kubelet驱逐与buffer/cache的计算关系
线上的pod出现迁移,查看kubelet日志,发现主机内存存在压力,所以导致kubelet驱逐pod。同时查看主机的内存占用,确实发现主机的可用内存小于预留资源,所以发生pod迁移貌似可以理解。同时也发现系统的buffer/cache占用有点多,虽然知道linux在内存紧缺的时候会回收部分buffer/cache,且之前曾分析过《docker内存监控与压测》一文,对docker容器监控做过分析,因此想了解kubelet在做驱逐(内存压力)时与buffer/cache的计算关系。
查看kubelet关于系统资源限制的配置

查找kubelet代码中关于驱逐相关代码
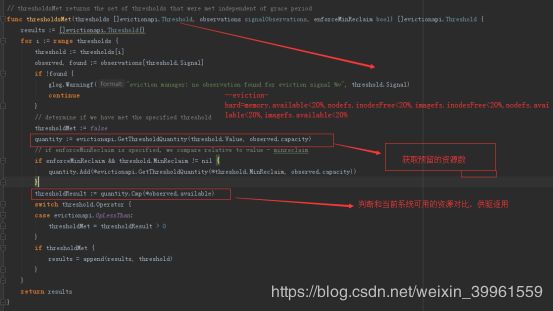
makeSignalObservations根据获取的运行时资源使用数据完成result变量初始化,最后返回result变量,包括memory、nodeFs、inodes、imageFS等资源信息。
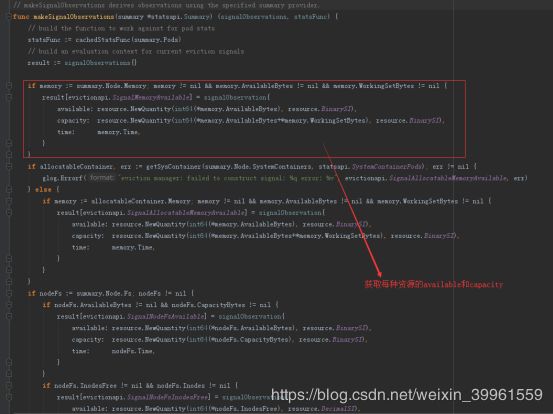
关注memory中capacity和available值的,其中
capacity = memory.AvailableBytes+memory.WorkingSetBytes
available= memory.AvailableBytes
这里memory的值最终是通过cadvisor计算得到的,这里通过kubelet的接口调用查询:
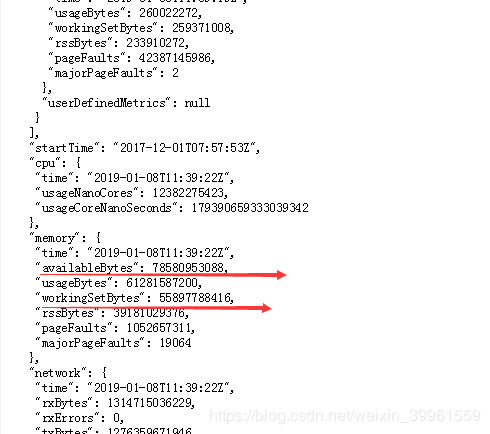
查询cadvisor的ui页面,这两个数据是一致的
既然代码里提到workingSet,且workingSet的数据来源于cadvisor,所以查看cadvisor中关于workingSet的计算公式是怎样的,在github上查找得到以下代码:
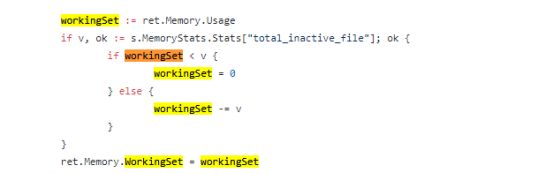
这里workingSet的计算是先比较memory.memory.usage_in_bytes的大小是不是比memory.stats里面的total_inactive_file小,如果没有,就减去total_inactive_file的值,最后为workingSet的值,这部分的值我们可以认为是linux占用的hot(正在使用)内存值(容器同理)。
验证cadvisor的workingSet计算和buffer/cache的关系
产生cache的情况可能有很多,目前通过创建文件来验证cache。选择一台linux主机执行命令:
dd if=/dev/zero of=test bs=1M count=1000
它会生成一个1000M的test文件,文件内容为全0(因从/dev/zero中读取,/dev/zero为0源),在生成文件之前,先记录系统的内存使用还有kubelet收集的内存参数(由于命令执行有先后顺序,忽略字节数微小的差异):
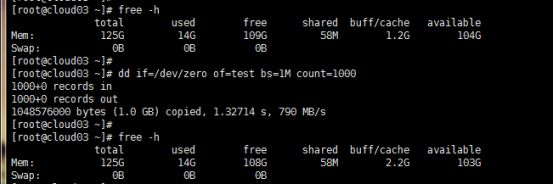
A) free -h查看相关参数记录

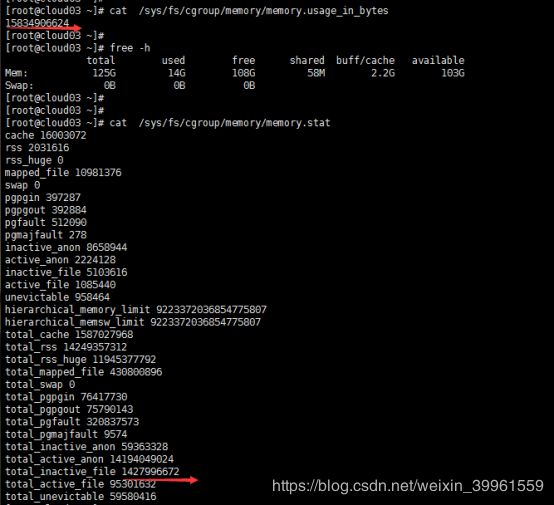
B) memory.memory.usage_in_bytes和memory.stats的参数记录

C) kubelet收集的内存参数:
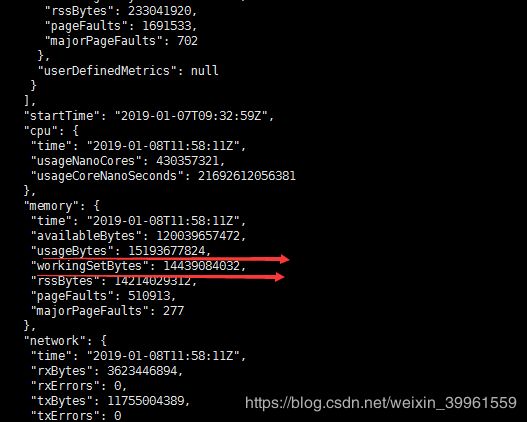
通过linux的memory.memory.usage_in_bytes减去memory.stats的total_inactive_file的值后发现和kubelet搜集的workingSet差不多一致。
这次执行上述dd命令看相关参数值得变化(再次执行的时候cache从1.6g变成1.2g):
A) free -h查看相关参数记录
B) memory.memory.usage_in_bytes和memory.stats的参数记录
C) kubelet收集的内存参数:
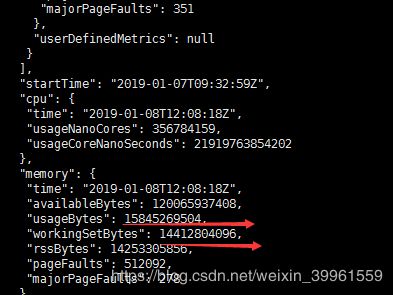
再次执行时由于cache已经从1.6g变为1.2g,但是当我们生成一个1g的文件时,这个是算进cache里的,而stats文件里的total_inactive_file也发生变化,其实这1g的大小是直接加进total_inactive_file的值中。
计算两次生成1g文件前后,linux所占用的workingSet并没有发生什么变化(20多M)。
*注:对于memory.stat的部分参数的描述如下
rss属于进程的数据,如Stacks,Heaps等,可以被进一步分解为(必要时,非活动内存可以交换到磁盘)
- 活动内存(active_anon)
- 非活动内存(inactive_anon)
cache缓存存储器存储当前保持在内存中的磁盘数据。可以进一步分解为(必要时,首先回收非活动内存) - 活动内存(active_file)
- 非活动内存(inactive_file)
总结
通过从源码分析kubelet关于memory驱逐的代码,kubelet只考虑当前系统(容器同理)的workingSet的使用量,而总的容量为当前可用容量+workingSet的值,根据这个总的容量值计算我们在kubelet里面设置的资源预留(百分数),如果当前系统的可用资源小于预留值,则kubelet将开始驱逐逻辑。