关于《经济学人 —— 人工智能专题报告》的一些解读
原文: https://www.economist.com/sites/default/files/ai_mailout.pdf
翻译: http://www.cnblogs.com/massquantity/p/8324015.html
这篇文章出自《经济学人》20160625期 :

《经济学人》的这篇原文就很长,所以我情非得已把这篇附文拆分了出来。以下内容中原文皆以【文章】指代。
这篇【文章】的主要内容,自然是人工智能。然而【文章】的标题却是“机器问题归来(The return of the machinery question)”,这无疑预示着一种历史层面的解读,【文章】中用19世纪工业革命时期人们对于新机器出现的种种态度来类比今天的人们对于人工智能的各种争论,最后得出结论,人工智能总体上来看是对人类发展有利的,就像工业革命中的机器极大促进了经济发展一样。目前很多观点认为人工智能与电、蒸汽机一样,是一种通用技术,甚至可能会引发第四次工业革命,所以这篇【文章】看起来也非常地应景。【文章】主要从科技、历史、经济、教育、社会、伦理等层面对人工智能这个新时代宠儿进行了综述,无论是深度还是广度都是我在其他文章中未见的(这里的深度指纵向的历史深度,而非技术深度),所以在此我也想就【文章】中提到的一些方面进行补充拓展,以期勾勒出更全面的时代样貌。
1.

我们命该遇到这样的时代。
—— 莎士比亚《辛白林》
【文章】第一部分提到了人工智能的创新式破坏所产生的巨大影响,使用的词汇是“creative disruption”,这个词本身有多种引申义,可细分为“creative destruction”,“disruptive innovation “,“disruptive technology”,我想作者可能是把这三层意思都包含在里面了。
这一套“创新式破坏”理论,都源自奥地利著名经济学家约瑟夫·A·熊彼特在其代表作《资本主义、社会主义与民主(Capitalism, Socialism and Democracy)》中提出的术语 —— “creative destruction”。熊彼得的主要思想之一是商业周期(business cycle)理论,他将“creative destruction”视作整个商业周期的一部分,是经济陷入不景气时摆脱困境的良药。因此“creative destruction”主要着眼于宏观经济层面,能产生跨行业的巨大影响力。
“Disruptive innovation “和“disruptive technology”均出自哈佛商学院教授Clayton Christensen的名作《The Innovator's Dilemma》。Christensen所说的创新主要指行业内的技术创新,新产品刚出现时因为性能不足,不受主流市场青睐,但随着该技术的不断改进,最终取代原有产品。这听上去很简单,但为什么很多大公司都败在“disruptive technology”脚下?Christensen认为根本原因并非是大公司的管理者目光短浅或者缺乏创新能力,而是由一级级的客户-供应商价值传递所导致。大公司出来的管理者从上商学院开始就接受的管理信条是:”以客户为中心“;”利润最大化“;”将钱投资在可能的ROI最高的产品上“。这些管理准则大部分时候都没有错,然而在面对“disruptive technology”的时候却瞬间成了错误的指导原则,因为含有“disruptive technology”的产品往往刚出现时其功能不足以和现有产品抗衡,因而下游的大型客户都不需要,那么公司的市场和产品管理者自然会调低该产品的预计收益。而由于一个公司的总体资源是有限的,最高管理层在做决策时自然会选择将更多资源投入预计收益高的产品,而忽略那些“disruptive technology”。Christensen认为这是一个整体的”价值网络(value network)“所导致的结果,“disruptive technology”创造了新的市场和价值网络,最终破坏并取代原有的,稳固的市场和价值网络,这个过程即为“disruptive innovation “。近年来最知名也最令人动容的案例就是诺基亚ceo的那句声泪俱下的自白 ——we didn’t do anything wrong, but somehow, we lost ——以及影像巨头柯达公司的陨落,很多企业在面对“disruptive innovation “的时候恐怕都是这种感受。
【文章】的开头提到:
- 到2025年,由AI引发的”年度创新性破坏影响(“annual creative disruption impact)“将达到14至33万亿美元,其中包括9万亿人工成本,因为AI 可以使知识工作自动化;8万亿生产和医疗成本;以及使用无人驾驶汽车和无人机带来的2万亿效率增益。智库麦肯锡全球研究院(McKinsey Global Institute)声称:AI正在促进社会的转型,与工业革命比起来,这次的转型“速度上快10倍,规模上大300倍,影响力则几乎超3000倍。”
从这部分描述看,如果成真的话,显然是一种creative destruction。【文章】中仅引用了麦肯锡全球研究院(McKinsey Global Institute,MGI)报告中的一句话,而事实上,MGI分别在16年12月,17年1月、4月、6月发表过人工智能相关的报告,这也从侧面体现了人工智能目前的热度。
MGI在报告中提出了六种disruptive model,包括供应/需求的高效对接、产品定制化、数据驱动研发、决策优化等等,这些model都涉及了众多行业。

从2016年来看,各科技公司在AI领域共花费了260-390亿美元,其中90%用于技术研发和部署,而剩下的10%则用于AI收购。下图显示2016年人工智能界获投资最多的六大应用: 计算机视觉、自然语言处理、机器人技术、虚拟智能体、无人驾驶、机器学习。其中机器学习占比最高,大概是因为在各个领域这都是一项通用技术。
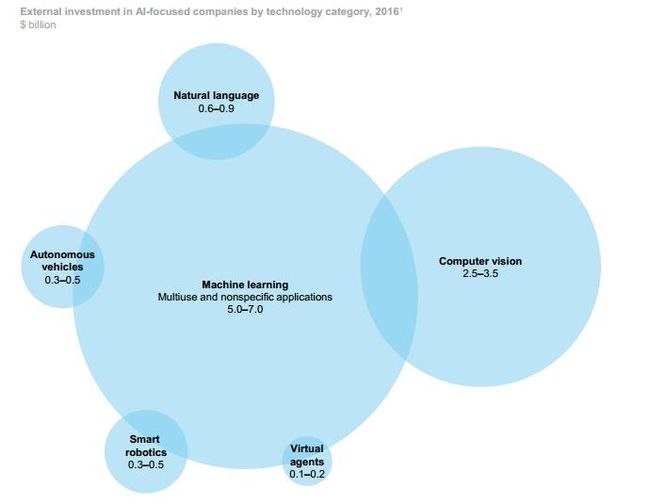
另一家知名咨询公司埃森哲(Accenture)则发布了关于中国的人工智能报告,指出中国政府近年来大力推动人工智能的发展,印发了一系列通知,包括《“互联网+”人工智能三年行动实施方案》,《新一代人工智能发展规划》等,很大一部分原因在于人工智能对于经济的助推作用。埃森哲评估人工智能的发展将对日趋缓慢的经济增长有所补偿,到2035年人工智能的发展可以让中国的GDP增长率提高1.6%。更为重要的是,虽然中国的人口在不断增长,但老龄化的问题却开始显现,带来的问题是劳动人口的增长率正不断下降,如下图所示:
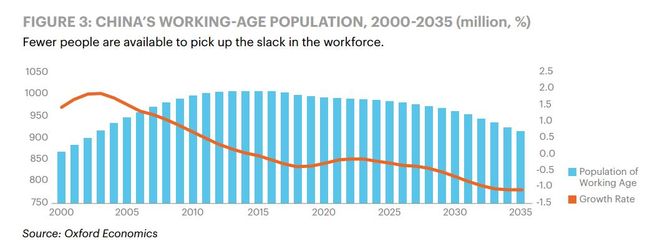
毫无疑问,开放二胎的原因之一就是国家看到了人口老龄化这方面的隐患;而另一方面,人工智能与以往的技术创新如电、铁路、信息技术不同,不仅可以促进经济增长,还可以代替人进行工作,从而创造新的劳动力,这样就能有效缓解人口老龄化的危机。这又从另一个侧面反映出人工智能对宏观经济的巨大影响。
众所周知,人工智能在发展初期表现乏力,然而现在却在多个行业表现出惊人的效果,并逐渐取代了原有的模式,这很像是“disruptive technology”的发展轨迹。对于具体行业的影响,这里仅举一例 —— 医疗行业。
比起其他行业,医疗行业对AI往往持较谨慎态度,如文中所述,原因主要有政府监管问题、病人隐私问题、诊断可信度问题、医疗市场的碎片化等。但未来人工智能在医疗行业却是大有可为的,如【文章】中所述的医学影像诊断,预测疾病分布,个体治疗方法的定制化,协助药物研发等。未来的人工智能技术不仅可以分析大量的医疗历史记录,还可以分析周边可能影响健康的环境(例如污染、噪音等),检测出其中的高危人群,提醒当地政府采取措施;医疗专家可以远程监控病人健康状况以及饮食和运动规律,通过数据分析来预测病人的康复情况或潜在风险,这样也能缓解医院的过分拥挤;使用了机器学习和自然语言处理技术的智能机器人可以进行挂号登记,根据病人具体情况分配给最合适的医生;人们在家中可以使用小型自动诊断设备执行简单的日常身体监测和开具药方,不仅更加方便,也省去了很多跑医院的成本;机器学习同样可以精确预测市场需求,优化库存和产品组合。
总的来看,一项“disruptive technology”刚出现的时候,大部分人往往不以为然,直到其真正爆发后,人们才突然感受到其“破坏性”的威力。人工智能的威力已然令很多人惊愕,在围棋领域,AlphaGo已经战胜现世界排名第一的柯洁了,然而和之前与李世石的对战不同,这一次人们几乎一边倒地预测阿尔法狗会赢。在这几年间全面目睹了阿尔法狗的恐怖实力后,严肃和反思终于取代了怀疑和漠视。如果从现在回到过去来做预测的话,相信大部分人也会说肯定是AlphaGo战胜李世石。
站在现在,看未来就像重重迷雾;但回望过去,一切又是那么地清晰。《经济学人》的这篇【文章】最后说其主要聚焦于人工智能近期的实际影响,人工智能在近的时代发展中会扮演越来越重要的角色,这是无可怀疑的,那么远的和更远的未来呢?
2.

当你在凝视深渊时,深渊也在凝视着你。
—— 尼采《论道德的谱系》
在《Life 3.0》中,MIT的物理学教授Max Tegmark 列举了十几种关乎未来人类与AI的可能情景 :
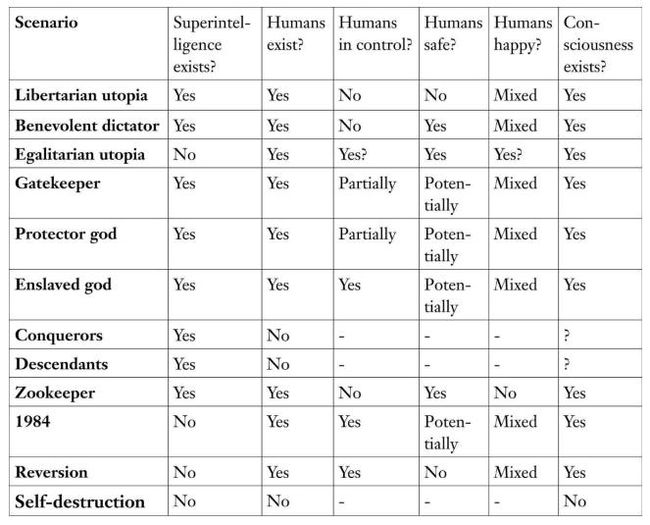
1. AI做主导者的自由主义乌托邦
2. AI成为人类的善意独裁者
3. AI和人类平等共存的乌托邦
4. AI作为人类幸福的守护者和指路灯
5. AI主导着人类,也保护人类的安全
6. AI奴隶着人类
7. AI征服了人类
8. 人类灭亡后,AI成为人类的后代
9. AI把人类当成宠物养在动物园里
10. AI成为独裁者的工具
11. AI消灭了人类对地球的影响,让人类回归田园时代
12. AI 和人类一起走向共同灭亡
乐观点来说,我们自身的行动很大程度上会影响上述情景的走向,而预测未来最好的方法就是去创造未来。在这方面尼采的观点最为清晰,在《查拉图斯特拉如是说》中列举了精神的三段变化 —— “骆驼“、”狮子“、”孩子“,喻指创造的终极形态: 骆驼任劳任怨,忍辱负重,一生都在走一条没有分叉的大道,一旦偏离就总会被人拽回来;狮子非常自大,勇于打破传统观念,可以直接宣称”上帝死了“,但却只会打破不会创造;孩子内心纯净,没有教条的束缚,可以重新创造新的价值,创造自己想要的未来。
然而事情并非这么简单,如果单靠行动就能造出我们理想中的未来,那为什么【文章】第二部分中说的:
- 人工智能这个术语首先出现在1956年的一项研究计划中,该计划提出,“如果精心挑选一批科学家共同工作一个夏天,一些课题将会取得重大进展,比如使得机器能够解决一些目前只有人类才能处理的问题”。这已被证明是乐观过了头,或者至少可以这么说,尽管AI间歇性地取得过一些爆发步,它给人的印象却总是承诺远大于成果。
我查阅了一下,这个计划是在一个史称“达特茅斯会议”的会上形成的,这个会议被广泛认为是人工智能的起源。参会者有像克劳德·香农、马文·明斯基、赫伯特·西蒙这样的超级大牛,却依然后来被证明错得离谱,那可想而知我们普通人对未来进行预测的难度了。盐野七生的《罗马人的故事》中有很著名的一段话:“历史必然向前是真理,同样,历史上偶然事件的积累也是真理。成为历史的主角,就要尽快解决和摆脱不好的偶然,把好的偶然引向必然。”偶然事件的不断叠加,就成了趋势。好的偶然积累变为正向趋势,坏的偶然积累则成了负向循环,过分关注一个个偶然事件只会陷入见树不见林的境地。
从大方向上来看,Google、Facebook、Amazon、Microsoft、IBM、LinkedIn、阿里、腾讯、百度等科技巨头争相宣布未来发展核心压宝在人工智能。所以在未来除非他们公开承认自己看走了眼,否则我们这些生活被这些公司深刻影响的普通人都将不得不卷入这股浪潮中。这已经无关乎人工智能对人类究竟会产生什么样的影响,而是未来的轮廓在某种程度上已经是定好的了。这样的话,与其说是人创造出了未来,不如说是提前占据了既定未来的一席之地。我们在展望未来时,未来也在回望着我们。
托尔斯泰在《战争与和平》的最后一章阐述了其历史哲学,其中的一大核心观点是:“在我们所观察的每一行动中,都有一定程度的自由和一定程度的必然。任何行动中自由越多,必然就越少;必然越多,自由就越少。推动历史进程的是由无数偶然性组成的必然性。所以人的自由意志从更加宏大的空间和更加久远的视角来看,是微乎其微的”。如果从这个角度来考虑,上述这些公司的行为其实并不存在多少自由意志。
公司与公司之间固然是不同的,有的追求短期收益,有的重视长期规划,但这些归根结底取决于其对于需求的认识,即使是SpaceX这种为全人类长期利益谋划的公司,着眼点也是“人类客观需求”是真实存在的,即留在地球不是长远之计。所以从广义上来说,驱动公司的主要因素是需求,这其中不仅包括现在的需求,也包括未来的需求。当然也有人说是钱驱动公司行为,因为公司的根本目的是盈利。但实际上只有满足了需求才能得到钱,比如客户想要一台电脑,而你给他送过去一个冰箱,那不可能会付给你钱。
所以回过头来看这些公司的“all in AI“ ,“AI First”,原因其实是他们认为AI(在未来)能够满足人类的需求,满足了需求之后才会盈利。所以从这一点上来说他们并没有多少选择的余地,是全人类需求的大规模存在决定了未来。
当然,上述内容都有一个前提,那就是公司眼中的需求是不是与真实的需求相符?乔布斯曾经说过:“消费者并不知道自己需要什么,直到我们拿出自己的产品,他们就发现,这是我要的东西”。然而并不是每个人都有乔布斯那样的洞察力(即使是乔布斯也有失手的时候,比如Apple Lisa和Apple III),大部分时候人们眼中的和真实的需求都难以匹配,所以接下来我想从一个更本源的角度来探讨创造之前的认识问题。
数学里有一个著名的公式:
$Av=\lambda v$
大致意思是如果公式成立且特征值λ为1,则向量v通过矩阵A进行线性变换后,依然保持原向量v不变。从哲学的角度来看,这简直是认识论的最高境界,外在事物经由我们的感官传入脑中而变换形成的概念是否能与该事物的原初面貌相同?这是非常困难的,上述公式并非恒成立,即不是每个向量都能经过变换而保持不变,而我们对事物的理解与该事物的客观实在也不见得相同(当然这不是唯物主义的观念)。
然而我们的认识本身又非常重要,人的行为归根结底取决于其对于所处世界的认识,不一样的认识会产生不一样的结果。在认识问题上,哲学家中一直存在着理性主义和经验主义之争,当然双方都不是傻子,很少有哲学家会说我们认识世界的方式是纯粹靠理性或者纯粹靠经验,而是二者谁占主导的问题。康德在《纯粹理性批判》开始处说:“毫无疑问的是,我们的一切知识都是从经验开始的……但是,尽管我们的一切知识都是通过经验来开启的,知识却不是全部起源于经验”。我们从外部世界中观察到的东西需要经过知性的加工才能转化为知识,在认识过程中,人本身比客观事物更重要。然而康德认为这世上有些东西是单靠人类的经验和知识永远无法认识到的,他称这些东西为“自在之物”。当我们展望未来时,是凭借着经验和知识进行预测,而由于“自在之物”无法被我们认识到,所以即使“自在之物”对未来产生影响,我们恐怕也难以意识到。
而从信息论的角度看,如果事先对事物一无所知,那要预测这样事物是非常困难的,因为这其中存在着极大的不确定性,即熵很大。要降低这种不确定性,则需要引入信息,所以在这个系统中经验和知识就是充当着信息的作用(而自在之物这种说不清道不明的东西显然无法充当信息)。然而正如康德所述:“经验既不会提供严格的普遍性,也不会提供无可置疑的确定性。”光靠经验是无法彻底消除不确定性的,这也是为什么很多时候即使是专家也会做出错误的判断。
当然,在研究历史事件时,我们手握大量的信息,因而不确定性也被降到最低,这时候可以通过因果律将一个个事物联系在一起(不要忘了,即使是偶然事件,也必然存在着原因)。当我们站在现在回望过去时,能通过结果反推原因,不怎么费力地得出相应结论,比如现在我们通过研究都可以说08年金融危机的起因之一是美国过于宽松的借贷体系。然而当我们凝视未来时,因果关系就没那么容易确立了。
美籍华裔科幻作家特德·姜在《你一生的故事》中描绘了一个从结果推原因的现象,如下图所示 :
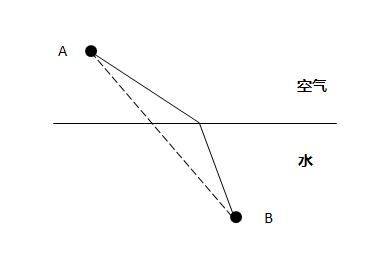
一束光从空气进入水中会发生折射,图中实线显示的是光从A点到B点耗时最短的路径,这是光实际走的路径,而虚线是理论路径,理论路径比实际路径要短,但实际耗时却更长,因为光在水中的速度比在空气中慢。这个现象诡异的地方在于,光仿佛知道自己的目的地在B点,也知道途中会碰到水,所以在比较计算了所有可能的路径后,选择了耗时最短的那条路径,这在物理学上被称为费尔马定律。这已经不是因果律了,而是目的论: 事先知道“果”,再反推到达这个“果”的“因”。小说中的外星生物“七肢桶”所发明的语言就有这种特性,所以它们在观察事件后,便会知道最后的结果。由此,我们的语言是不是也需要一次革新呢?
3.

The limit of my language, is the limit of my world.
—— Ludwig Wittgenstein
传说中,夏目漱石在担任英文教师时,给学生出的一篇短文翻译,要把文中男女主角在月下散步时男主角情不自禁说出的"I love you"翻译成日文。夏目漱石说,不应直译成“我爱你”,而应含蓄,翻译成“月が绮丽ですね”(今晚的月色真美)就足够了。
【文章】第四部分提到深度学习是一个典型的黑箱算法,难以用语言解释机器的决策过程,此为其一大缺点,可真的是这样吗?我们的语言明明如此多姿多彩、风情万种,可为何连区区模型决策过程都描述不出来呢?在这里我们先考察一下深度学习本身的特点,再回过来探讨这个问题。这篇【文章】因为考虑到《经济学人》的读者群体,所以在技术方面不可能深入,想要进一步了解深度学习的话可以参考三位深度学习大牛(Geoffrey Hinton,Yann LeCun, Yoshua Bengio,下图)联合在《Nature》上发表的综述文章。

我们平常用机器学习做各种任务,一般需要在原始数据的基础上做特征工程来提取新的特征。特征对于最后预测的结果非常重要,有句话叫:“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限”。然而手工选取特征非常费时费力,而且往往需要依赖特定领域的专家知识来做判断,比如预测一项产品会不会成功可以从整体市场需求、产品特性和需求的契合度、产品本身的质量、价格、后端供应链的完善性、产品对于新需求的适应性、竞争对手的情况、公司宣传产品的力度、客户服务的质量以及这些特征之间相互组合筛选来进行评估,但现实中即使是人类专家要想设计出好特征也是相当困难的。
深度学习与多数传统的机器学习算法不同,可以进行自动特征提取,特别是对原始特征进行非线性(non-linear)组合,通过多层处理,逐渐将初始 的“低层“特征表示转化为“高层 “特征表示,再用”简单模型“即可完成复杂的分类等学习任务。整个过程无需人类干预,这是个很大的改变,所以深度学习也叫无监督特征学习(Unsupervised Feature Learning)。
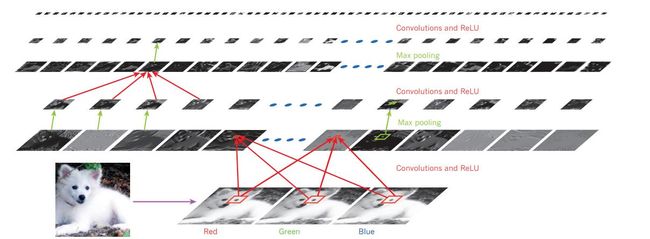
上图显示的是一条萨摩耶犬,来源于上文《Nature》里的那篇文章,描绘的是一个卷积神经网络(convolutional neuron network)自下而上的特征提取过程。下面都是由原始像素提取的边缘信息特征,经过一步步聚合转换成上面的高阶特征。而下图(来源)更加清晰地表现出计算机学习出来的高阶特征已经包含了抽象全局信息,在此基础上做分类就比较容易了。

深度学习的这种特性意味着其可以被广为应用到各个领域,即使是不了解特定领域的人也可以作出比领域专家更好的结果出来(特别是很多很难提取特征的领域)。很多时候人们会发现深度学习有点“蛮不讲理“的味道,可以充分借用海量的数据和现代计算机强大的计算能力来”硬学“(这并不是说深度学习没有技术含量),不需要依靠领域知识。2012年9月,Kaggle 举办了Merck分子活动数据挖掘大赛,各路分子生物学、医学、化学和药学数据科学团队纷纷出场,激烈厮杀。这个时候,Geoffrey Hinton 的博士生团队拎着深度学习+GPU的大杀器闯进赛场,仅仅用了两个星期,就把各路高手纷纷干翻,夺得冠军。重要的是,这个冠军团队是清一色的计算机和深度学习专家,一点生物、医学、化学背景都没有。
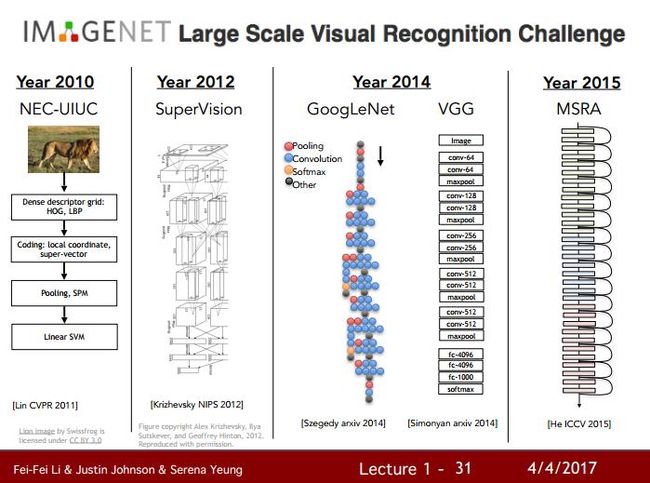
【文章】第二部分提到的ImageNet计算机视觉大赛,最初由斯坦福的李飞飞教授领衔推出,下图显示了近年来比赛获得第一名的误差率,可以看到2012年引入深度学习后,误差率一下子下降了将近10%,为最大单年下降幅度。
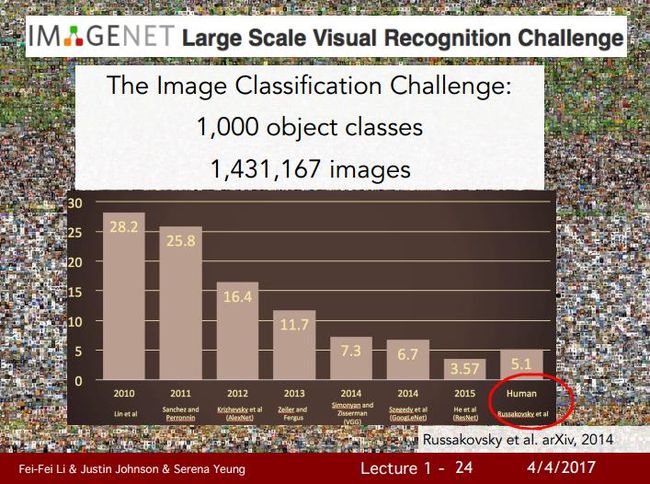
下图显示2012年之前的ImageNet冠军还是使用传统机器学习,但在2012年Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton等人使用了卷积神经网络获得很大提升后,后面几年的冠军都变成了越来越复杂的深度神经网络。
现在回到最开始的问题,深度学习的全自动特征提取固然很好用,然而很多时候一个方面的优势反而成了另一个方面的劣势。下面仍由预测一项产品的成功概率举例 :
如果进行传统的逻辑回归,y表示成功的概率,模型学习出来的结果可能是(因为是分类问题,这里使用Sigmoid函数):

这样就能直观地看出新组合的“价格*质量*需求”这个特征对产品的成功与否比较重要,也可以看出价格的重要性大约是质量或需求的2倍。
而如果采用深度学习,则最后学习出的结果可能是(这里仅是举例):

这样就无法看出究竟哪个特征对产品的成功与否比较重要,各特征的重要性差异也是不得而知。如果这只是个产品预测问题,那至少不会是什么性命攸关的问题,但若如【文章】中所述,无人驾驶汽车的变量选择和决策过程,或者AI医生的诊断推理过程是我们人类无法掌握的话,那听上去确实是件很可怕的事情,这等于是把性命交给了一个神秘的陌生人来决定,而我们甚至都不知道它是根据什么来做决定的。
不过,若真要说黑箱的话,还有比量子力学更黑的吗?量子力学已经有100多年历史了,如今更是被视作现代物理学的基石。然而其原理实在太过古怪,以至量子力学的奠基人之一的玻尔曾说:“没有被量子理论震惊的人,就是没有理解它。” 在量子力学的世界里,一个粒子以一定的概率处在A态,又有一定的概率处在B态,事实上在我们没有观测前,粒子处于一个A态和B态叠加在一起的混合状态。但当我们打开箱子进行观测时,由于观测这个行为会对系统产生影响,导致今天观测粒子处于A态,明天观测可能就变成了B态,整个理论构建在一种诡异的不确定性上。因此不难想见量子力学在诞生初期也是饱受质疑,伟人如爱因斯坦都很鄙夷地说:“朋友,上帝可不会掷骰子。”但是整个过程中就是物理学家先发现了许多与经典物理理论不符的现象,进而发展出量子力学的各种理论,这些理论得以解释许多现象以及预言新的、无法直接想象出来的现象。因此对照量子力学的发展过程,深度学习碰到的是类似的情况,我们不清楚模型内部是怎么做决策的,但实践的效果却很好,只是亟待一种完整体系的建立。而翻看科学技术发展的历史,工程实践总是先于理论理解出现:透镜和望远镜先于光学理论,蒸汽机先于热动力学,飞机先于空气动力学,无线电和数据通信先于信息理论,计算机先于计算机科学。
或者再举个日常点的例子: “开车时凭什么相信踩了刹车,汽车就会慢慢停下来?” 因为有摩擦力。摩擦力这个东西本来没有名字,但科学家发现了这种现象并经过反复实验后,才认识到这种力的存在,进而将其命名为“摩擦力”。而我们大部分人认识的过程其实是先被传授了知识,说刹车会产生一个叫摩擦力的东西,使车停止,进而在实际操作中发现果真如此,所以就慢慢相信这一套了。所以这就是一个很明显的例子,由我们语言的改变致使我们认识世界方式的改变。
因此从另一个角度想,所谓的无法解释机器的决策过程,其实是难以用我们人类可以理解的语言来解释其决策过程。反过来说,可能并非是机器无法自我解释,而是我们的语言体系本身就弱爆了。比如上例中可以发明一个词叫“价需多次体”来表示 ln(价格*需求),那么ln(价格*需求^(3/2))就可以说成是“价需多次体需32”。下次人们在交流的时候,就可以说:“在这个模型中价需多次体需32比较重要,是其他变量的XX倍”。刚开始人们可能很难适应这种解释方式,可像开车一样,刹车灵验的次数多了,也就自然而然地相信并熟练应用了,并没有人真去做实验检测摩擦力的存在性。虽然现实中的深度学习问题不会像我举的这么简单,但这不失为一个思路。其实可以看到几乎所有领域都存在大量的专业术语,这是因为原来日常的语言体系无法承担起描述领域知识的作用,所以不得不创造更多新的。
【文章】第二部分提到“迁移学习”,指系统能构建于过去习得的知识基础之上,而不是每次都从头开始训练。人类做到这一点毫不费力,计算机却不行,但我们人类自己也无法描述是如何做到这一点的,因而可以说我们能做许多自己无法解释的事情。我们的大脑,说到底不过是一堆脑细胞所组成,然而这些细胞组合在一起是如何产生思维、梦境、意识和情绪的,又是如何使用这些来进行推理决策的?现代科学对此还不是很清楚。所以在上世纪人工智能一直裹足不前,以至【文章】中都说“尽管AI间歇性地取得过一些爆发式的进步,它给人的印象却总是承诺远大于成果”。因为人类自己都无法解释自己的认知决策过程,那又该如何教机器来做这些事情?所幸现在的机器学习可以不用靠人类编程输入显式的规则,而是计算机通过大量的实际数据来自我学习规则完成任务,而至于是让机器用我们的语言来解释其行为,还是我们改进自己的语言体系来理解机器的决策过程,这是个可以探讨的问题。不过这一切的前提是,你得有大量的数据。
4.
IN God we trust; all others bring DATA.
—— W. Edwards Deming
这篇文章提到马云说阿里巴巴是家数据公司,马云的话自然不可全信,但这话还是值得玩味的。数据对于人工智能的重要性不言而喻,数据之于AI就如同食物之于人类。而随着人工智能的不断发展,数据正演变成一种新的资产,若干年后的资产负债表上可能会增加数据规模、数据维度等项目,或者仿照现金流量表建立一张数据流量表,加在每月财报里,甚至可以把数据作为一种新型货币来交易。比如IBM与许多医药公司和医院进行合作,获取数据来训练Watson系统,这是不得已而为之的。从目前来看,智能化道路上最大的障碍不是算法,不是计算能力,而是大量高质量的数据。算法框架各大科技巨头均已开源,计算能力不足可以通过云计算实现,然而数据,特别是医疗数据是非常敏感的(亚马逊的医疗数据泄露就引起轩然大波),非常难以获得,而且很多疑难杂症,全世界都没有几例,也就没法对这个类别搜集大量数据。而IBM花大成本研发的系统如果没有大量的数据作支撑的话,就如同是没有水的护城河 —— 虽不能说完全是个摆设,但终究是作用有限。
而与之相比,对于很多互联网巨头而言,获取数据的自由度就高多了。【文章】中说大型互联网公司之所以都愿意免费开放自家的AI框架,是因为在其他层面他们手握巨大优势:即能够获取大量用于训练的用户数据。《经济学人》之前发表过一篇文章(The Great Divergence ),讲的是熊彼得的著名理论认为做一个行业领先者是相当危险的,因为后来者可以利用现成的知识和技术加以适当改进来赶超领先者。但近年来的研究却发现各行各业都出现了“赢者通吃”的局面,因为行业领先者拥有雄厚的资源可以不断投资新技术,以及都掌握着一些垄断优势。这反映在数据层面也同样是如此,大公司由于拥有得天独厚的数据优势,在人工智能的发展上就领先了一步。
在数据层面还有一个值得考虑的问题,这个问题会直接影响数据的使用 —— 即数据的标注。目前机器学习界占主导地位的是监督学习,其中特别是深度学习这类算法,需要大量带标签的数据进行训练,像ImageNet的数据库中有2.2万个类别、1500 万带标签的图片,据李飞飞介绍这么多图片是花了3年才全部标注完的。数据的标注甚至已演变成了一个行业,可以参阅这篇文章的介绍。
鉴于真实世界中大部分数据都是无标签的,而人工对数据进行标注又非常费时费力容易出错,所以现在机器学习和深度学习中,重要的宏观趋势是算法研究正逐步从监督学习转变为无监督学习和小样本学习。Yann LeCun在很多演讲中反复提到一个著名的“蛋糕”比喻,来解释无监督学习的重要性:
- 如果人工智能是一块蛋糕,那么强化学习( Reinforcement Learning)是蛋糕上的一粒樱桃,监督学习(Supervised Learning)是外面的一层糖霜, 无监督学习( Unsupervised Learning)则是蛋糕胚。
- 目前我们只知道如何制作糖霜和樱桃,却不知如何制作蛋糕胚。

本来这一节写到这里就可以搁笔了,然而最近DeepMind又出来搞事了。2017年10月18日,DeepMind在《Nature》上发表了一篇论文,介绍了依靠纯强化学习训练而成的阿尔法元(AlphaGo Zero)。对于从业者来说,这其中最大的亮点不是能100:0横扫旧版AlphaGo,而是看到了一丝希望,即不需要大量人类提供的数据(在围棋中,意味着历史棋谱)进行训练。如果能妥善解决目前普遍存在的数据缺失问题,那对整个人工智能界乃至全人类发展的影响都比成为围棋世界排名第一要大的多。
人工智能的一项重要目标,是在没有任何先验知识的前提下,通过完全的自学,在极具挑战性的领域,超越人类水平。而AlphaGo Zero就是不参考历史棋谱,不需要人类的样例和指导,只以棋盘上的黑子和白子作为输入,通过自己和自己博弈进行训练。据AlphaGo Zero的第一作者、UCL的教授David Silver在访谈中介绍:他们在之前的AlphaGo中尝试过自我博弈,但发现都不稳定,这次发现AlphaGo Zero所使用的算法是最高效的,所以他觉得目前来看算法比数据重要,这对于整个业界来说都是重要的新思路。
AlphaGo Zero的出现令强化学习大放异彩,早些时候强化学习就在《麻省理工科技评论》发布的2017年全球十大突破性技术榜单上排名第一。如【文章】中所述,监督学习、强化学习和无监督学习是机器学习的三大框架。强化学习的主要过程是智能体在环境中观察并采取行动,以获得最大的期望奖励,如下图所示 :
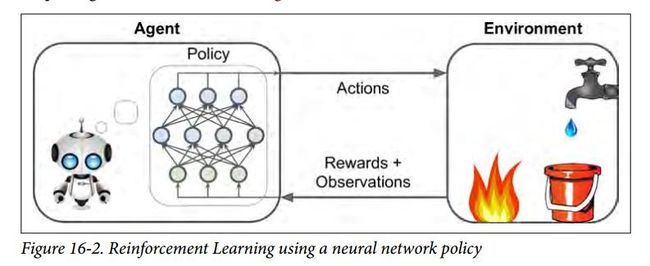
强化学习主要适用于需要与环境不断交互来获得最大奖励的领域。比如一个智能体可以在股市中不断进行观察,继而在每秒决定买进还是卖出。股市是一个极端复杂不可控的环境,再厉害的人类交易员,也很难在高维数据分析方面比得过机器学习算法。另外,投资很多时候需要极度理性,看清长远趋势,放弃短期利益才能最终获得收益最大化。而强化学习恰恰擅长放长线钓大鱼,在训练过程中通过不断模拟和试错,神经网络调整参数,智能体最终识别出获取最大奖励的途径。许多人都惊叹于AlphaGo在比赛中表现出的超越人类选手的大局观,其实意思也就是说,它在前期可能会下几步出人意料的棋,但到了中后盘,人们慢慢发现这几步棋成了最终获胜的关键。
早在AlphaGo之前,DeepMind就曾以深度强化学习算法在世界上扬名。围棋作为一项运动是有一定门槛的,而事实上大部分人都不会下围棋,所以本质上也不知道AlphaGo究竟厉害在什么地方,只能从侧面(比如战胜所有围棋高手)获得一些信息。这就像著名小提琴家斯特恩曾这样评论二十世纪最伟大的小提琴家海菲兹:“所有人都知道海菲兹拉得好,但只有拉到我这样水平的人,才明白他的技术究竟有多高超。”
然而,如果让AI玩一个每个人小时候都玩过的游戏,那情况就不同了 :
https://www.bilibili.com/video/av7826870/?from=search&seid=14295172322351513295
上面这个视频,显示的是DeepMind的AI在玩“打砖块”游戏上的自我进化过程。该AI所有的输入仅为现有的分数和游戏画面上的像素,其他的要素比如球、砖块、滑板等,它一概不知。也就是说,除了获得的分数以外,没有任何人为输入的游戏规则信息,全靠长期训练,让AI自己悟出,什么是获取最高分数的策略。所以刚开始时,AI的表现很差,老是漏球;经过400次训练后,AI已经能很熟练地接住所有球了。而到了600次训练后,AI自己“想”出了一个绝妙的策略,它将砖块墙的左边打出一个通道,然后通过这个通道把球打到墙的后面,这样就能快速获得大量分数。这个精巧的打法,是DeepMind的研究者自己都不曾想到的, AI发现了比人类更好的打法。在这个短短一分多种的视频中,人们见识到了由原来的“弱智”AI进化到游戏高手的全过程,而且DeepMind用同样的技术让AI从0开始玩了其他49种不同的游戏,最终AI在29种中胜过了人类测试者。DeepMind于2013年12月发表了这项成果,一个月之后,Google宣布以五亿美元收购DeepMind,后面的故事,现在大家都已经知道了。
【文章】中说Hassabis等人的愿景是开发出通用人工智能(AGI),一个能完成多种任务的系统,而相比较而言,现在的人工智能系统大多只能做同一件事。后文中Hassabis继续说,” 我想我们已经掌握了一些关键信息 ,能够帮助我们向真正实现AGI技术靠拢。“ 果不其然,2017年12月AlphaGo 研究团队提出了 AlphaZero:一种可以从零开始,通过自我对弈强化学习在多种任务上达到超越人类水平的新算法。据称,新的算法经过不到 24 小时的训练后,可以在国际象棋和日本将棋上击败目前业内顶尖的计算机程序(这些程序早已超越人类世界冠军水平),也可以轻松击败训练 3 天时间的 AlphaGo Zero。现在,DeepMind的这些采用新算法的AI能不依靠人类的数据和指导,只通过基本规则进行自我学习就能在多个特定领域超越人类水平,这是通往AGI的关键一步。只是如果真出现了通用人工智能,人类又该何去何从呢?
5.

人类是唯一会交易的动物;没有狗会交换自己的骨头。
—— 亚当·斯密《国富论》
【文章】第四部分提到了一个叫做“全球基本收入(Universal Basic Income)”的制度,大意是 ——“每个人,不管什么情况,都会定期获得固定数额的钱(比如每年10000美元),除此之外再无其他福利金”。基本收入不与原来的收入水平挂钩,不论你的工资是100块、1万块还是没有工作,你都会获得定额的基本收入。
乍看上去这是个很二的制度,如【文章】中所述,如果不用工作就能获得一笔能维持基本生活的钱,那为什么还要出去工作,为何不整天宅在家玩游戏呢 ? 而且发放的很大一部分基本收入会遭到“浪费“,因为每个人获得的基本收入都是一样的,富人本来就很富足,所以基本收入对于他们来说不痛不痒;而穷人也没有因此获得更多的补助,所谓的社会福利体系难道不应该更多地倾向于生活水平较低的人群一边吗?
然而事实是,目前这种制度在全球正受到越来越广泛的关注,很多科技圈名人都提倡全球基本收入制,除了【文章】中的Sam Altman,还有Facebook的Mark Zuckerberg等人。而一些国家像芬兰已经与2017年1月开始小范围试验该制度。所以下面先提出一些不同观点来描述这个制度的本源。不管怎么说,这是个全世界都需要不断讨论的议题。
首先,我们平常说的收入多少,赚的钱多不多之类的,其实根本不取决于绝对数字,而是取决于你自己,你的家人,以及周围人对你的“心理预期收益”。超出了预期,依然会认为你赚的多,这种情况下再去追求更多收入的动力也就小了。或者再举个极端点的例子,王思聪如果在年末公布说自己赚了5000万,人们大概会很惊讶: “堂堂王思聪才赚5000万?赚5亿还差不多啊“。
叔本华云:“对于人的幸福快乐而言,主体远远比客体来得重要。”人的需求和欲望都是不同的,这意味着“心理预期收益“也不尽相同,并非每个人都觉得整天闲着在家过一辈子就可以了。而且“心理预期收益“也会不断变化,如果要买房结婚生小孩,那基本收入的钱可能就不够用了。人在最初获得基本收入时可能会对此比较满意,难以意识到长期利益的影响,但当看到基本收入无法维持一些多样的需求时,大部分人自然会面对现实选择出去工作。
更何况,幸福感这个东西,很多时候都来自于比较。因为人毕竟是社会动物,看别人工作挣钱,周游列国,购物不止,整天和你炫耀,而你却只能守着一些政府给的基本收入,除了维持基本生活外啥也干不了,此等情景绝对不会好受。有比较才会产生动力,由此逐渐认识到现在的情况不是自己想要的,进而寻求新的收入来源。
其次,基本收入制是对西方臃肿的现行福利体系的改革。对于芬兰这样的高福利国家而言,基本收入制可算是一个无奈之举,因为目前的福利政策的实施成本太高,政府雇了大量的人来管理这个复杂的福利系统,而基本收入制因为简单则不会有这么高的行政成本。另外,目前福利体系的失业金相当高,而一旦去工作了,那意味着就没有失业金可领了,还要缴纳所得税,所以很多人的理性选择就是不工作,这样下去如果智能化的程度越来越高,不工作的人也会越来越多,会出现僧多粥少的局面。相对而言,不论有没有工作,基本收入制都会发固定的钱,这会促使失业者更加积极去寻找新工作。
另一种改革的方向是负所得税制(negative income tax),由经济学家米尔顿·弗里德曼所大力倡导。大意为划定一个收入水平界限,若收入高于这个界限,则要缴纳所得税;若低于这个界限,则政府会按一定比率给予补贴,收入越低获得的补贴就越多。这样等于确保了每个家庭都能有一份最低收入,同时避免了庞大的官僚机构。弗里德曼是经济自由主义的代表人物,一直以来都反对凯恩斯学派的国家干预主义,所以庞大低效的社会保障制度无疑是其深恶痛绝的。然而负所得税制也存在一个问题,那就是不同地区的“生活水平”是不一样的,比如北上广和三四线城市的收入水平界限不大可能会划得一样。而如果按每个地区的具体情况单独划定收入水平界限,那同样会激起不同地区的不满,而且也不见得高效。
最后,很多人提倡全球基本收入制的根本原因,就是看到了人工智能对工作的破坏性影响。
【文章】中提到19世纪工业革命时期人们对于机器的大范围恐惧,甚至有人抨击其为“机械魔鬼“。当时盛行的卢德运动,就是被机器取代的工人们(他们被称为卢德分子)激烈地反抗工业革命,并对纺织机器进行大规模破坏。我们现代人看当时这些工人们的行为是非常可笑的,仿佛他们无法认清时代的变革。但事实上这些工人面临的生存危机可能超乎我们的想象,据马克思在《资本论》中记述:
- 机器的影响是广泛和急性的。世界历史上再没有比英国手工织布工人缓慢的毁灭过程更为可怕的景象了,这个过程拖延了几十年之久,直到1838年才结束。在这些纺织工人中,许多人饿死了,许多人长期地每天靠2便士维持一家人的生活。
马克思对于资本主义的一大批判就是劳动分工把人当成庞大机器的一个零部件来看待,使得工作者不断地重复一些固定的工作,长此以往只能掌握一些特定技能。经济形成的基础在于交易,工作者实际上是把自己的劳动力当作商品来与企业进行交易,当这些工作被机器取代后,劳动力的交换价值就随同它的使用价值一起消失。而如【文章】中所述,由于长期从事特定的工作,想要再从事别的工作同样会变得非常困难。
与工业革命时期的机器相比,人工智能对于现今工作的影响可能更加巨大。前三次工业革命,让人类摆脱了重体力劳动、精细体力劳动、简单计算劳动。而这一次,伴随着人工智能而来的机器学习,很可能让人类不必在简单思考判断类劳动上消耗大量人力资源。【文章】中说判断一项工作是否易受自动化的威胁,不在于这是体力还是脑力工作,而在于其是否具有例行的流程。事实上现在很少有工作能完全被自动化,根据MGI的报告,只有小于5%的工作有被完全自动化的可能,但大约60%的职业中至少有30%的工作活动可以被自动化,如下图所示。所以未来的局面可能是在工作中人与AI相互取长补短,共同完成任务,从这个意义上来说,AI不会取代人,而是能与AI配合的人会取代不能与AI配合的人。
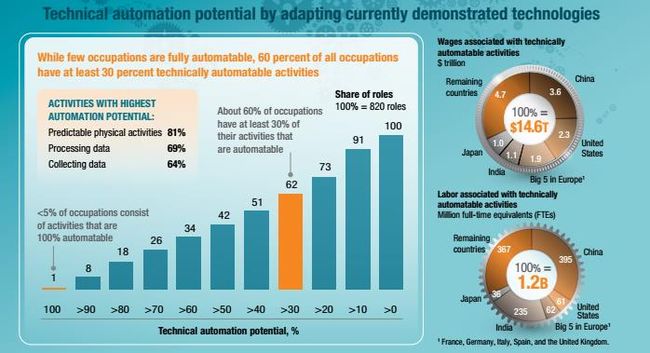
但是如果深入考虑一下的话,MGI报告里体现的恐怕只是理想情况。假设一个人的所有工作活动中有50%可以被自动化,那他的工资还会是原来的工资吗?这当然是不可能的啦,很有可能他的工资也会变为原来的50%,那世界上有几个人能忍受这种情况的?几乎没有。员工和企业的矛盾可能会由此不断激化,超过一个零界点后,企业觉得管理成本太高,会越来越倾向于全自动化流程。所以未来自动化铺展的速度可能会越来越快,让人们始料未及,比如《南方周末》的这篇文章虽然讲的是金融行业,但在这个时代也折射出很多行业面临的现状。
在1930年,经济学家约翰·梅纳德·凯恩斯创造了术语“技术性失业(technological unemployment)”,描述了技术的进步使得劳动需求减少,致使大批人失业。但他同时也认为这只是一种“暂时性的经济失调”。从历史上工业革命的发展历程来看,这确实是暂时性的,但也付出了大批人因此而穷困一生的代价,那么在现如今自动化趋势越来越猛烈的情况下,我们还想要再经历一遍这个过程吗?
所以,近年来倡导实行全球基本收入制的呼声越来越高,也就可以理解了。每月固定获得的基本收入,至少可以让人们免除后顾之忧,从而更多地去尝试学一些新技能,做一些无法被自动化的工作。很多人不敢尝试新工作、学习新技能是因为怕一旦不成功就会丢了饭碗,以至家庭生活失去了保障。正如卢梭所述:“人生而自由,却无往不在枷锁之中。”我们每个人本来都很自由,但后来却时时受制于生活中各种资源丧失的风险而无法自由做决断,所以从这个角度来看基本收入提供的基本保障是给人们增加了一些自由度。
俄国大文豪陀思妥耶夫斯基的名作《卡拉马佐夫兄弟》中有著名的一章 —— 《宗教大法官》,里面提到这位拥有极高权力的大法官认为,从人的本性来说,多数人都会为了一个安定、有保障的生活,而宁愿放弃自由,换句话说,就是以自由交换面包(这里的面包更多地指物质利益)。如果一个人能把石头变成面包,人们就会对他俯首帖耳,不作多想。所以大法官才提出自己统治人类的三大要素:“奇迹、秘密、权威”。大法官的思想无疑是极端的,但并不代表不具有现实意义。
自动化毫无疑问会大幅提高人们的生活水平,然而这些都需要时间,在【文章】中这种延迟现象被称为“恩格斯停滞(Engels’ pause)”。在这段时间中,大批失业和收入水平降低的人们可能会造成极大的社会动乱,进而给极权主义和不良分子一些可乘之机。在基本的生存问题都没有解决面前,就不能指望再看重家国、道义和自由了。基本收入制度以及其他各种各样五花八门的制度,一大核心考量都是为了在这个延迟阶段给人们提供一些基本的收入保障,不让人性的灰暗原罪弥漫在整个社会上,但愿这最终不会成为另一种空谈。
6.

我年纪还轻,阅历不深的时候,我父亲教导过我一句话,我至今还念念不忘。
“每逢你想要批评任何人的时候, ”他对我说,“你就记住,这个世界上所有的人,并不是个个都拥
有你那些优越条件的。”
—— 菲茨杰拉德 《了不起的盖茨比》
《经济学人》2017年1月刊的封面是这样:

这其中的主题已经是再明显不过了:在自动化时代,只有终生学习(lifelong learning)才能保持竞争力。在【文章】中吴恩达也说:“你需要一辈子不断学习,从长远来看这一点已经是再明显不过了。在大学里所学的不足以让你在后40年持续保持竞争力”。伟大的科幻作家阿西莫夫则说,“我坚信,自我教育是这个世界上唯一的一种教育形式。更重要的是,学校里的正规教育总有停止的时候,但自我教育永无停歇。“
所幸,我们身处互联网时代,即使离开了学校,也可以获得多元化的学习形式,像【文章】中的MOOC就是其中的典型代表。其实网络公开课很久以前就有, 比如下图是MIT的数学系名师Gilbert Strang 1999年的线性代数课程 :

下图则是吴恩达2011年在Coursera上开设的《机器学习》课程:
我估摸着MIT的这门课可能是有史以来最著名的线性代数课程,而这很大程度上是拜互联网惊人的传播能力所赐。对比上下两张图,其实授课方式并没有很大的不同,所以从这一点上来说MOOC不能算很大的创新,这类课程成功与否的关键还是在于教学质量,即便是1999年的课程,只要质量过硬,照样被人翻出来膜拜。
从另一个角度看,MOOC的适用对象主要是成年人,而对于小孩的学习来说不大适合。所以比较现实的做法是先在本地教育中打基础,再去学MOOC上国内外名师的课程。但是现在想要获得优质教育的成本正持续走高。某种程度上来说,教育越来越成为钱的游戏,在美国,很久以前就是如此;在中国,随着各种花式补课、学区房的繁荣也是愈演愈烈。归根结底,这是场资源争夺战,几乎整个社会都弥漫着一种“不跟上就会落后”的氛围。
彼得·德鲁克在HBR的一篇经典文章(Managing Oneself)中提出,每个人都应该考虑这样一个问题 : “我是如何学习的?”,在他看来一个人的学习方式是一种天性,很难更改。许多世界一流的作家,在上学时成绩都不好,他们回忆小时候都觉得上学时光是一种折磨。原因是写作者通过“写”来学习,而不是通过“听”或“读”来学习。然而学校不让他们以这种方式学习,所以他们的用户体验都很糟糕。所有的学校都遵循这样的办学思路:只有一种正确的学习方式,而且人人都得遵从。但是,对学习方式跟别人不大一样的学生来说,被迫按学校教的方式来学习就是地狱。
实际上,学习大概有六七种不同的方式。有些人通过不断记笔记来学习;有些人通过听取多方意见来学习;有些人通过实践来学习;有些人通过自省来学习。如果不按自己擅长的学习方式来,那确实不大可能会学的好。所以在这个背景下,适应性学习(Adaptive Learning)应运而生。
数据时代一个很重要的特点是产品和服务能够按每个人的喜好定制,而现在对教育的定制化需求也开始显现。【文章】中说的适应性学习就是能够根据每个学生的具体情况定制课程、以其最易理解的方式教授内容,并按自己的学习情况调整进度。其实这样老师们也能从中获得解脱,以后诸如上课、批改作业、回答日常问题这些流程性工作都可以交给计算机完成(比如乔治理工大学的教授创造了一个机器人教学助手,在2017年能够回答大约40%的学生问题,而且在不断进步),老师们则可以有更多的精力针对每个学生的情况进行个体关照,这种学生与教师之间的互动恰恰是目前的计算机无法实现的。而且将来适应性学习不仅适用于小孩的教育,对于企业内部培训而言也同样适用,效率绝对比大会议室法高多了。
有调查显示,目前大约80家公司,比如Knewton和 DreamBox Learning,正在北美、欧洲和亚洲实验其适应性学习系统。这些系统的核心技术,自然是人工智能。通过实时追踪学生每堂课的暂停次数、回答问题所需要的时间、回答出错的次数、面部表情、鼠标的移动规律、眼球追踪、文字情感分析等项目,计算机视觉、自然语言处理和深度学习系统可以建立起该学生的完整档案,其中包含具体表现、知识掌握程度、上课投入度、自信度、认知水平、思维模式、学习效率等传统教学评估难以考量的项目,进而根据情况调整学习任务。由此可以看到适应性学习确实前景广阔。
最后还存在一个问题: 在类人工智能时代,教育的方向是什么?我们真的要叫所有人都往这个热门方向挤? 所以这里又牵扯出一个亘古不变的选文科还是选理科的问题,因为很多人说文科学了都没什么卵用,号召大家都去学理工科。关于这个问题,先来看看Peter Thiel怎么说(出自CS183):
- 有时候我们可能会觉得世界是这样的:小处清楚,大处模糊。细节历历在目,但是总体图像却一团雾气,就像盲人摸象一样。不管是在商业还是在人生中,一项很重要的挑战就是将细微之处和总体图景结合起来,才能把事情说通。
- 人文学科的孩子通常会对世界的“大象”有不少了解,但是对技术细节所知不多。而理工科则正好相反,他们知道具体细节,但不清楚这些技术是如何或为何融入到这个世界中的。最聪明的那批人则会将两类问题融合到一起,形成统一的认识。这门课程就是为了加速这一过程的进行。
其实我毫不怀疑科技发展水平决定了人类未来生活水平的上限,然而就像一个小孩的良好成长需要好的环境一样,科技的不断进步和应用也需要良好的政治经济社会环境的支持,这些恰恰是文科需要发挥主导作用的地方。文科需要把人类往“好的大方向”上引,而像《经济学人》的这篇【文章】就从社会、政治、经济、历史这些宏观层面来看待人工智能这个异军突起的时代宠儿,让人们在对人工智能有了清醒的认识后,才能更好地主宰未来的人工智能、乃至于人类自身的最终走向。
7.

生活中只有两种悲剧:一个是没有得到我们想要的,另外一个是得到了我们想要的。
—— 王尔德 《道连·葛雷的画像》
纵观整篇【文章】,人工智能对于我们人类的潜在影响,各行各业的人都持各自不同的看法,这也很正常,毕竟“一千个人眼中有一千个陈冠希”。而这其中有3个人可谓是频繁出镜,他们的言论散布在【文章】各个角落: 一个是DeepMind创始人、AlphaGo之父Demis Hassabis;一个是因Coursera上的《机器学习》课程而闻名全球的斯坦福大学教授吴恩达;而另一个则是Elon Musk。
Elon Musk大概是当今世界上最受瞩目的企业家(纽约时报称他为”几乎是世界上最成功、最重要的企业家。”),参与并主导的公司包括:Zip2, X.com, Paypal, SpaceX, Tesla, SolarCity, Hyperloop,OpenAI,涉及的领域有:金融、汽车、航空航天、太阳能、卫星、快速轨道交通、能源储存、外太空殖民(-。-)等。其中OpenAI是直接涉及人工智能的机构,而Tesla则因其无人驾驶系统也是备受人工智能界的关注。
无人驾驶汽车虽然在诞生之初就饱受质疑,【文章】的最后还是显示出了比较乐观的态度,认为无人车会为社会带来巨大的好处,主要体现为减少道路上的车辆数量和车祸事故。试想,如果所有车辆都变成了自动驾驶,你真的还需要买一辆车吗?到时候,大量的无人车在各种巨型停车场静静地趴着,只要有人下单,几分钟后,就会有一辆无人车来到你面前,任你驱使。再也不用忍受不会开车无法出行、偏远地方打不到车、节假日堵车等情况。而且驾驶,特别是长途驾驶,本来就是一个极其消耗时间和精力的事情,有了无人车代理后,人们也可以有更多的精力用来工作学习、休息、陪伴家人等。
这里可能有人会反驳说未来车的数量不会减少太多,因为很多人买车其实是单纯地想要拥有一辆车。 这里首先需要考虑的是为什么会想要拥有一辆车,而不是想要拥有一架飞机、一幅画或者一个音响?那是因为我们从小就耳濡目染,说车是XX的象征,拥有了车就代表拥有了XXX,所以潜移默化中车成了必须拥有的东西。然而到了未来情况就不一样了,正所谓“谎言重复一千遍就成了真理”,因为无人驾驶这项破坏性技术的普及使得对车的观念将发生极大变化,社会的价值观也会随之改变,未来的小孩不见得从小会接收到太多这类“想要拥有车”的想法,就如同现在大部分人不会非要拥有一辆自行车一样。
无人车能缓解堵车严重的情况,一大原因是车的总数量会减少,另一大原因则是能构建一个车与车以及道路物体(如红绿灯)之间的物联系统,通过运筹学和计算机视觉算法进行统一的智能路径规划和决策,有效错开高峰期。然而对于Elon Musk来说,这还是远远不够的。为了减缓交通拥堵,他成立了The Boring Company,规划在地下挖超级隧道,通过电动托盘实现纽约到华盛顿只要30分钟(具体行驶过程见以下视频)。整个路网依靠电力驱动,而托盘的动力系统等关键技术则来自Musk的另一家公司Tesla。当然很多人觉得这个计划不太现实,成本太大,但又都不敢下定论,毕竟想要做这个事情的人,可是那个把几个行业都颠覆了个遍的Elon Musk啊。
https://www.bilibili.com/video/av10173000/?from=search&seid=13650802352394701105
在Elon Musk眼中,无人驾驶汽车还有个比较神奇的用途,那就是其在多个场合提到过的个体无人出租车的概念。假如你购买一辆全自动驾驶车,你可以利用上班时间或者晚上在家里的时间,放自驾车出去运营挣钱,也许没几年就能把买车的钱挣回来了,这确实是笔不错的买卖。到时候Uber和滴滴的周围就会凭空冒出很多竞争对手,而各家公司想必也会出台新规定:不能在上班时间远程遥控自家车,就如同现在规定不能在上班时间炒股玩游戏一样。
以上叙述体现出无人驾驶汽车将会极大改善我们日常的生活模式,但相信其发展也不会一帆风顺。仍有很多人对无人车抱有颇多顾虑,认为其可能会出现系统性的失控,造成大规模事故。所以从这一点上也可以看到,人们在憧憬未来的同时,也一直在担忧人工智能发展的方向问题。
【文章】中Hassabis和吴恩达这些AI圈内的人认为现在一些关于AI的危言耸听的言论是非常不切实际的,而Nick Bostrom对此的回应是“一些AI研究者事实上和他有着同样的顾虑”。这并非是空穴来风,在2017年1月举办的阿西洛马人工智能大会(Asilomar AI Conference)上,AI和非AI界的知名人物都有参加,其中就包括【文章】中的几个主要人物: Elon Musk,Nick Bostrom,吴恩达, Demis Hassabis, Yoshua Bengio,Yann LeCun,Geoffrey Hinton,Patrick Lin等等(不过里面没有霍金,估计是来不了。。)。经过多天商讨大会最终确立了关于未来人工智能发展的23条基本准则。
事实上,人们想要确保人工智能会向人类有利的方向发展,这是有道理的,因为人类的独有领地正一步步被吞噬。Hans Moravec做了一张 “人类能力景观图(Landscape of Human Competence)“,这张图的海平面是当前人工智能的发展阶段,随着海面的不断升高,人类的技能也逐渐被机器所掌握。可以看到算术,棋类运动(围棋、国际象棋)已经没入海底了,驾驶、投资、翻译也是岌岌可危,而处在山顶的艺术、科研、写作等项目暂时还比较安全。
然而,AI的创作能力已然不容小觑,至少看上去能把大部分人吓唬住吧。比如MIT开发了一个以《弗兰肯斯坦》作者玛丽·雪莱为名的编写恐怖故事的AI系统:Shelley。这套人工智能系统通过循环神经网络(RNN)+在线学习的组合模式,使用美国知名论坛网站Reddit上14多万篇诡异故事作为训练材料,具备了自我编写恐怖故事的基本能力。现在Shelley每隔一段时间就在推特上分享一则恐怖故事。而相比之下,微软的小冰则是直接出版了一本诗集。
下图来源于Justin Johnson在CS231n里的PPT,显示的是使用卷积神经网络进行艺术风格转换。

很多人觉得现今人工智能的发展简直令人目不暇接,各种各样新玩法层出不穷,这自然得益于科学家们多年来对于未知世界的探索。《纽约客》的这篇文章讲了有“深度学习教父”之称的Geoffrey Hinton的一则轶事:
- 作者问:“你觉得人类能控制超智能体吗?”
- Hinton:“这就像是在问,小孩能控制自己的父母吗?这是有可能的,因为二者存在血缘关系,但除此以外没有太多案例显示低智能体可以控制高智能 体。”
- 作者:“那么为什么你还在做你的研究?“
- Hinton:“我可以给你一些官方答案,但真正的原因是:探索未知实在太有诱惑力了。当你看到一项美妙新技术处于萌芽期时,会满脑子只想着先把它 做出来。只有在完成之后你才会去苦恼该如何使用它。”
科学家的这种一往无前的探索精神,对于科技的发展无疑是好事,但同时也应该清楚地认识到这其中的隐患。Nick Bostrom曾说:”技术的飞速发展使我们将要面对的是’philosophy with a deadline‘”。确实是如此,随着人类的独有领地被一步步吞噬,很多哲学层面的问题也变得日趋紧迫。哲学家们花费了上千年讨论存在、道德、意识、自由意志等问题,至今没有达成共识。在柏拉图和笛卡尔的时代,这并不是什么大碍,因为所有的超智能体都只存在于人们的想象中;然而到了21世纪,这些争论正从哲学界慢慢转移到了人工智能界,未来超智能体的出现将使原先抽象的哲学问题变为具象的道德问题。
总的来说,我们希望自己创造出来的超智能体既很聪明,又能时刻恪守我们所制定的道德准则,这确实很像是在玩火。更何况这里面有个隐含的假设,我们一般所说的”聪明“有个前提,那就是这个”聪明“是能被使用在我们本身看重的事情上面的。【文章】第五部分中列举的”回形针极大化“的思维实验,如果真有AI疯狂地收集回形针,估计人们会认为其是”人工弱智“而非”人工智能“;而反过来,如果一个AI能帮我们疯狂地收集钱财,那我们必然会认为它很聪明(如果有AI能把整个地球改造成回形针工厂的话,那我真觉得这是绝顶聪明)。所以我们人类的需求很简单,不是要很聪明的AI,而是要”符合我们价值观“且“不会反噬我们”的聪明AI。所以关键问题是在将来我们的目标是否会与AI的目标合体,但这里又衍生出几个问题:如何赋予AI目标?随着AI变得越来越聪明,其目标还会保持下去吗?如果AI的智力超过了人类,它们还会遵守我们的目标吗?我们人类的终极目标又是什么?在真正的超智能体出现之前,这些都是必须要回答的问题。否则到时候我们的感受大概会与【文章】中的英国诗人Robert Southey类似 :
- 英国诗人Robert Southey宣称:“蒸汽加速了一个已经在运行的进程,却似乎变得过快了。”他担心“这种强大力量的发现”已经早于”我们知道如何正确使用它”。
人们之前对AI多年来的龟速进展大失所望,然而讽刺的是,现在很多人却认为它发展地太快了。本篇文章在冷静客观地评估后,我没有得出任何结论,反正明天太阳会照常升起,而50亿年之后地球也终究会毁灭,不是吗?
Reference:
[1] Ricardo J. Caballero. Creative Destruction
[2] Clayton Christensen. The Innovator's Dilemma
[3] McKinsey Global Institute. Artificial intelligence: The next digital frontier?
[4] McKinsey Global Institute. A Future that Works: Automation, Employment, and Productivity
[5] Accenture. How Artificial Intelligence Can Drive China’s Growth
[6] Max Tegmark. Life 3.0
[7] 弗里德里希·尼采.《查拉图斯特拉如是说》
[8] 伊曼努尔·康德.《纯粹理性批判》
[9] 亚瑟·叔本华.《人生的智慧》
[10] 盐野七生.《罗马人的故事》
[11]吴军.《数学之美》
[12] 特德·姜.《你一生的故事》
[13] 周志华.《机器学习》
[14] 曹天元.《量子物理史话》
[15] Aurélien Géron. Hands-On Machine Learning with Scikit-Learn& TensorFlow
[16] Richard S. Sutton & Andrew G. Barto. Reinforcement Learning: An Introduction
[17] Fei-Fei Li & Justin Johnson & Serena Yeung. CS231n
[18] Wikipedia. Basic Income
[19] 卡尔·马克思.《资本论》
[20] 米尔顿·弗里德曼.《自由选择》
[21] 让-雅克·卢梭.《社会契约论》
[22] 费·陀思妥耶夫斯基.《卡拉马佐夫兄弟》
[23] 列夫·托尔斯泰.《战争与和平》
[24] Wikipedia. Autonomous car
[25] TED-talk. The future we're building -- and boring
/