【论文阅读】DA-RNN & GeoMAN & DSTP-RNN
NARX 和 注意力机制相关的论文,这三个论文的模型很像,放一起比较一下
NARX: Nonlinear autoregressive exogenous(NARX)模型是一种基于时间序列以及多重驱动(外生)序列的当前值和过去值进行预测的模型
DA-RNN
原始论文:A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction
转载来源:DARNN:一种新的时间序列预测方法——基于双阶段注意力机制的循环神经网络 来源:知乎
基于seq2seq模型(encoder decoder 模型),并结合注意力机制的一种时间序列预测方法。与传统的注意力机制只用在解码器的输入阶段,即对不同时刻产生不同的context vector不同,该文还在编码器的输入阶段引入了注意力机制,从而同时实现了选取特征因子(feature selection)和把握长期时序依赖关系(long-term temporal dependencies)。
双阶段:第一阶段,使用注意力机制自适应地提取每个时刻的相关feature;第二阶段,使用另一个注意力机制选取与之相关的encoder hidden states。

第一阶段
使用当前时刻的输入,以及上一个时刻编码器的hidden state,来计算当前时刻编码器的hidden state,其中m是编码器的size。更新公式可写为:
对于这个问题,我们可以使用通常的循环神经网络vanilla RNN或LSTM以及GRU作为。但为了自适应地选取相关feature,作者在此处引入了注意力机制。
可以根据上一个时刻编码器的hidden state和cell state计算得到:
其中是hidden state与cell state的连接(concatenation)。我的理解是与类似,只不过少了一个需要训练的参数。 该式即把第个driving series与前一个时刻的hidden state和cell state线性组合,再用tanh激活得到。
得到后,再用softmax函数将其归一化:
对每个时刻的输入,为其中的每个影响因子赋予一定的注意力权重(attention weight)。衡量了时刻的第个feature的重要性。更新后的为
使用更新后的作为编码器的输入,得到了更新后的,作者又选取了LSTM作为编码器
通过上述的input attention机制,编码器能够focus on其中重要的驱动因子,而不是对所有因子一视同仁。
使用temporal attention的解码器
我将解码器中的时间序列下标标注为,以与编码器种的下标区分。
第二阶段的解码器注意力机制设计类似于传统的attention based seq2seq model。基本的出发点为,传统的seq2seq模型中,编码器输出的context vector基于最后时刻的hidden state或对所有hidden state取平均。这样输出的context vector对所有时刻均相同,无法起到只选取相关时刻编码器hidden state的功能。我们自然地想到可以在不同时刻采用不同的context vector。类似于seq2seq,最简单的办法是对所有时刻的取加权平均,即:
的设计类似于Bahanau的工作,基于前一个时刻解码器的hidden state和cell state计算得到:
解码器的输入是上一个时刻的目标序列和hidden state以及context vector,即
作者在这里设计了来combine与的信息,即
然后
类似于编码器的最后一个公式,这里仍旧使用LSTM作为。
Final prediction
回顾一下非线性自回归(Nonlinear autoregressive exogenous, NARX)模型的最终目标,我们需要建立当前输入与所有时刻的输入以及之前时刻的输出之间的关系,即:
通过之前编码器解码器模型的学习,我们已经得到了解码器的hidden state 和context vector,与。我们再使用一个全连接层对做回归,即
这样可以得到最终的预测
GeoMAN
原始论文:GeoMAN: Multi-level Attention Networks for Geo-sensory Time Series Prediction
转载来源:Selcitram 链接:https://zhuanlan.zhihu.com/p/43522781 来源:知乎

Local Spatial Attention
给定第 个传感器的第 维local特征向量 ,使用attention机制来自适应的获取目标序列与每个local特征之间的动态关联性。
其中 是需要学习的参数。 为特征向量的attention权重,由encoder阶段中输入的特征向量与历史状态决定(如 ),这个权重衡量了传感器内部收集的不同特征的重要性高低。
接着,就可以计算Local Spatial Attention的输出向量了,其中 代表第 个传感器在第 时刻的第 维特征取值。
Global Spatial Attention
这个attention机制是建立在各个传感器之间的时空序列数据都互有关联的前提上。直接使用全部传感器数据序列会导致计算花费过高、降低模型表现,因为可能存在许多不相关联的序列,所以在这个阶段需要先算出各个传感器之间的关联性。
其中 是需要学习的参数,这种attention机制可以自适应地选择合适的的相关传感器数据序列。attention权重的计算方式如下。
其中 用于衡量传感器 之间的地理关联性,如地理距离的倒数。 则是可调的超参,如果 很大这一项将会使attention权重变得类似于计算地理位置相似性。作者还指出,当 很大时,可以用与目标传感器距离最近的前 个传感器作为近似代替。
接着,就可以计算Global Spatial Attention的输出向量了
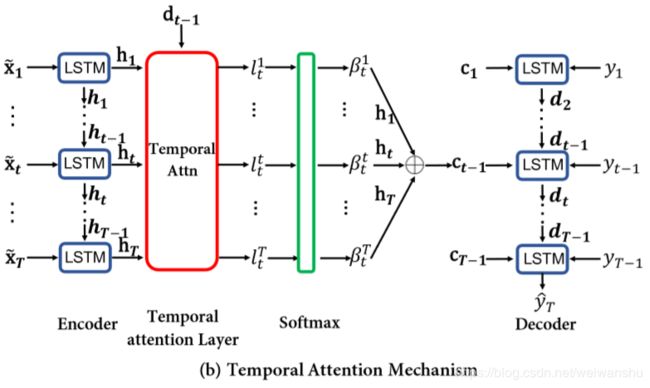
Temporal Attention
Cho等人在On the properties of neural machine translation: Encoder-decoder approaches一文指出Encoder-Decoder结构的性能会随着Encoder长度的增长而迅速下降,所以需要在Decoder中也需要引入attention机制来解决这个问题。attention机制可以使Decoder自适应地选取Encoder中的应着重关注隐藏层状态。Decoder中t时刻的attention权重计算如下。
其中 是需要学习的参数。
External Factor Fusion
这一步是在Decoder中融合外部因素,这些因素包括time features, meteorological features, SensorID, POIs&Sensor networks,需要注意的是这些外部因素中的大部分都是离散的,所以作者将这些特征映射为低维向量分别送入不同的embedding层中。作者还使用了POIs密度作为POIs的特征,Sensor networks采用的是比较简单的传感器网络结构特征(例如十字路口数量与邻近传感器数量)。由于未来的天气信息难以获取,所以作者采用的是天气预报信息。
Encoder-decoder & Model Training
对于 时刻,Encoder的输入为
并采用
的方式更新隐藏状态,其中 表示LSTM unit。
在Decoder阶段,用的是另外一种计算公式
来更新Decoder的隐藏状态,其中 就是前面融合的外部因素特征向量, 是 对 时刻的预测值,其计算公式如下。
其中 是需要学习的参数。
最后,采用反向传播算法训练网络,Optimizer采用的是 ,由于是回归问题,loss函数当然用的是最常见的均方误差 了。