都有实现。使用元学习的方法产生权值,是引用的HyperNetwork的方法。整个方法是一个自动搜索剪枝结构的方法,不需要人为去试验来找到最好的比例和不停的finetune。
4.Meta Filter Pruning to Accelerate Deep Convolutional Neural Networks:同样将元学习引入结构化剪枝,实现在每次剪枝(剪枝和训练相结合,每次对整个网络)时,根据当前Filter的分布(从自身范数和相关性距离)自适应地去调整评判标准,打破传统的剪枝前预先定义剪枝标准的方式,融合了多种方式,动态进行选择。借鉴的SFP进行的训练剪枝,只是在剪枝时根据Filter分布进行了相应的评判标准的选择。
5.Soft Filter Pruning (IJCAI 2018):提出了软剪枝的方法,相比之前的逐层剪枝等硬剪枝方法,不会降低模型的容量大小,因此模型会有更好的特征表达。同时,由于是训练和剪枝相结合的一种方法,每次整个模型的每层根据L2(L1会受到一些小的值的影响)实现目标剪枝比例的剪枝,可以从头边训练,边剪枝或者使用预训练模型边剪枝边finetune,从而可以省略预训练的过程。

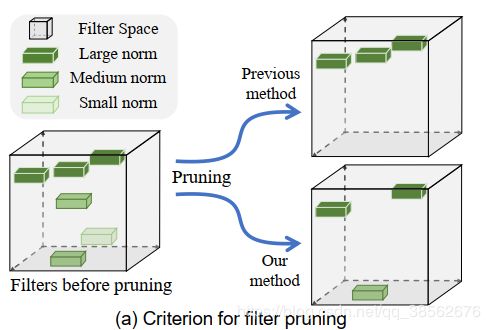
6.Filter Pruning via Geometric Median for Deep Convolutional Neural Networks Acceleration(CVPR2019):这篇文章和SFP以及Meta Filter Pruning 是一个作者,本文提出了除了范数大小以外还有过滤器之间相关性距离的评判标准,文末也采用了与L2混合的方式,直接指定L2和相关距离各剪枝多少。

7.An Entropy-based Pruning Method for CNN Compression:局部剪枝方法,最多剪掉50%。假如考虑下面的过程,从第l层feature-map(输入)要通过卷积核卷积得到计算得到l+1层的feature-map(输出),我们要得到I+1层卷积核的重要性.那么需要计算l+1层feature-map的信息熵(一个特征图对应一个过滤器).首先,将设l+1层feature-map大小为 C*h*w, 将每一个channel特征图做Global-average-pooling得到一个1*C的向量.然后,为了计算信息熵我们必须得到在不同输入下得到的1*C的集合,这里可以用整个训练集也可以用训练集的子集来作为输入,以此得到在不同输入下的对应的1*C向量,假设输入图像有n张,那么最后我们可以得到一个n*C的矩阵M,考虑矩阵M的每一列,即每个通道对应的n*1向量,要计算每个通道的信息熵,论文上的方法(按自己的理解),将这一个向量中元素值的范围进行分块,这里应该是平均分块,假如其分为m块,(可能是灰度值,256)则统计每一块中的数据个数,计算出频率,再通过信息熵公式进行计算,即:


由于每个过滤器对于不同特征提出能力不一样,论文使用n张来计算,同时为了体现过滤器的综合能力和减少计算,使用了GAP。通过计算特征图的所含信息大小来衡量过滤器的提取信息的能力,是很直观的一个标准,但在论文中的效果一般,而且只在ImageNet 上做了实验,感觉这个方法的效率不是很高,不是一种直接衡量过滤器重要性的方法,需要图片输入得出结果。尝试将此方法于SFP结合,但是在剪去过滤器的操作方面没有找到其他更好的方法,只是单纯结合,感觉创新性不大。
8.COP: Customized Deep Model Compression via Regularized Correlation-Based Filter-Level Pruning(IJCAI-19):基于特征图的剪枝,本质也是剪过滤器。这篇论文认为一些过滤器激活可以被其他所代替,进而特征图可以被其他特征图所替代的,产生的特征图与其他的过滤器产生的特征图存在线性关系,即权重之间也存在着线性关系。因此,推断出使用特征图相关性来进行剪枝。作者使用概率统计中的皮尔森相关系数,如下2式,计算权值间的相关性,将KxKxM的过滤器变成KxK形式(全连接层看做1x1xMxN),然后3式计算两个特征图的相关性。如果一个特征图与很多其他的特征图相关性较高则可以移除。因此,计算出该层特征图与该层其他特征图的相关性累加作为一个过滤器的重要性。由于整个网络相关性分布不均,有的层相关的较多,有的较少,因此采用的全局剪枝的方法。文章后来将重要性进行normalize从而全局排序。在normalize时避免采用除以l1,l2这中归一化,因为这两种会让全局剪掉过滤器个数多的层剪掉更多。同时文章还提出在不同的地方剪去相同的参数量减少的计算量和参数量不一样。因此,对特征图的全局重要性也加上了约束。同时该论文也对Depth-Separable Convolutional Layer和Residual Block
剪枝设计了相应策略。