MSDNet(Multi-Scale Dense Convolutional Networks)算法笔记
论文:Multi-Scale Dense Convolutional Networks for Efficient Prediction
论文链接:https://arxiv.org/abs/1703.09844
代码地址:https://github.com/gaohuang/MSDNet
DenseNet的一作康奈尔大学黄高的作品,先来聊聊文章的出发点。对于分类网络的测试而言,有些输入图像是网络容易分类的,有些输入图像是网络难分类的。以softmax输出为例,假设一个2分类的例子,如果一张图像属于两个类的概率分别是0.01和0.99,和一张图像属于两个类的概率分别是0.51和0.49,显然相比之下前者更容易分类。那么从这个点出发,能不能对于简单图像仅采用浅层的速度较快的网络来分类,而对于难分类图像再采用深层的速度慢一点的网络来分类。当然可以,直观的做法可能是一张图像先过简单网络,如果输出概率能有较大把握判断该图像的类别,那么就直接输出这个类别。如果输出概率没有较大把握判断该图像的类别(比如概率小于某个阈值),那么就把这张图像再过一下深层网络。但是这样做有两个问题:1、对于简单图像而言却是可以节省时间,但是对于难分类的图像显然也增加了时间(可能要过好几个网络,最后的结果也不一定正确)。2、如果一张图像是难分类的图像,那么就要过好几次网络才能得到结果,而在过后面几个网络的时候,前面网络所提取的特征都没利用到。因此作者就提出了Multi-Scale Densenet网络来解决这些问题,主要思想就是在一个网络中有多个分类出口,对于简单图像可以直接从前面某个分类出口得到结果,而难分类的网络可能要到网络后面的某一层才能得到可靠的结果,而且这些分类出口并不是简单在一个网络的一些层直接引出,毕竟浅层特征直接用来分类的效果是非常差的,因此采用的是multi-scale的特征。
因此Multi-Scale Densenet(MSDNet)主要由两个核心结构组成:multi-scale feature maps and dense connectivity。这两个核心结构的作用如下:The multi-scale feature maps produce high-level feature representations that are amenable to classification early on. The dense connectivity pattern allows the network to reuse and bypass existing features from prior layers and ensures high accuracies in later layers. 其实还有一个核心结构:intermediate classifiers,多个分类器出口使得网络可以灵活地处理输入图像。
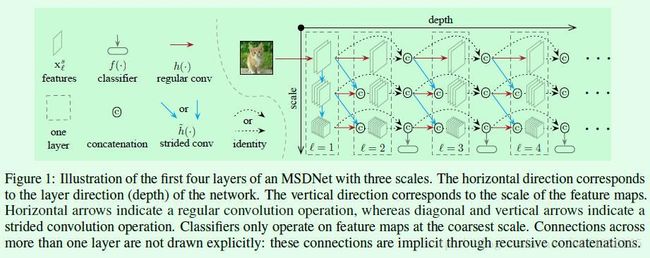
在Figure1中展示了scale为3的4层MASNet网络,右半部分的每一列代表网络的一层,因此一共有4层。如果只看第一层的话就很像DenseNet。各种符号的含义在图中也标的很清楚了,尤其可以看出示意图有接出了三个分类器,分别是在第2,3,4层的coarsest scale部分接出来的,也就是最下面那个scale。以第3层的分类器为例,它的输入包括scale=3时候的l=1,2,3的输出的cancate结果。这个strided convolution代表什么意思?从文中的这句话Feature maps at coarser scales are obtained via down-sampling. coarser scale表示Figure1中沿着scale箭头越往下的scale,因此可以看出strided convolution应该就是下采样的操作。
文中出现两个贯穿全文的名词:anytime prediction和budgeted batch classification。这里捎带解释下,不明白的话也不大影响文章核心思想的理解。在anytime prediction中,对于每一张输入图像x都有一个计算资源限制条件(computational budget)B>0,相当于每次给模型输入一张图像,然后根据计算资源限制来给出预测结果。而在budgeted batch classification中是对每一个batch的输入图像都有一个computational budget B>0,假设这个batch里面包含M张图像,那么可能简单图像的耗时要小于B/M,而复杂图像的耗时要大于B/M。对上面这两个词有不同理解的同学欢迎讨论。在文中测试的时候作者的M取值是128(ImageNet数据集)和256(CIFAR-100数据集)。
Figure2是对网络比较详细的介绍。左边的图只画出了右边表格中的最右下角(l=4,s=3)那个feature map的计算过程,毕竟如果再加上其他连接,那么这个图就太复杂了,因此那些连接都是存在的,类似DensNet。从l=4,s=3这一层的这个scale的特征计算可以看出,输入既包括上一个scale的前面层结果,也包括这个scale的前面层结果。可以结合Figure1来看具体每一层每个scale的输入是由哪些部分组成的,尤其要注意Figure1中的cancate操作,很多连线都是从concate后的结果直接引到下一个cancate操作的,那样就相当于concate了许多feature map。

明白了网络的大致组成,顺便看个细节,那就是分类器是怎么组成的呢?Each classifier consists of two convolutional layers, followed by one average pooling layer and one linear layer.
另外,具体这个MSDNet要怎么做分类呢?就按作者文中介绍的按照输入图像是一张还是一个batch的分别看:在anytime predicition中,具体由哪个classifier来输出结果呢?答案是:During testing in the anytime setting we propagate the input through the network until the budget is exhausted and output the most recent prediction. 在batch budget classification中,具体由哪个classifier来输出结果呢?答案是:In the batch budget setting at test time, an example traverses the network and exits after classifier fk if its prediction confidence (we use the maximum value of the softmax probability as a confidence measure) exceeds a pre-determined threshold k。简单讲就是设了一个概率阈值,当某个分类器的概率超过了这个阈值,就可以直接输出了。
损失函数如下,L(fk)是logistic loss function,其中fk表示第k个分类器,D代表训练数据集。
![]()
文中还介绍了一些可以进一步减少计算量的方法:First, it is inefficient to maintain all the finer scales until the last layer of the network. One simple strategy to reduce the size of the network is by splitting it into S blocks along the depth dimension, and only keeping the coarsest (S - i + 1) scales in the ith block. 通过网络结构可以看出,较大scale的feature map算是浅层特征,对于分类几乎没有帮助,因此只需要得到每层最后那个scale的特征用来分类即可。
实验结果:
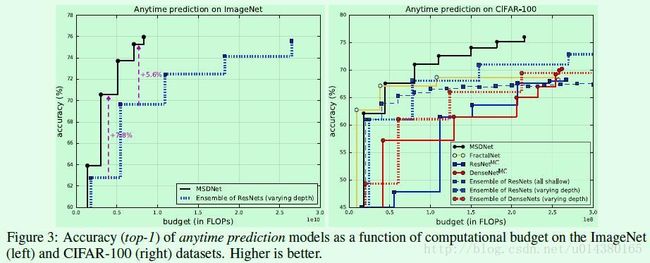
Anytime Prediction:左边是在InageNet(2012)数据集上的结果,右边是在CIFAR-100数据集上的结果。横坐标就是computational budget,也就是计算复杂度的标识。
Budgeted Batch Classification:Figure5的右图,包含3条不同网络深度的MSDNet结果,可以看出在average budget比较小的时候,MSDNet的效果要远远好于ResNet和DenseNet,这就证明了用原网络低层的高分辨率特征直接做分类是行不通的(应该要采用类似本文中的multi-scale feature)。
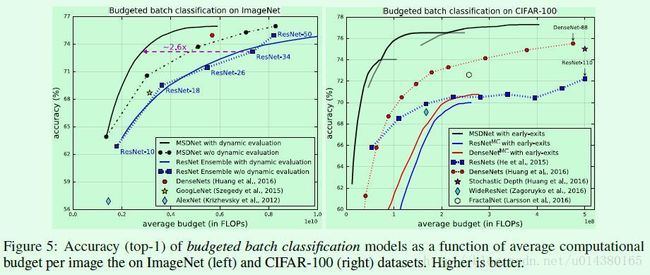
Figure4是作者在实验过程中展示的几张容易分类的图像和难分类的图像。其实和人眼分辨的道理一样,对于第一行的图像很容易知道是红酒或者火山,但是相比之下第二行的图像就要难一点。

下面这个实验结果图是在CIFAR-100数据集上做的,主要用来验证MSDNet的3个核心组成(Dense Connectivity,Multi-Scale feature map,Multiple Classifiers)的效果。可以看出如果移除了Dense Connetivity,会影响整体的准确率。而移除Multi-Scale feature map主要影响lower budget部分的准确率(还是浅层特征的锅)。
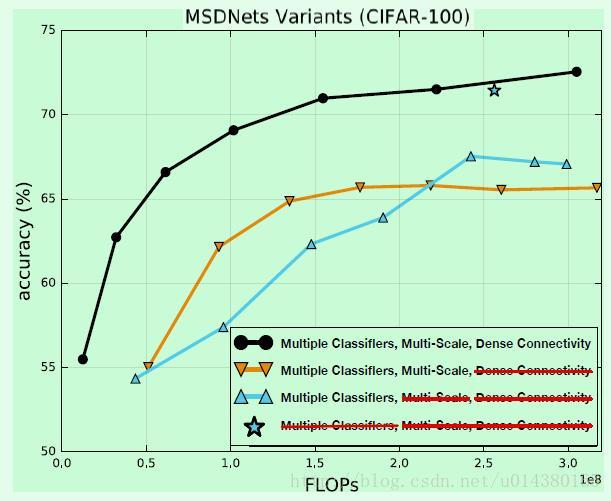
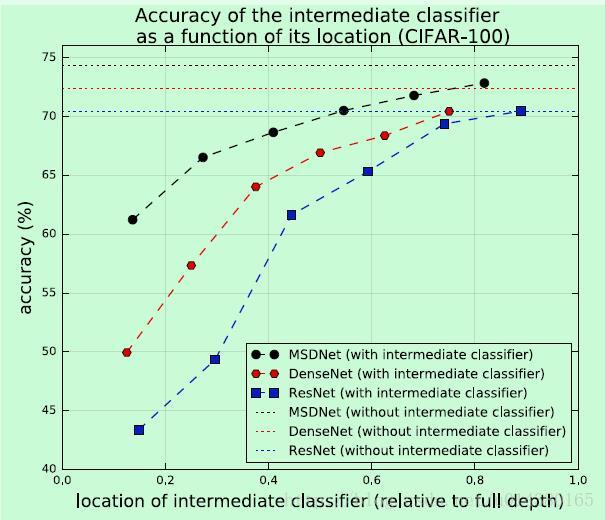
下图是关于在不同的网络中引入intermediate classifier的结果。红蓝虚线的对比差别主要在于蓝线没有dense connectivity,而红黑虚线的对比差别主要在于红线没有multi-scale feature map结构。
接下来如果有时间看看代码,再对以上内容作补充。