ai预测比特币未来5年行情
近年来,加密货币交易势头很足,从早期的比特币,发展到现在,全球加密数字货币已经超过 900 种,除了广为人知的比特币之外,还有以太币、瑞波币等。
Coinmarketcap 数据显示,截止 2017 年 6 月 28 日,共有 928 个加密数字货币,其中 722 个有市值统计,总市值 1061 亿美元。
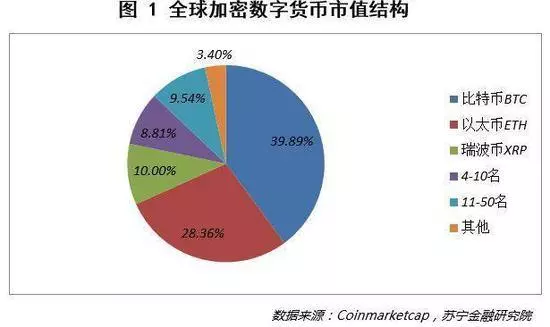
从市场结构来看,比特币市值 423.36 亿美元,占比 39.89%;以太币市值 301 亿美元,占比 28.36%;瑞波币市值 106 亿美元,占比 10%。前三大加密数字货币合计占比 78.25%,第 4-10 名合计占比 8.81%,第 11-50 名合计占比 9.54%,其余 672 个币种仅占 3.40%。
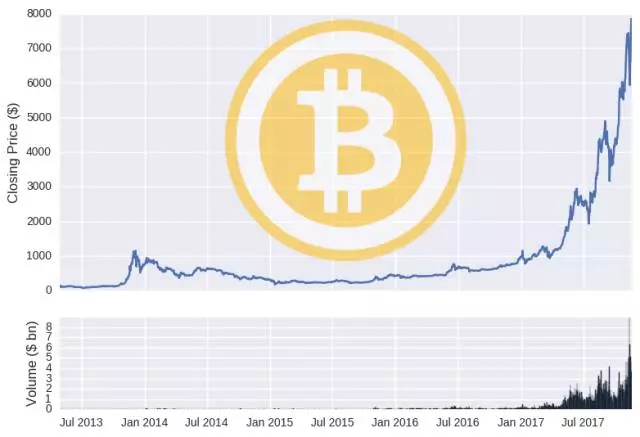
由于加密货币具有可以避开政府政策(好或坏)的去中心化性质,在一些当地货币对人们没有多大吸引力的国家,比特币开始被视为一个有效可行的替代品,加密货币价格也在经历下跌之后反弹。据 coingecko 数据显示,2017 年 11 月 21 日,比特币的价格已达 8120.85 美元。
数据获取长期短期记忆(LSTM)是一种特别适用于时间序列数据(或具有时间 / 空间 / 结构顺序的数据,例如电影、句子等)的深度学习模型,是预测加密货币的价格走向的理想模型。在建模之前,我们需要获取一些数据。因为需要在一个模型中结合多个货币币种,所以最好的方法是从同一个源头获取数据。在示例中,我们采用从 coinmarketcap.com 上获取的数据,以比特币和以太币为例,在导入数据之前,需要加载一些 Python 包。
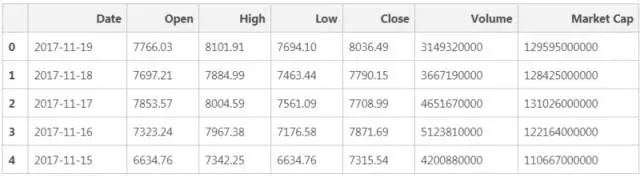
经过数据清理之后,我们得到上表。同理, 在 URL 中把“比特币”换成“以太币”,就可以轻松完成币种的转换。
为了证明数据是准确的,可以绘制比特币和以太币的价格和数量随着时间推移的图表。
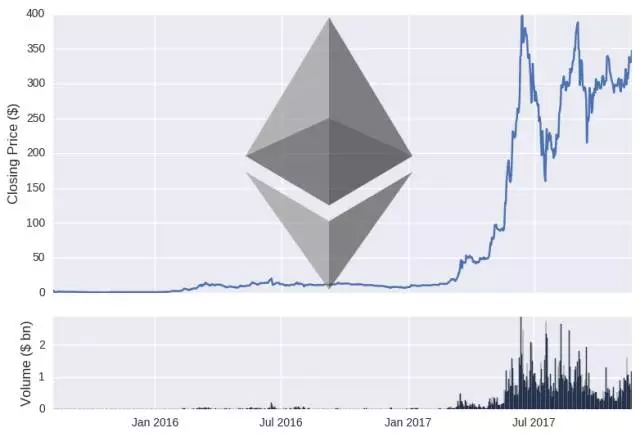
接下来,是数据建模的过程。在深度学习中,数据通常分为训练集和测试集,该 LSTM 模型建立在训练集上,在两个不同的时间段内进行训练,随后在不可见的测试集上进行评估。这里将截止日期设置为 2017 年 6 月 1 日(即模型将在该日期之前接受数据培训,并根据数据进行评估)。
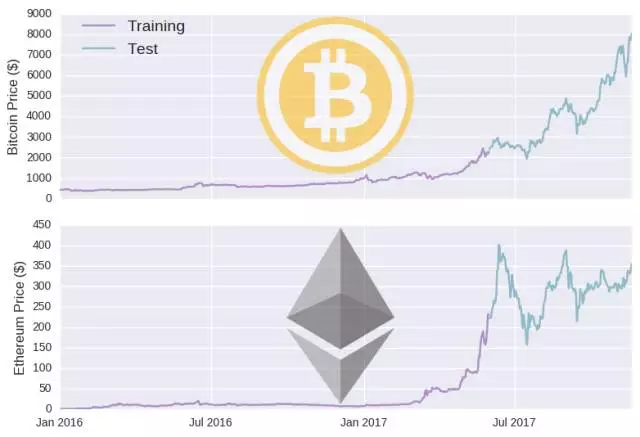
从上图中可以看到,训练时段通常与比特币价格相对较低的时期重合。因此,训练数据可能并不能代表测试数据,模型生成不可见数据的能力也相应大打折扣。为了顺利推进这个进程,我们先使用一个更简单的模型,设定比特币和以太币明天的价格与今天的价格相等(滞后模型),它的数学定义是:
![]()
股票价格通常被视为随机游动(random walk),将这个简单的滞后模型进行拓展,用以下数学术语来定义:
之后,我们将根据训练集确定为μ和σ,并将随机游动模型应用于比特币和以太币测试集。
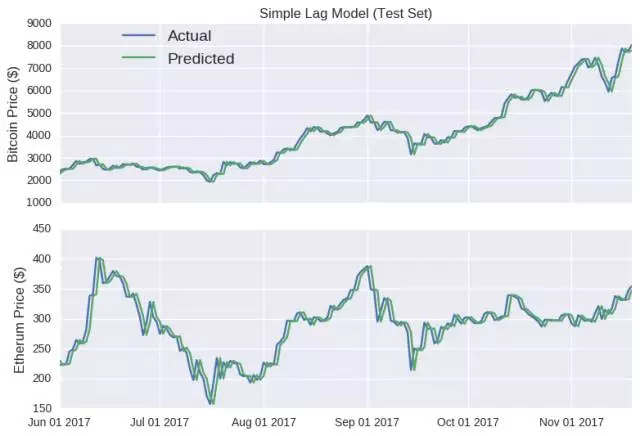
如图所示,除了价格的走向,该模型还能追踪比特币和以太币的实际收盘价格,甚至还能反映出六月中旬和八月下旬,以太币价格上升的趋势(随后下降)。如果在这个阶段宣布发行虚拟货币,可能会引导 ICO 超额认购,引起混乱。事实上,只能对未来很短一段时间做出预测的模型,往往是具有误导性的,因为后续的预测中并没有学会犯过的错误。因为模型是以真实价格为基础的,所以,无论这个错误有多大,在每个时间点的数据都将重置。而比特币随机游动特别具有欺骗性,因为 y 轴的比例相当宽,使得预测线显得相当平滑。
在评估时间序列模型时,通常进行单点预测,但测试多点预测的准确性效果可能更好。这样一来,先前预测发生的错误不会被重置,而是混在随后的预测中,用数学术语表示:
![]()
现在,我们用随机游动模型来预测整个测试集的收盘价格。随机模型预测对随机种子非常敏感。
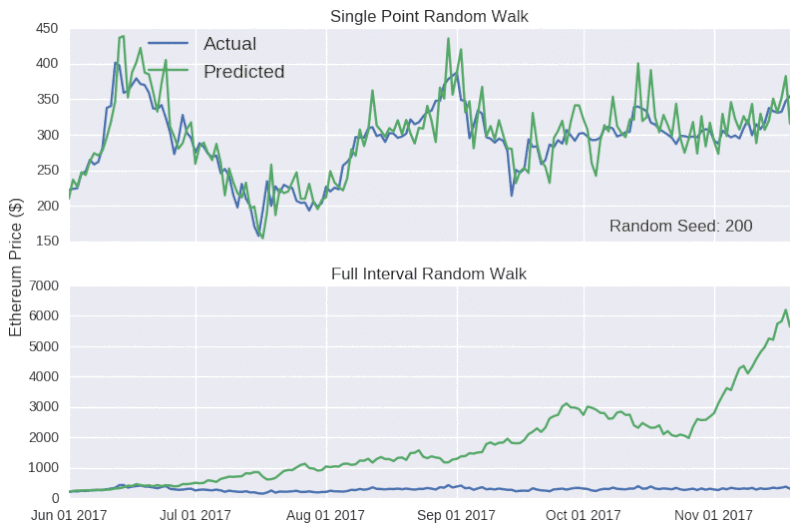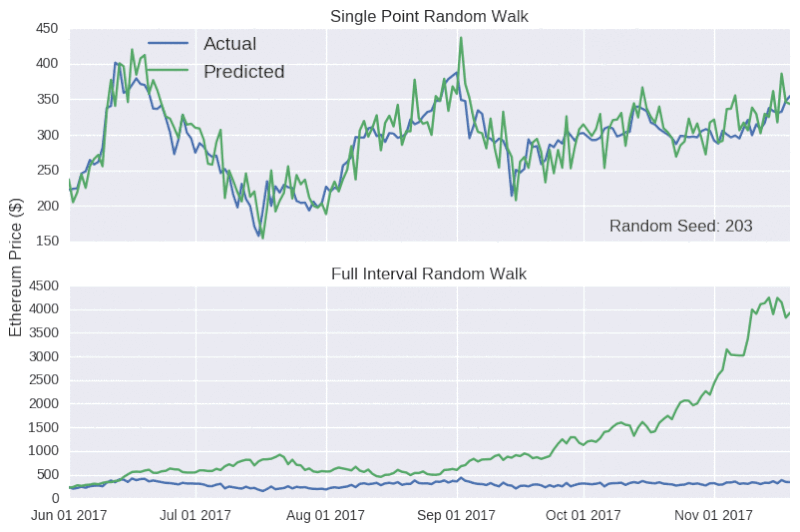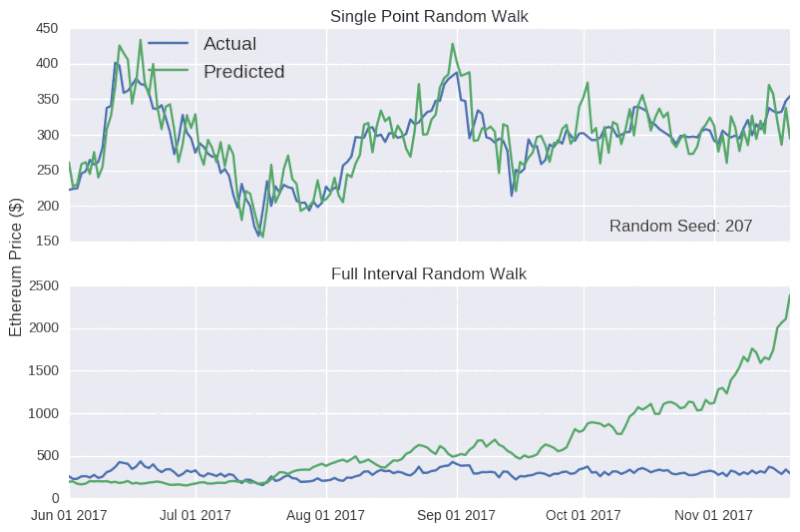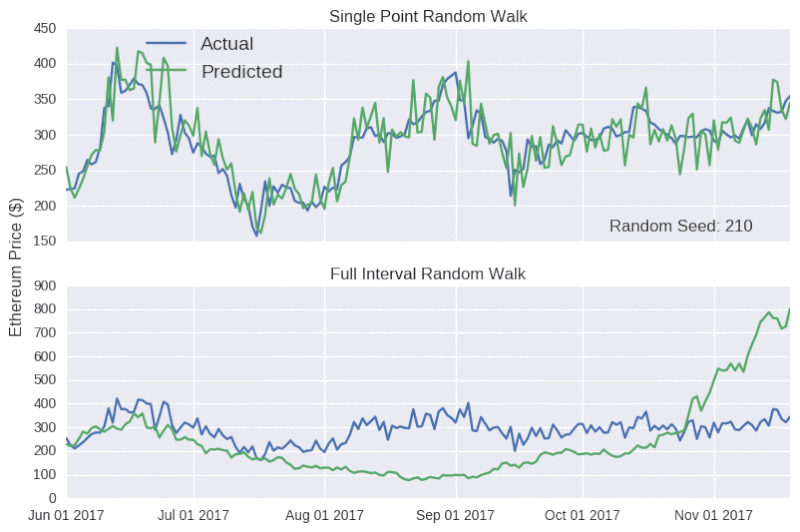
上表显示,单点随机游动预测的结果看起来相当准确,但背后却没有实质性的支撑数据。因此,对任何声称可以准确预测比特币价格的言论,我们应该持怀疑的态度,就像加密货币粉丝要小心不要被市场营销轻易带跑一样。
长短时记忆(LSTM)对于 LSTM,我们不需要从头开始构建网络,甚至不需要了解它,因为现成的就有包含各种深度学习算法(例如 TensorFlow、Keras、PyTorch 等)的标准使用安装包。 以 Keras 为例,这种算法对非专家学习人员来说是最直观的。
![]()
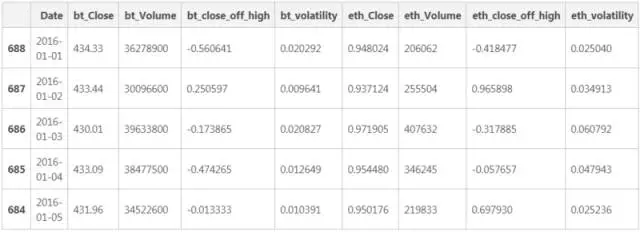
首先,创建一个名为 model_data 的新数据框,删除一些列(开盘价、每日高点和低点),并重新加入一些列。close_off_high 表示当天收盘价格和价格高点之间的绝对差值,-1 和 1 的值分别表示收盘价与每日低点和每日高点相等,波动率列表示高价和低价之差除以开盘价。因为 model_data 是按照时间顺序排列的,这些信息不会被输入到模型中,所以并不需要日期栏。
该 LSTM 模型使用以前的数据(比特币和以太币)来预测第二天的特定货币的收盘价格。我们必须先确定之前哪些日期的数据是可以用的,比如选择 10 天的数据就比较合理。我们需要构建一些由连续 10 天数据(称为窗口)组成的小数据框,第一个窗口由训练集的第 0-9 行(Python 为零索引)组成,第二个窗口由 1-10 行组成,依次类推。选择一个规模较小窗口意味着我们可以为模型提供更多的窗口,但缺点是模型可能没有足够的信息来检测复杂的长期行为(如果存在)。
在这些数据列中,数值变化的范围非常大,其中一些值在 -1 和 1 之间,另一些则在达数百万,而这是深度学习模型并不“喜欢”的。因此,我们需要对数据进行规范化处理,以保证输入具有一定的一致性。通常情况下,我们需要 -1 和 1 之间的值,off_high 和 volatility 列的值没什么问题,但对于剩余的列,需要将输入标准化为窗口中的第一个值。
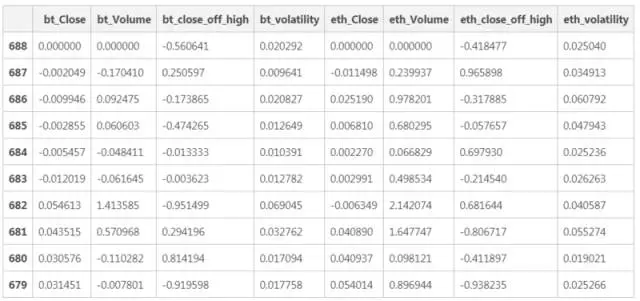
这个表格是数百个类似 LSTM 模型输入列表的其中一个。经过对一些列进行归一化处理后,它们的值在第一个时间点等于 0。为了预测相对于这个时间点的价格变化,需要建立 LSTM 模型。Keras 很轻松就可以做到这一点,只需将组件堆叠在一起就可以了。

所以,build_model 函数建了一个空白的模型,称为 model(model = Sequential),并添加了一个 LSTM 层。该层已经过调整,以适应输入(n×m 个表格,其中 n 和 m 分别表示时间点 / 行和列的数量)。该函数还能够调用更加通用的神经网络功能,如退出和激活。 现在,我们只需要指定放置在 LSTM 层上的神经元的数量,以及训练的数据。
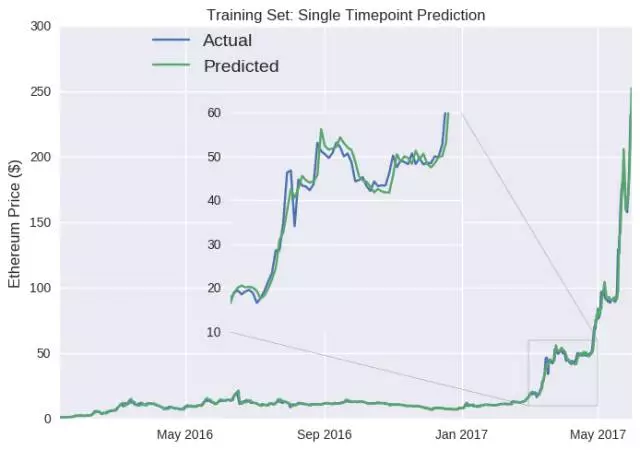
那么,LSTM 模型预测以太币明天收盘价格的表现如何呢? 首先检测其在训练集上的表现(2017 年 6 月之前的数据)。代码下面的数字表示,在第 50 次训练迭代之后,模型训练集的平均绝对误差(mae)。我们可以将模型输出视为每日收盘价,而不是相对变化。
可以看到,这个模型预测数据的准确度非常高,因为其可以学习错误源并加以调整。事实上,实现训练中错误为零并不难,在数百个神经元中进行数千次迭代(即过度拟合)就可以。
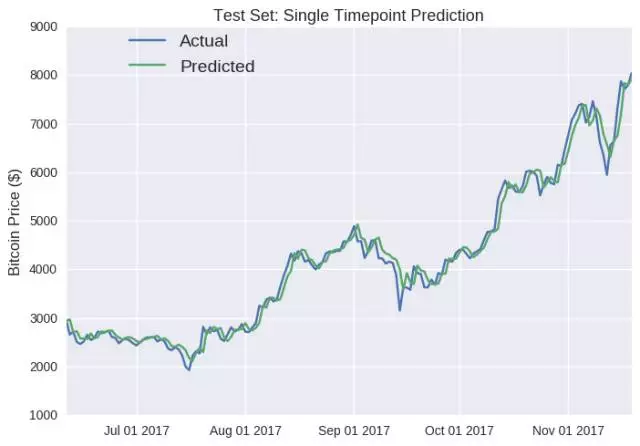
除了单点预测的误导性之外,LSTM 模型在未经训练和预处理的测试集上表现良好,预测的价格通常与一天后的实际价格相差无几(例如 7 月中旬价格下跌)。但这个模型最明显的缺陷是,当价格突然上涨时(例如六月中旬和十月),它不能检测到数值低迷的状况,在峰值就更明显了。
同理,为比特币建立的类似 LSTM 模型测试如下:
正如前述,单点预测同样具有误导性。下图是 LSTM 模型对未来五年加密货币价格的预测:
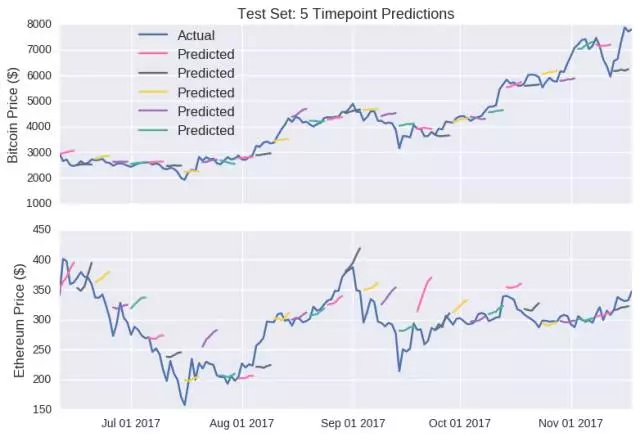
这个预测与之前有着细微的差别,价格的预测并不是朝向单一方向变动。在单点预测上,LSTM 模型与随机游动模型一样,对随机种子的选择也很敏感(模型权重最初是随机分配的)。为对两个模型进行比较,每个模型运行 25 次,以获得模型误差的估值,此误差值被计为测试集中实际和预测收盘价之间的绝对差值。
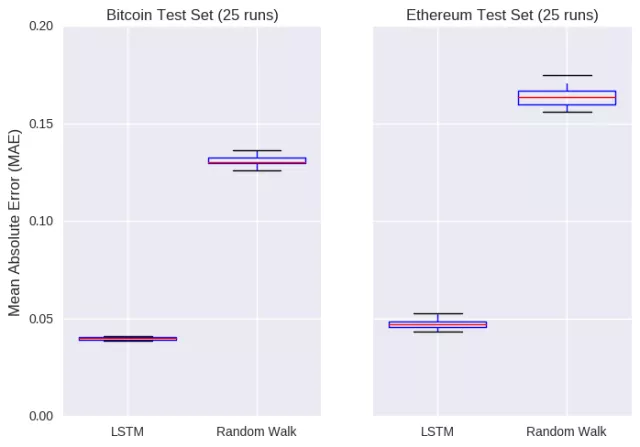
从这个角度来看,人工智能的蓬勃发展不是没有理由的:LSTM 模型对比特币和以太币价格预测与实际价格的平均误差仅分别为 0.04 和 0.05,完败随机游动模型。
然而,完败随机游动模型并没有多了不起,将 LSTM 模型与更势均力敌的时间序列模型,如加权平均、ARIMA 或 Facebook 的先知算法等进行比较才更有意义。另一方面,LSTM 模型还可以进行更多改进,例如增加更多层或神经元、改变批量规模、学习速率等。
用于预测货币价格最完美的模型是:
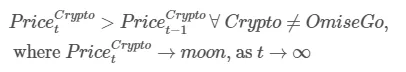
也许,我们不应该太迷信深度学习在预测货币价格变化方面的作用,因为我们不能忽略这样一个事实:最完美的框架其实来源于人类的智慧,而加密货币的升值和贬值,永远逃离不开市场规律的摆布。