SSD+caffe︱Single Shot MultiBox Detector 目标检测(一)
作者的思路就是Faster R-CNN+YOLO,利用YOLO的思路和Faster R-CNN的anchor box的思想。
.
0 导读
(本节来源于BOT大赛嘉宾问答环节 )
SSD 这里的设计就是导致你可以一下子可以检测 8 张图,FasterRCNN 一下子只能检测 1 张图片,这样的话会导致会有 8 张图片的延迟。但是我觉得如果你用 FasterRCNN 的话,你可以优化前面的这个,在实际使用的时候可以把这个网络简化一下。YOLO 做了这样一些设计,在做 3×3×256 的运算之前先有一个 1×1×128 的卷积层,这样的话,它会让你下一层的运算量减少一半。就是说前面一层输出的维数变为一半,下一层再做大卷积和的时候,这样的运算更小了。
SSD 的输入是 300×300,其实这个图片的大小和处理速度也是有很大的影响。比如说如果你要检测一个很大的物体的话,我们觉得在计算的时候并不需要像 FasterRCNN 那样有成就感。如果你去看卷积的运算过程的话,这个图片大小是和运算量有一个关系的。就是你实际做检测的话,可以尽量的去压缩输入的大小,得到速度的提升,另外一方面就是这种网络结构。最近谷歌有专门讲检测的速度和精度的平衡。
- FasterRCNN 比 SSD 要好一些?
SSD 很多训练的策略是非常有效的,因为 FasterRCNN 已经出得非常久了,这个检测效果我觉得可以针对实际场景去看一下这几个框架在做训练的时候采用了一些数据增强的方法,包括一些训练之类的,我觉得这个对于检测效果影响也非常大。像 SSD 最开始其实效果并没有这么好,并没有这么高。但是它通过一些策略,让它训练的精度达到了这个效果。
.

1 SSD:Single Shot MultiBox Detector
较多参考于:SSD
.
1.1 优势
- 关键的数据增广,采样策略在分类期间使用了pooling,比人为设置更鲁棒。
- 更多特征图的提升 ,使用底层特征图来预测边界框输出。
- 更多的默认框形状效果更好,默认情况下,每个位置使用6个默认框。如果我们删除具有1/3和3宽高比的框,性能下降0.9%。通过进一步移除1/2和2纵横比的框,性能再下降2%。使用多种默认框形状似乎使网络预测任务更容易。
- Atrous算法更好更快
- 小物体检测的检测性能较好。
.
1.2 网络结构
该论文采用 VGG16 的基础网络结构,使用前面的前 5 层,然后利用 astrous 算法将 fc6 和 fc7 层转化成两个卷积层。再格外增加了 3 个卷积层,和一个 average pool层。不同层次的 feature map 分别用于 default box 的偏移以及不同类别得分的预测(惯用思路:使用通用的结构(如前 5个conv 等)作为基础网络,然后在这个基础上增加其他的层),最后通过 nms得到最终的检测结果。
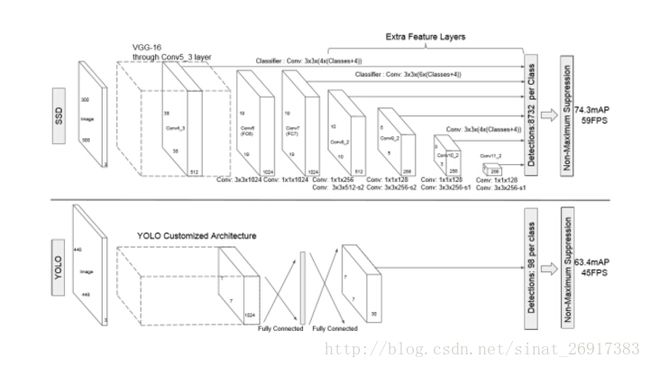
允许能够检测出不同尺度下的物体: 在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。
低层的特征图feature map对局部进行描述的更为精确,但是高层的内容对全局的信息描述更准,看不同的需求。而SSD就是局部+整体结合的方式。
.
1.3 多尺度feature map
得到 default boxs及其 4个位置偏移和21个类别置信度。按照不同的 scale 和 ratio 生成,k 个 default boxes,这种结构有点类似于 Faster R-CNN 中的 Anchor。
.
1.4 图像增强
为了模型更加鲁棒,需要使用不同尺寸的输入和形状,作者对数据进行了如下方式的随机采样:
- 使用整张图片
- 使用IOU和目标物体为0.1, 0.3,0.5, 0.7, 0.9的patch (这些 patch 在原图的大小的 [0.1,1] 之间,
相应的宽高比在[1/2,2]之间) - 随机采取一个patch
当 ground truth box 的 中心(center)在采样的 patch 中时,我们保留重叠部分。在这些采样步骤之后,每一个采样的 patch 被 resize 到固定的大小,并且以 0.5 的概率随机的 水平翻转(horizontally flipped)。用数据增益通过实验证明,能够将数据mAP增加8.8%。

.
2 SSD测评结果
SSD在精度和速度方面胜过最先进的对象检测器。我们的SSD500型号在PASCAL VOC和MS COCO的精度方面明显优于最先进的Faster R-CNN [2],速度快了3倍。 我们的实时SSD300模型运行在58 FPS,这比当前的实时YOLO[5]更快,同时有显著高质量的检测。
本次参考:翻译SSD论文(Single Shot MultiBox Detector),仅作交流~
.
2.1 实验调参
我们的实验基于VGG16 [14]网络,在ILSVRC CLS-LOC数据集[15]预训练。类似于DeepLab-LargeFOV [16],我们将fc6和fc7转换为卷积层,从fc6和fc7两层采样得到参数,将pool5从2×2-s2更改为3×3-s1,并使用atrous算法填“洞”。我们删除了所有的dropout层和fc8层,使用SGD对这个模型进行fine-tune,初始学习率 ,0.9 momentum, 0.0005 weight decay, batch大小32。每个数据集的学习速率衰减策略略有不同,稍后我们将描述详细信息。
.
2.2 PASCAL VOC2007测试集检测结果

Fast和Faster R-CNN输入图像最小尺寸为600,两个SSD模型除了输入图像尺寸(300*300和500*500),其他设置与其相同。很明显,较大的输入尺寸得到更好的结果。
增加输入尺寸(例如从300×300到500×500)可以帮助改善检测小对象,但是仍然有很大改进空间。积极的一面是,我们可以清楚地看到SSD在大对象上表现很好。并且对于不同的对象宽高比非常鲁棒,因为我们对每个特征图位置使用各种长宽比的默认框。
.
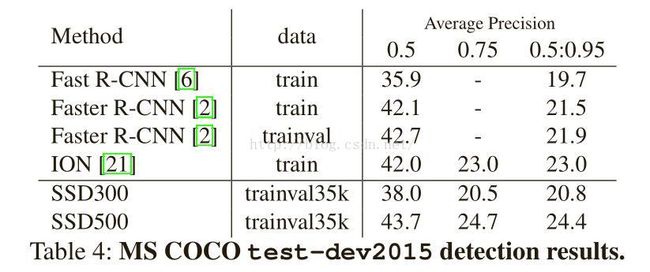
2.3 MS COCO数据集
使用trainval35k [21]来训练我们的模型。由于COCO有更多的对象类别,开始时的梯度不稳定。
通过将图像大小增加到500×500,我们的SSD500在两个标准中都优于Faster R-CNN。此外,我们的SSD500模型也比ION[21]更好,它是一个多尺寸版本的Fast R-CNN,使用循环网络显式模拟上下文。
.
2.4 ILSVRC
目前保留的是ILSVRC2015的SSD-500*500,ILSVRC2016的SSD-300*300。
.
2.5 SSD500-SSD300对比
SSD在精度上要高于SSD300,不过FPS小了不少。相对来说,SSD性价比比较好。

.
3 caffe实现SSD
3.1 安装
git clone https://github.com/weiliu89/caffe.git
cd caffe
git checkout ssd一些教程说要把原来caffe文件夹删掉,但是笔者实践时候,可以不用。
同时,Makefile.config的设置,可以直接拷贝主caffe目录,然后:
make -j8
# Make sure to include $CAFFE_ROOT/python to your PYTHONPATH.
make py
make test -j8
make runtest -j8.
3.2 已有的模型
在weiliu89/caffe开源了三款数据集的fine-tuning模型,PASCAL VOC models、COCO models、ILSVRC models。
PASCAL VOC models:20分类
COCO models:80分类
ILSVRC models:1000分类
.
4、model zoo
除了weiliu89/caffe还有另外哪些训练好、开源的:
交通信号灯SSD:
https://github.com/jinfagang/TrafficLightsDetection
SSD: Signle Shot Detector 用于自然场景文字检测
SSD-tensorflow的一个版本的github:
https://github.com/balancap/SSD-Tensorflow