Video Understanding(视频理解,I3D,SlowFast,Non-local)
CV领域图像已经登天很难逐渐完善,视频也开始蓬勃发展。由于早期限制于数据集和计算设备,多是从图像的2D模型直接转换成3D版本,如SIFT 3D,3D HOG,或者Dense Trajectory这种统治了很久的模型等,等到深度学习开始步入新的周期,数据集也开始扩增出现UCF101,ActivityNet,Charades,YouTube8M,Kinetics等等,也就出现了更优秀的视频理解模型3D CNN,Two-Stream Network,C3D,TSN,I3D,Slow-Fast Networks。而时下图神经网络很火,所以也有GraphLSTM,ST-Graph等等的工作。
- 目标:学出一个通用的视频表示以支撑下游任务。
- 挑战:比起图像,时序特征非常重要,并不是把2D图片堆叠起来,如何更好的利用时序信息(temporal information)。
- 下游任务:基本上图片能做的,都可以往视频上靠,比如视频推荐,视频检索,视频分割Video Segmentation,Activity Detection,Video Caption,Video Question Answering。按层次分可以有:pixel(每个像素分类类别)–region(动作发生的空间位置)–clip(动作时间段定位)–video(识别视频内容,动作分类)–language(生成视频描述)。因为视频的时序很重要,比较有特色的就是:动作和运动预测,物体移动轨迹预测,视频预测模型架构等方向。
Improved Dense Trajectory(IDT)
Action Recognition with Improved Trajectory,ICCV2013.。非神经网络模型(Pre-Deep Learning),但在视频届拥有统治级的视频理解模型。

DT方法通过网格划分的方式在图片的多个尺度上分别密集采样特征点,然后在多个空间尺度上采样能保证采样的特征点覆盖了所有空间位置和尺度,最后tracking特征点抽取特征。即DT的关键部分有3点:
- Dense。通过多尺度金字塔放缩以得到更丰富的特征(一般8个尺度足够了) 。
- Trajectory。Tracking每个尺度的密集特征点轨迹(间隔w一般为5),以理解每个部分是怎么在时序方向上进行移动的。
- HOF,HOG和MBH。方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。 HOF(Histogramsof Oriented Optical Flow)与HOG类似,是对光流方向进行加权统计,得到光流方向信息直方图。MBH( Motion Boundary Histograms)特征是分别在图像的x和y方向光流图像上计算HOG特征。计算完后,还需要进行特征的归一化,DT算法中对HOG,HOF和MBH均使用L2范数归一化。
而iDT主要改进在于对光流图像的优化,特征正则化方式的改进以及特征编码方式的改进。详见LIN大神的源码笔记
优点:iDT算法作为深度学习之前最好的行为识别算法,有着优良的效果和很好的鲁棒性。其中有很多非常值得借鉴的思路,比如相机运动引起的背景光流的消除,比如沿着轨迹提取特征的思路。
缺点:特征维度高(特征比原始视频还要大),算起来慢,延迟十几倍倍左右,无法做到实时。
DeepVideo
深度学习的早期尝试。Large-scale Video Classification with Convolutional Neural Networks,CVPR2014。

大多数的场景发生在图像中部,所以可以分两条线:
- 一条是全局的context stream,输入空间大小下采样减半的图像。
- 另一条是fovea stream只关心中心局部的信息,输入原图中心裁剪后的图像(两条线孪生,即共享同一个网络)。
- 然后通过Slow fusion模型,在整个网络中缓慢融合时间信息的两种方法之间的平衡混合,使得更高层在空间和时间维度上逐渐获得更多的全局信息。
Optical Flow based Approaches
DeepVideo是深度学习步入视频的初期研究,虽然用了深度学习,但其效果被IDT吊打近20个百分点,其最可能的原因是没有足够的利用时序信息,即它只是把一堆图片扔进网络,没有重点图片帧的关系。而为了关于捕捉时序关系,主流有两个主要的方法:1是Optical Flow based 2是3D-CNN based Approaches。
Two-stream Network
Two-Stream Convolutional Networks for Action Recognition in Videos,NIPS2014.

首先在空间部分(spatial),即单个帧图片上的外观形式,它能描绘视频的场景和目标信息。其自身静态外表是一个很有用的线索,因为一些动作很明显地与特定的目标有联系。而在时间部分(temporal),以多帧上的运动形式,表达了观察者(摄像机)和目标者的运动。但是如何更好的利用时序信息呢?光流。
- 光流是图片前后两帧中像素的移动方向,其好处在于考虑像素的移动方向后,就不需要考虑实际图片中的clothes,color,appearance,background,只要做了动作如投球,那么对于投球动作的移动是类似的,这就天然的滤去了很多无关的信息,只聚焦在动作本身上。
所以Two-stream方法巧妙的利用光流信息,即网络本身并没有对temporal建模,而是利用optical flow来体现时序上的关系,然后再输入到神经网络做映射,这种方法就取得了很好的效果。具体如上图,采用两个分支。
- 一个分支输入单帧图像,用于提取图像信息,即在做图像分类。
- 另一个分支输入连续10帧的光流(optical flow)运动场,用于提取帧之间的运动信息。
- 两个分支网络结构相同,分别用softmax进行预测,最后用直接平均或SVM两种方式融合两分支结果。
跟随Two-stream,又出现了Deeper two-stream(变得更深,网络做的更精细),two-stream+Trajectory(结合起iDT的传统轨迹方法),two-stream+LSTM(时序用LSTM),two-stream fusion(CVPR2015)等等提升的工作。
缺点:光流需要提前算(目前有方法使用自监督AE尝试学习光流),对光流的存储和读取IO都很大,在网络中也算的慢,不是最优(算了就固定了,或许端到端更好)。
Temporal Segment Networks(TSN)
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition,ECCV2016。

如何进一步提高two stream方法?由于光流信息只是前后帧像素的移动方向,1s往往就有30帧甚至更多,而一个动作的完成前后帧显然太少了。同时作者发现视频的连续帧之间存在冗余,因此想到用稀疏采样代替密集采样,也就是说在对视频做抽帧的时候采取较为稀疏的抽帧方式,这样可以去除一些冗余信息,同时降低了计算量。
TSN的结构由上图所示,一个输入视频被分为 K 段(segment),一个片段(snippet)从它对应的段中随机采样得到,然后对这些片段进行Temporal Segment,网络部分是由双路CNN组成的,分别是spatial stream ConvNets和temporal stream ConvNets。不同片段的类别得分采用段共识函数(The segmental consensus function,如图中的小绿条和小蓝条),也就是该snippet属于每个类的得分。
3D-CNN based Approaches
除了曲线救国用Optical Flow based体现时序信息,另一方面就是把2DCNN升级,变成3D-CNN based Approaches。首先就是C3D,Learning Spatiotemporal Feature with 3D Convolutional Networks,ICCV2015。

C3D,想要得到时序上的关系,那么把时序也纳入卷积,即二维卷积变三维,实现可以看作是3D版VGG,直观直白也暴力。3×3×3卷积核的均匀设置是3D ConvNets的最佳选择,模型架构如下,所有3D卷积滤波器均为3×3×3,步长为1×1×1。为了保持早期的时间信息设置pool1核大小为1×2×2、步长1×2×2,其余所有3D池化层均为2×2×2,步长为2×2×2。每个全连接层有4096个输出单元。
![]()
优点:相比其他类型的方法,C3D一次处理多帧,所以计算效率很高。
缺点:相比2D CNN,3D CNN的参数量很大,训练变得更困难,模型深度不能很深,需要更多的大量训练数据。
I3D
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset,CVPR2017.
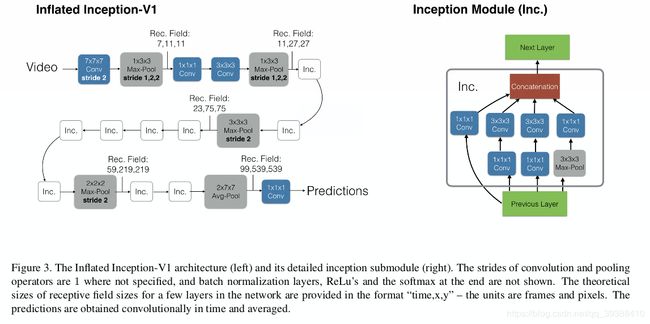
I3D,即inception-bn C2D,拓展版本的C3D。对C3D的改进
- Inflated充气,即原来针对图片的网络是3x3的卷积核,现在处理视频就直接copy3份,变成3x3x3就可以了。
- 网络更深,训练更好(训练集更大更长,用56个GPU…把训练视频的时长怼长,能够学到更丰富的动态信息)。
网络结果如上图,把two-stream结构中的2D卷积扩展为3D卷积,用了8层卷积、5层pooling、2层全连接,与C3D的区别在于这里的卷积和全连接层后面加BN,且在第一个pooling层使用stride=2,这样使得batch_size可以更大,输入是16帧,每帧112112。由于时间维度不能缩减过快,前两个汇合层的卷积核大小是1×2×2,最后的汇合层的卷积核大小是27*7。和之前文章不同的是,two-tream的两个分支是单独训练的,测试时融合它们的预测结果。
由于I3D把分类做到98%之后已经又没有什么提升空间了,所以人们转向提升效率,著名的有P3D(伪3D),S3D(分开3D),R(2+1)D(把3D变成2+1),这三种模型都考虑把3D CNN拆开,以求得到更好的效率。
- P3D用一个1×3×3的空间方向卷积和一个3×1×1的时间方向卷积近似原3×3×3卷积,通过组合三种不同的模块结构,进而得到P3D ResNet。
- S3D,将 3x3x3 卷积核都换成 1x3x3 + 3x1x1 卷积,在每个 3x1x1 卷积后加入了 Self-attention 模块 (即文中的 spatio-temporal feature gating)。
- ResNet (2+1)D,把一个3D卷积分解成为一个2D卷积空间卷积和一个1D时间卷积,改进ResNet内部连接中的卷积形式,然后,超深网络。
那么自然可以想到能否结合光流的方法,如D3D等。它的着手点是由于一般的3D方法加入光流仍有提升,说明3D CNN的学习并没有很充分,但是加入光流之后免不了速度又慢,怎么才比较好?于是D3D使用蒸馏,让3D模型在光流的监督下进行teacher-student的学习。
SlowFast Network
kaiming大神团队的工作,不同于以上所有的方法,出自仿生的新思路。SlowFast Networks for Video Recognition,2018。

人眼有两种细胞一种P细胞(Parvocellular,slow,80%)处理颜色等细节信息,M细胞(Magnocellular,fast,20%)处理移动信息。然而很多动作总是部分区域很快,而部分区域变化很慢,那么如何轻量化的不同时间分辨率双流网络,使其通用于快速及慢速动作?使用同模态同空间分辨率不同时间分辨率的双流网络(视频的帧率不一样,2和16,视频金字塔的感觉)
- SlowPathway 主要提取类别的颜色,纹理,光照变化相关的语义特征。
- FastPathway 则提取 Fast motion 特征,同时提供一个侧向给slow,可以让slow知道fast的信息
为了使网络轻量且特征维度一致,FastPathway网络很窄,则同一个stage的channel数仅为SlowPathway的八分之一。
#整个SlowFast框架
def SlowFast_body(inputs, layers, block, num_classes, dropout=0.5):
#fast和slow的输入
#不同时序方向步长(16和2,那么平均1s采两帧和15帧左右),构造了两个有不同帧率的视频片段
inputs_fast = Lambda(datalayer, name='data_fast', arguments={'stride':2})(inputs)
inputs_slow = Lambda(datalayer, name='data_slow', arguments={'stride':16})(inputs)
#输到Fast_body和Slow_body两部分
fast, lateral = Fast_body(inputs_fast, layers, block)
slow = Slow_body(inputs_slow, lateral, layers, block)
x = Concatenate()([slow, fast]) #拼接结果
x = Dropout(dropout)(x)
out = Dense(num_classes, activation='softmax')(x) #全连接输出类别
return Model(inputs, out)
#Fast pathway
def Fast_body(x, layers, block):
#inplanes其实就是channel,叫法不同
fast_inplanes = 8
lateral = [] #这个侧向会提供给Slow
#按论文中给的结构图,先conv1,pool1
x = Conv_BN_ReLU(8, kernel_size=(5, 7, 7), strides=(1, 2, 2))(x)
x = MaxPool3D(pool_size=(1, 3, 3), strides=(1, 2, 2), padding='same')(x)
#然后接4个res模块
lateral_p1 = Conv3D(8*2, kernel_size=(5, 1, 1), strides=(8, 1, 1), padding='same', use_bias=False)(x)
lateral.append(lateral_p1)
#帧率差8倍,所以通道更小来保持轻量化
x, fast_inplanes = make_layer_fast(x, block, 8, layers[0], head_conv=3, fast_inplanes=fast_inplanes)
#记录lateral,因为slow和fast的输出维度不同,需要做变换之后才能在slow融合。经过实验作者认为用5x1x1卷效果最好
lateral_res2 = Conv3D(32*2, kernel_size=(5, 1, 1), strides=(8, 1, 1), padding='same', use_bias=False)(x)
lateral.append(lateral_res2)
x, fast_inplanes = make_layer_fast(x, block, 16, layers[1], stride=2, head_conv=3, fast_inplanes=fast_inplanes)
lateral_res3 = Conv3D(64*2, kernel_size=(5, 1, 1), strides=(8, 1, 1), padding='same', use_bias=False)(x)
lateral.append(lateral_res3)
x, fast_inplanes = make_layer_fast(x, block, 32, layers[2], stride=2, head_conv=3, fast_inplanes=fast_inplanes)
lateral_res4 = Conv3D(128*2, kernel_size=(5, 1, 1), strides=(8, 1, 1), padding='same', use_bias=False)(x)
lateral.append(lateral_res4)
x, fast_inplanes = make_layer_fast(x, block, 64, layers[3], stride=2, head_conv=3, fast_inplanes=fast_inplanes)
x = GlobalAveragePooling3D()(x)
return x, lateral
#Slow pathway
def Slow_body(x, lateral, layers, block):
#lateral会提供给slow,让slow可以知道fast的处理结果
slow_inplanes = 64 + 64//8*2
x = Conv_BN_ReLU(64, kernel_size=(1, 7, 7), strides=(1, 2, 2))(x)
x = MaxPool3D(pool_size=(1, 3, 3), strides=(1, 2, 2), padding='same')(x)
x = Concatenate()([x, lateral[0]])
#帧率差8倍,所以通道比fast多乘8
x, slow_inplanes = make_layer_slow(x, block, 64, layers[0], head_conv=1, slow_inplanes=slow_inplanes)
x = Concatenate()([x, lateral[1]])
x, slow_inplanes = make_layer_slow(x, block, 128, layers[1], stride=2, head_conv=1, slow_inplanes=slow_inplanes)
x = Concatenate()([x, lateral[2]])
x, slow_inplanes = make_layer_slow(x, block, 256, layers[2], stride=2, head_conv=1, slow_inplanes=slow_inplanes)
x = Concatenate()([x, lateral[3]])
x, slow_inplanes = make_layer_slow(x, block, 512, layers[3], stride=2, head_conv=1, slow_inplanes=slow_inplanes)
x = GlobalAveragePooling3D()(x)
return x
完整代码的逐行解读:https://github.com/nakaizura/Source-Code-Notebook/tree/master/SlowFast
Non-local Neural Networks
非局部神经网络,主要解决的是如何捕获更多的帧,更大的视野,网络中更长期依赖关系。它也希望handle temporal information,挖掘连续frames pixel-level之间的relation,所以可以看作是3D CNN的一个扩展。直观来说,由于3D CNN的感受野是有限区域,非局部操作在一个位置的计算响应是输入特性图中所有位置的特征的加权总和,其本质应该是self-attention:
y i : = 1 C ( x i ) ∑ j f ( x i , x j ) g ( x j ) y_i:=\frac{1}{C(x_i)}\sum_j f(x_i,x_j)g(x_j) yi:=C(xi)1j∑f(xi,xj)g(xj)i是输出特征图的其中一个位置,通用来说这个位置可以是时间、空间和时空。j是所有可能位置的索引,x是输入信号,可以是图像、序列和视频,通常是特征图。y是和x尺度一样的输出图,f是配对计算函数,计算第i个位置和其他所有位置的相关性,g是一元输入函数,目的是进行信息变换,C(x)是归一化函数,保证变换前后整体信息不变。
所以直接算Attention的部分:
def forward(self, x):
'''
:param x: (b, c, t, h, w)
:return:
'''
batch_size = x.size(0)
#嵌入权重变换,在嵌入空间中算高斯距离。
#代表注意力V,Q,K的g,theta,phi都要做同样的操作
g_x = self.g(x).view(batch_size, self.inter_channels, -1)
g_x = g_x.permute(0, 2, 1)
theta_x = self.theta(x).view(batch_size, self.inter_channels, -1)
theta_x = theta_x.permute(0, 2, 1)
phi_x = self.phi(x).view(batch_size, self.inter_channels, -1)
f = torch.matmul(theta_x, phi_x)#然后theta_x, phi_x做内积,算像素相似度
f_div_C = F.softmax(f, dim=-1)#得到权重
y = torch.matmul(f_div_C, g_x)#分配权重给图像的相应位置
y = y.permute(0, 2, 1).contiguous()
y = y.view(batch_size, self.inter_channels, *x.size()[2:])
W_y = self.W(y)#最后还要一个1x1恢复通道,使输入输出大小一致
z = W_y + x #最后是一个残差连接
return z
完整代码的逐行解读:https://github.com/nakaizura/Source-Code-Notebook/tree/master/Non-local
原paper:https://arxiv.org/abs/1711.07971
原code:https://github.com/facebookresearch/video-nonlocal-net
I3D-GCN
发自ECCV2018的文章,以往对目标进行tracking都是考虑目标本身,而没有注意目标之间的交互,这往往来说是很重要的。恰逢GCN激起图领域的涟漪,具体结构如下图:

即先进行目标检测,再构造两个图来描述N个物体特征间关系,用Graph Convolutions抽特征。其中为了让图能学到时空特性,即不同物体在顺序连续帧间的空间关系,作者对帧t 和 帧t+1 里的所有物体区域计算IoU,单向进行映射 t->t+1,然后把 IoU 的值赋给节点间的edge,最后对同一个节点的所有edge进行归一化。
Spatial-Temporal Graph
Spatial Temporal Graph Convolutional Networks for Skeleton-Based Action Recognition

一图胜千言。。关节点是 graph nodes,人体结构 以及 时间 的自然连接作为 graph 的 nodes,然后先在2D上GCN,再在时序上GCN。(需要注意的这里有个关于领域子集的分配策略,判断节点属于的子集)
code:https://github.com/yysijie/st-gcn