Python里sort()的排序算法--Timsort简介
学习计算机的肯定对各种排序算法都很了解,这里说一下,常用的排序算法有冒泡排序,插入排序,快速排序等,
而Python里的sort排序是一种名为Timsort的排序方法,其时间复杂度为O(n log n),而且这是一种快速的稳定的排序方法。它的发明者是Tim Peters在2001年为Python创造的一种排序算法。下图是Timsort的时间复杂度的介绍,可以看到Timsort排序在各方面都是最优的。而且Timsort是在C语言中实现的,因此Timsort排序的性能是毋庸置疑的。

一个算法的稳定主要是:在假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。通俗的来说,就是两个相同的值,在排序后位置不发生交换,就是稳定的,否则就不稳定。在一些条件下,稳定和不稳定也是相对的。
Timsort在排序长度低于64的时候采取:插入排序 。高于64的时候采取Timsort是一种改良的归并排序。下图是插入排序的时候的算法:
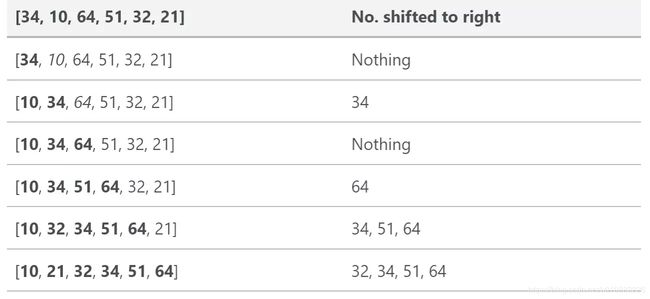
正常的归并排序如下:
如 设有数列{6,202,100,301,38,8,1}
初始状态:6,202,100,301,38,8,1
第一次归并后:{6,202},{100,301},{8,38},{1},比较次数:3;
第二次归并后:{6,100,202,301},{1,8,38},比较次数:4;
第三次归并后:{1,6,8,38,100,202,301},比较次数:4;
总的比较次数为:3+4+4=11;
逆序数为14;
而Timsort的算法首先遍历列表,查找升序和降序的部分(Run),由于现实中的很多数据都是排好序的,Timsort利用了这一特点。Timsort排序的输入的单位不是一个个单独的数字,而是一个个的分区。其中每一个分区叫一个“run“(图1)。针对这个 run 序列,每次拿一个 run 出来进行归并。每次归并会将两个 run 合并成一个 run。每个run最少要有2个元素。Timesor按照升序和降序划分出各个run:run如果是是升序的,那么run中的后一元素要大于或等于前一元素(a[lo] <= a[lo + 1] <= a[lo + 2] <= ...);如果run是严格降序的,即run中的前一元素大于后一元素(a[lo] > a[lo + 1] > a[lo + 2] > ...),需要将run 中的元素翻转(这里注意降序的部分必须是“严格”降序才能进行翻转。因为 TimSort 的一个重要目标是保持稳定性stability。如果在 >= 的情况下进行翻转这个算法就不再是 stable)。
如果降序,则翻转序列:

划分run和优化run长度以后,然后就是对各个run进行合并。合并run的原则是 run合并的技术要保证有最高的效率。当Timsort算法找到一个run时,会将该run在数组中的起始位置和run的长度放入栈中,然后根据先前放入栈中的run决定是否该合并run。Timsort不会合并在栈中不连续的run。
Timsort会合并在栈中2个连续的run。X、Y、Z代表栈最上方的3个run的长度(图2),当同时不满足下面2个条件是,X、Y这两个run会被合并,直到同时满足下面2个条件,则合并结束:
(1) X>Y+Z
(2) Y>Z
例如:如果X 合并run步骤 合并2个相邻的run需要临时存储空闲,临时存储空间的大小是2个run中较小的run的大小。Timsort算法先将较小的run复制到这个临时存储空间,然后用原先存储这2个run的空间来存储合并后的run(图3)。 临时存储空间,让Timsort排序的空间复杂度为o(n) run合并过程1 图5 run合并过程2
简单的合并算法是用简单插入算法,依次从左到右或从右到左比较,然后合并2个run。为了提高效率,Timsort用二分插入算法(binary merge sort)。先用二分查找算法/折半查找算法(binary search)找到插入的位置,然后在插入。
例如,我们要将A和B这2个run 合并,且A是较小的run。因为A和B已经分别是排好序的,二分查找会找到B的第一个元素在A中何处插入(图4)。同样,A的最后一个元素找到在B的何处插入,找到以后,B在这个元素之后的元素就不需要比较了(图5)。这种查找可能在随机数中效率不会很高,但是在其他情况下有很高的效率。