目录
写在前面
进入正文
发福利啦!!!
期待以后学得更好
写在前面
2018/1/8 17:00 又是一学期结束了
考完系统结构这门课程以后....
我现在最大的疑惑就是——
为什么我背的都没考?
更不幸的是!考到的又都没看到 emmmm
但,这门课程对于计算机专业来说,还是很重要的,比如某京大学还把它作为考研科目之一呢(别胡思乱想了,不是北大呐)
先说一下我们学校用的这套教材——《计算系统结构(第二版)》郑伟民、汤志忠编著 清华大学出版社
PS:完整的课件PPT(前9章)以及学习过程中整理的学习资料、习题答案等详见 >>这里>>
进入正文
下面是我在复习过程中总结出的一些这门课程在这套教材下的常见考(问)题...
❤标记❤


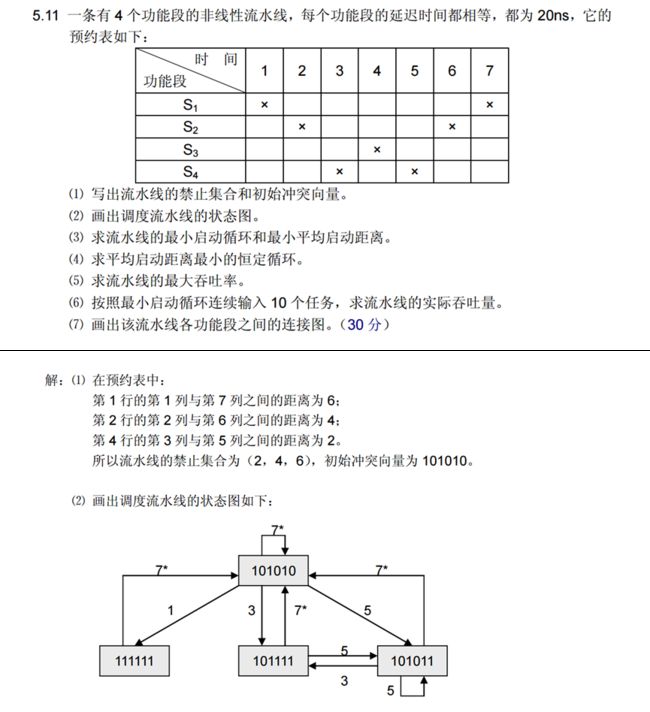



❤标记❤
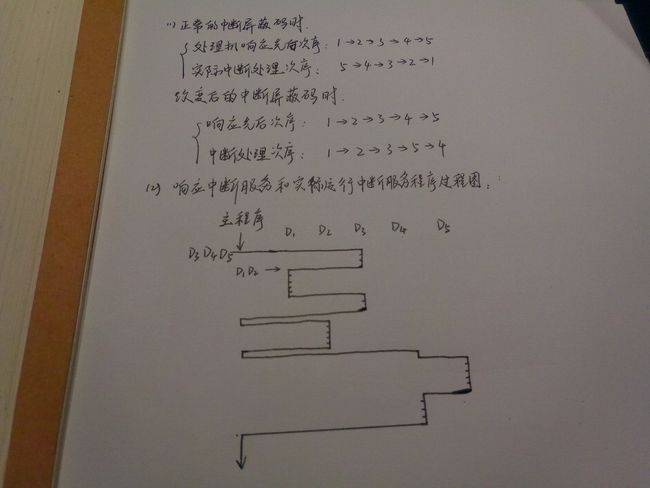
【例题】有5个中断源,其中断优先级1级最高,5级最低,正常情况下的中断屏蔽码和 改变后的中断屏蔽码如下表所示,每个中断源的有5位中断屏蔽码,其中“1” 表示该中断源被屏蔽,“0”表示该中断源开放。

(1) 如果5个中断源同时申请,分别写出使用正常的中断屏蔽码和改变后中断屏蔽码时,处理机响应各中断源的中断服务请求的先后次序和实际中断处理次序。
(2)假设处理机从响应中断源的中断服务请求开始,到运行中断服务程序中第一次开中断所用时间为1个单位时间,运行中断服务程序的其它部分所使用的时间为4个单位时间,那么在执行主程序时,有D3、D4和D5同时发出中断服务请求,过了3个单位时间,又有中断源D1和D2同时发出中断服务请求,如果使用改变后中断屏蔽码,请画出处理机响应中断源的中断服务请求和实际运行中断服务程序过程示意图。
例1:在一个页式二级虚拟存贮器中,采用FIFO算法进行页面替换,发现命中率H太低,因此有下列建议:
(1) 增大辅存容量
(2) 增大主存容量(页数)
(3) 增大主、辅存的页面大小
(4) FIFO改为LRU
(5) FIFO改为LRU,并增大主存容量(页数)
(6) FIFO改为LRU,且增大页面大小
试分析上述各建议对命中率的影响情况。
[解答]
(1) 增大辅存容量,对主存命中率H不会有什么影响。因为辅存容量增大,并不是程序空间的增大,程序空间与实主存空间的容量差并未改变。所以,增大物理辅存容量,不会对主存的命中率H有什么影响。
(2) 如果主存容量(页数)增加较多时,将使主存命中率有明显提高的趋势。但如果主存容量增加较少,命中率片可能会略有增大,也可能不变,甚至还可能会有少许下降。这是因为其前提是命中率H太低。如果主存容量显着增加,要访问的程序页面在主存中的机会会大大增加,命中率会显著上升。但如果主存容量(页数)增加较少,加上使用的FIFO替换算法不是堆栈型的替换算法,所以对命中率的提高可能不明显,甚至还可能有所下降。
(3) 因为前提是主存的命中率H很低,在增大主、辅存的页面大小时,如果增加量较 小,主存命中率可能没有太大的波动。因为FIFO是非堆栈型的替换算法,主存命中事可能会有所增加,也可能降低或不变。而当页面大小增加量较大时,可能会出现两种相反的情况。当原页面大小较小时,在显著增大了页面大小之后,一般会使主存命中率有较大提高。但当原页面大小已较大时,再显著增大页面大小后,由于在主存中的页面数过少,将会使主存命中宰继续有所下降。
(4) 页面替换算法由FIFO改为LRU后,一般会使主存的命中率提高。因为LRU替换算法比FIFO替换算法能更好地体现出程序工作的局部性特点。然而,主存命中率还与页地址流、分配给主存的实页数多少等有关,所以,主存命中率也可能仍然较低,没有明显改进。
(5) 页面替换算法由FIFO改为LRU,同时增大主存的容量(页数),一般会使主存命中率有较大的提高。因为LRU替换算法比FIFO替换算法更能体现出程序的局部性,又由于原先主存的命中宰太低,现增大主存容量(页数),一般会使主存命中率上升。如果主存容量增加量大些,主存命中率H将会显著上升。
(6) FIFO改为LRU,且增大页面大小时,如果原先页面大小很小,则会使命中率显著上升;如果原先页面大小已经很大了,因为主存页数进一步减少而使命中率还会继续有所下降。
例2:采用组相联映象、LRU替换算法的Cache存贮器,发现等效访问速度不高,为此提议:
(1) 增大主存容量
(2) 增大Cache中的块数(块的大小不变)
(3) 增大组相联组的大小(块的大小不变)
(4) 增大块的大小(组的大小和Cache总容量不变)
(5 )提高Cache本身器件的访问速度
试问分别采用上述措施后,对等效访问速度可能会有什么样的显著变化?其变化趋势如何?如果采取措施后并未能使等效访问速度有明显提高的话,又是什么原因?
[分析] Cache存储器的等效访问时间 ta = Hc*tc + (1-Hc)*tm
等效访问速度不高,就是ta太长。要想缩短ta,一是要使Hc命中率尽可能提高,这样(1-Hc)tm的分量就会越小,使ta缩短,越来越接近于tc。但如果ta已非常接近于tc时,表明Hc已趋于1,还想要提高等效访问速度,则只有减小tc,即更换成更高速的Cache物理芯片,才能缩短ta。另外,还应考虑Cache存贮器内部,在查映象表进行Cache地址变换的过程时,是否是与访物理Cache流水地进行,因为它也会影响到ta。当Hc命中率已很高时,内部的查映象表与访Cache由不流水改成流水,会对tc有明显的改进,可缩短近一半的时间。所以,分析时要根据不同情况做出不同的结论。
如果Cache存贮器的等效访问速度不高是由于Hc太低引起的,在采用LRU替换算法 的基础上,就要设法调整块的大小、组相联映象中组的大小,使之适当增大,这将会使Hc 有所提高.在此基础上再考虑增大Cache的容量.Cache存贮器中,只要Cache的容量比较 大时,由于块的大小受调块时间限制不可能太大,增大块的大小一般总能使Cache命中率 得到提高.
[解答]
(1)增大主存容量,对Hc基本不影响.虽然增大主存容量可能会使tm稍微有所加大,如果Hc已很高时,这种tm的增大,对ta的增大不会有明显的影响。
(2)增大Cache中的块数,而块的大小不变,这意味着增大Cache的容量.由于LRU替换算法是堆栈型的替换算法,所以,将使Hc上升,从而使ta缩短.ta的缩短是否明显还要看当前的Hc处在什么水平上.如果原有Cache的块数较少,Hc较低,则ta会因Hc迅速提高而显著缩短.但如果原Cache的块数已较多,Hc已很高了,则增大Cache中的块数,不会使Hc再有明显提高,此时其ta的缩短也就不明显了。
(3)增大组相联组的大小,块的大小不变,从而使组内的块数有了增加,它会使块冲突 突概率下降,这也会使Cache块替换次数减少.而当Cache各组组内的位置已全部装满了 主存的块之后,块替换次数的减少也就意味着Hc的提高。所以,增大组的大小能使Hc提高,从而可提高等效访问速度。不过,Cache存贮器的等效访问速度改进是否明显还要看目前的Hc处于什么水平。如果原先组内的块数太少,增大组的大小,会明显缩短ta;如果 原先组内块数已较多,则ta的缩短就不明显了。
(4)组的大小和Cache总容量不变,增大Cache块的大小,其对ta影响的分析大致与(3) 相同,会使ta缩短,但耍视目前的Hc水平而定。如果Hc已经很高了,则增大Cache块 的大小对ta的改进也就不明显了。
(5)提高Cache本身器件的访问速度,即减小ta,只有当Hc命中率已很高时,才会显著缩短ta。如果Hc命中率较低时,对减小ta的作用就不明显了。
---------------------我是分割线---------------------我是分割线---------------------我是分割线-------------------------
发福利啦!!!
下面就是这次考试我遇到的部分常规题目(标红)以及其他复习所谓必看点呐...
- 当浮点数值尾数的基值为8,除尾符之外尾数机器位数为6位时,可表示的规格化最小的正尾数值是(A)。
A、0.125 B、0.25 C、0.5 D、1/64
- ILLIAC Ⅳ阵列处理机中,PE之间所用的互连函数是(C)。
A、Shuffle B、Cbule0和Cbule1
C、PM2±0和PM2±3 D、PM2±2
- 用N=16的互联网络互联16个处理机,编号为0~15,若网络实现的互联函数为Cube2(Cube0),则从7号处理机联接到的处理机号是(B)。
A、3 B、2
C、7 D、5
- IBM 370系统中,中断响应优先级级别最高的中断类型是( D )。
A、程序性中断 B、重新启动中断
C、输入输出中断 D、紧急机器校验中断
- 解决软件移植最好的办法就是(A)。
A、采用统一高级语言 B、采用模拟方法
C、采用统一标准设计计算机结构 D、采用仿真的方法
- 计算机优化使用的操作码编码方法是(
A)。纠正:正确答案是C
A、哈夫曼编码 B、ASCII码
C、扩展操作码 D、BCD码
注:关于 哈夫曼编码 和 扩展操作码 的区别以及所改进的地方,可以参考教材P91页 2.3.2 操作吗的优化表示 部分的内容,很好理解的。
- 一个由25台计算机组成的Cluster系统的指令内部由4个PentiumIII 700M,其指令峰值速度为多少?
答:由“III”可知IPC = 3 即 CPI = 1/3 且Fz=700 MHz
指令峰值速度=Fz / (CPI * 10^6)=700 * 10^6Hz * 4 * 25 / ((1/3)*10^6) = 2.1*10^5 MIPS
- 基本输入输出方式中程序控制方式称为(状态驱动输入输出处理方式)。
- ILP=n的k段超流水处理机执行N条指令相对于单发射流水处理机的加速比为(n(N+k-1)/nk+N-1)。
- 2-4-8扩展编码方法最多可编码的码点数为(178)个。1+1+((2^2-1)*4-1)*16 = 178.
- 中断屏蔽不能改变中断(响应)优先次序,但是,它能动态改变中断执行次序。
- 在尾数采用补码、小数表示且p=6,阶码采用移码、整数表示且q=6,尾数基值rm为16,阶码基值re为2的情况下:对于规格化浮点数,最大阶数为(63)。re^q-1 = 2^6-1
- 在同一时间内,多功能流水线中的各个功能段可以按照不同的方式连接,实现同时执行多种功能是(动态流水线)。
- 在典型程序中,转移指令占的比例为p=20%,转移成功概率为q=60%,那么对于8段流水线的最大吞吐率下降百分比为(46%)。1-1/(pq(k-1))
- 按Cache地址映像的块冲突概率从高到低的顺序是(直接映像、组相联映像、全相联映像)。
- 不属于堆栈算法的是(FIFO算法)。附注:堆栈型算法的基本特点:随着分配给程序的主存页面数增加,主存命中率也提高,至少不下降。
- 设计一台计算机应有哪五类基本指令?
通用计算机必须有5类基本指令
1、数据传送类指令
2、运算类指令
3、程序控制指令
4、输入输出指令
5、处理控制和调试指令
- 在多处理机系统中,Cache一致性问题由什么引起,主要采用哪两种方法解决?
Cache一致性问题主要由共享可写的数据、进程迁移、I/O 传输等原因产生。目前主要采用监听协议和基于目录的协议,分别适用于不同结构。
- 请你分析浮点数的尾数基值为2,同号相减或异号相加,阶差大于等于2,需要设置警戒位吗?需要设置几位警戒位?
需要,1位警戒位。关于警戒位:
(1) 同号相加或异号相减,浮点数的尾数之和不需要左规格化,因此不必设置警戒位。
(2) 同号相减或异号相加,阶差为0,不必设置警戒位。
(3) 同号相减或异号相加,阶差为1,只需要设置一位警戒位。
(4) 同号相减或异号相加,阶差大于等于2,只需一位警戒位。
- 简述流水线技术特点
(1)只有连续提供同类任务才能发挥流水线效率,尽量减少因条件分支造成的“断流”,通过编译技术提供连续的相同类型操作。
(2)每个流水段都要设置一个流水寄存器,增加时间开销:流水线的执行时间加长;增加硬件开销:每段需要增加一个寄存器。
(3)各流水段的时间应尽量相等,流水线处理机的基本时钟周期等于时间最长的流水段的时间长度。
(4)流水线需要有“装入时间”和“排空时间”。
- 超标量处理机和超流水线处理机异同点。
超流水线处理机的工作方式与超标量处理机不同,超变量是以增加硬件资源为代价来换取处理机的性能,而超流水线处理机秩序增加少量硬件,是通过个部件硬件的充分重叠工作俩提高处理机性能的。从流水线的时空图来看,超变量处理机采用的是空间并行性,而超流水线处理机采用的是时间并行性。
- 在设计一个计算机系统时,确定数据表示的原则主要有哪几个?
确定数据表示的原则主要有三个: 一是缩短程序的运行时间, 二是减少CPU与主存储器之间的通信量, 三是这种数据表示的通用性和利用率。
- 列出互连网络中四种寻径方式?并指出它们各自优缺点?
1.线路交换 在传递一个信息前需要频繁的建立从源结点到目地结点的物理通路,开销将会很大。
2.存储转发寻址 包缓冲区大,不利于VLSI的实现;时延大,与结点的距离成正比
3.虚拟直通 没有必要等到整个消息全部缓冲后再做路由选择,只要接收到用作寻址的消息头部即可判断,通信时延与结点数无关;同样不利于VLSI的实现。
4.虫蚀寻址 每个结点的缓冲区小,易于VLSI实现;较低的网络时延。
- 如果外设要求的通道实际流量十分接近或等于通道具有的最大流量时,则可能发生局部的数据丢失问题,我们怎样解决(三种方法)?
1. 增大通道最大流量。
2. 动态改变设备优先级。
3. 增加一定数量的缓存器,尤其是优先级比较低的设备
- 解决软件移植最好的办法有哪些?
1.采用系列机
2.采用模拟与仿真
3.采用统一的高级语言
PS:至于试题中的大题,在上面都有用 ❤标记❤出来!!!
期待以后学得更好
虽然在这门课的掌握上还有很多不理解、没学习到的地方!但想来,下学期准备考研的话也没法避开类似于计组、计算机网络、操作系统等等这些相关联课程,哈哈,如果这门课程大家有什么疑惑的地方,关于这篇博客的内容,或是这门课程相关的,欢迎大家联系我互相交流学习啦~ ღ( ´・ᴗ・` )
【附:一文一图】
