二次开发sklearn包-Kmeans
前言
Kmeans是一种聚类算法,sklearn 也给出了其API,很方便我们调用,关于其API的操作,笔者这里也给出了一个小例子,感兴趣的可以看一下:https://blog.csdn.net/weixin_42001089/article/details/79951166
但是我们知道Kmeans算法是基于距离(如欧式距离)作为评判指标进行聚类的,现实中我们的需求千差万别,比如我们的项目可能需要一种新的指标来作为评判指标进行聚类,这时候就需要修改sklearn的部分源码来达到我们的目的
注意本文的最终目的在于:分析如何根据自己的需求修改sklearn源码并加以利用的整个流程
至于本文要修改的是Kmeans,参考本文可扩展到其它源码修改,下面的例子仅供参考
背景需求
笔者要解决的样本类型如下:
import numpy as np
result = np.random.randint(0, 2,(3,10))
print(result)[[0 1 0 1 0 0 0 0 1 0]
[0 0 0 0 0 1 0 0 0 1]
[1 1 1 1 0 1 0 1 0 0]]这里给出了3个样本,每个样本有10个特征,特征值仅限于0和1
来衡量两个样本之间的密切关系我们不打算采用欧式等距离,而是采用tanimoto相似度
由于tanimoto相似度不是本文重点,这里就不做解释啦,感兴趣的自行百度,笔者这里直接调用的是e3fp包下的tanimoto API
from e3fp.fingerprint.metrics.array_metrics import tanimoto
tanimoto(result)array([[ 1. , 0. , 0.28571429],
[ 0. , 1. , 0.14285714],
[ 0.28571429, 0.14285714, 1. ]])其返回的是一个矩阵,如这里第一个样本和第三个样本的相似度是0.28571429
所以我们的需求就是想要以tanimoto相似度来作为评判指标
初始源码
首先我们需要下载sklearn 源码:
https://github.com/scikit-learn/scikit-learn
笔者这里是下载的压缩包,解压后会得到一个scikit-learn-master文件
下载好后我们要修改的部分在scikit-learn-master\sklearn\cluster文件夹下

其主框架在k_means_.py中,我们接下来的工作就是从这里入手,一步步进行修改
修改源码
首先明白我们需要修改哪些部分,根据kmeans思想,大概包括如下:
一 :在判断某一个样本属于哪一个类时,这部分我们要改,改的就是其评判指标
二:在更新中心类时,我们要改,因为之前的Kmenas是采用平均值,而这里我们显然不能这样,因为我们最后的类特征中只能是0和1,平均以后可能出现小数,这里的做法是看0和1的个数,比如本类中50个样本,那么我们根据这50 个样本更新中心点是这样做的:先看所有样本的第一个特征,假设有40个样本的第一个特征是1,有10个样本的第一个特征是0,那么我们新更新出来的中心点的第一个特征就是1,依次类推得到新更新中心点的第二,三,四,,,,,的特征值
三 :中心点的初始化
同时需要主要的是,原始代码中有大量的sparse.issparse来处理稀疏矩阵,很显然当前需要有可能是稀疏的,但是我们不希望有任何的压缩操作,于是我们屏蔽掉了sparse.issparse的代码和相关操作。
在使用sklearn的Kmeans接口中有两个API供我们调用
from sklearn.cluster import MiniBatchKMeans, KMeans打开k_means_.py,会看到其下有两个类即分别是MiniBatchKMeans, KMeans 那么我们就分别修改这两部分。
(1)KMeans
该类下的fit方法主要就是使用了k_means函数,所以我们着重看一下该函数
该函数下有algorithm参数,根据其不同调用不同的函数,由于笔者的数据量比较大,而且要使用并行化,所以这里就直接将kmeans_single = _kmeans_single_elkan,而不会选择kmeans_single_lloyd两者的区别就是:"elkan" for dense data and "full" for sparse data.,所以我们这里直接修改使用 _kmeans_single_elkan即可,接下来就是并行化执行 _kmeans_single_elkan,所以我们来看一下 _kmeans_single_elkan函数:
首先是初始化中心点:
centers = _init_centroids(X, n_clusters, init, random_state=random_state,
x_squared_norms=x_squared_norms)_init_centroids-》_k_init
--------------------------------------------------------------------------------------------------------------------
其中里面用到了euclidean_distances函数,其在scikit-learn-master\sklearn\metrics\pairwise.py中
其参数是X,Y,作用就是计算X和Y的距离,原始计算方法:
dist(x, y) = sqrt(dot(x, x) - 2 * dot(x, y) + dot(y, y))
这里我们就简单改为tanimoto(X,Y)就好
--------------------------------------------------------------------------------------------------
原来是距离越小越好,现在是相似度越大越好于是如下部分也进行了修改:

接下来主要就是调用了_k_means_elkan.pyx下的k_means_elkan
<1>首先修改每一个样本属于哪一个类的部分源码如下:
for iteration in range(max_iter):
if verbose:
print("start iteration")
labels_ = np.argmax(tanimoto(X_,centers_),axis=1).astype(np.int)说白了就是判断每个样本应该属于哪一类,做法就是遍历每一个类,看样本与其相似度,选择相似度大的那一个类作为自己的label
<2>其次修改更新中心点源码的部分如下:
该部分源码是_k_means.pyx下的_centers_dense函数中完成的,修改如下:
for center_idx in range(n_clusters):
center_mask = labels == center_idx
length = X[center_mask].shape[0]/2
centers[center_idx] = np.sum(X[center_mask],axis=0)
centers[center_idx] = np.array(list(map(lambda x: 1 if x>length else 0, centers[center_idx])))
return centers
这里的做法是对每一列(特征)进行加和,最后和总长度比较,比如某一特征下有10个样本为1,5个样本是0,那么加和后是10,总长度的一半是7.5,因为10大于7.5,所以我们最后改中心点的该特征值是1
<3>再者修改
# reassign centers
centers_ = new_centers
center_shift_total = np.sum(center_shift)/len(center_shift)
if center_shift_total > tol:
if verbose:
print("center shift %e within tolerance %e"
% (center_shift_total, tol))
break当新产生的中心点和旧的中心点相似度过高就可以提前结束迭代了,即差不多收敛了。这里将tol默认值修改为了0.95
_kmeans_single_elkan的最后我们修改了部分如下:
inertia = np.einsum('ii', tanimoto(X,centers[labels]))/X.shape[0]即所有样本点到其中心的距离和
除此之外还的修改k_means函数最后的 best的点:是最大相似度
best = np.argmax(inertia)(2)MiniBatchKMeans
看该类下的fit方法
其init继承于KMeans,它的思想就是每次随机取一部分子数据集进行聚类
初始化中心点同上
if best_inertia is None or inertia > best_inertia:这里要改为大于,因为我们认为相似度越大越好
接下来就是两个比较重要的函数就是:
_mini_batch_step 和_mini_batch_convergence
其中可以简单将_mini_batch_step看做是当前子数据集上面判断每一个样本从属于哪一个类,以及中心点的更新
_mini_batch_convergence看做是判断是否需要提前停止迭代
先看_mini_batch_step函数:
其下使用_labels_inertia函数来判断每一个样本从属于哪一个类,方法如上,不再解释
中心点更新也同上
计算新旧中心点偏移量
center_shift_total = np.einsum('ii', tanimoto(old_center_buffer,centers))/old_center_buffer.shape[0]_mini_batch_convergence函数如下
注意这里的tol就是上面center_shift_total要参考的,因为center_shift_total已经归一化啦,所以这里就没必要使用batch_size进行归一化
if tol > 0.0 and ewa_diff >= tol:
if verbose:
print('Converged (small centers change) at iteration %d/%d'
% (iteration_idx + 1, n_iter))
return True最后还有一个
if self.compute_labels:
self.labels_, self.inertia_ = \
self._labels_inertia_minibatch(X, sample_weight)
记得把_labels_inertia_minibatch函数最后改为:
return np.hstack(labels), np.sum(inertia)/len(inertia)其他一些细枝末节的东西就不说啦,以上就是最核心的东西
重新编译
现在就需要重新编译啦,笔者的环境是使用的anaconda ,直接打开Prompt,编译即可:

测试
from sklearn.cluster import MiniBatchKMeans, KMeans
import numpy as np
mbk1 = KMeans(init = 'k-means++', n_clusters = 3,verbose = 0,n_jobs=1)
mbk2 = MiniBatchKMeans(init = 'k-means++', n_clusters = 3,batch_size = 11,verbose = 0)
# result = np.random.randint(0, 2,(50,10))
result = np.array([[1,1,1,1,1,1,1,1,1,1,0,0],
[1,1,1,1,1,1,1,1,1,1,0,1],
[1,1,1,1,1,1,1,1,1,1,1,0],
[1,1,1,1,1,1,1,1,1,0,1,0],
[1,1,1,1,1,1,1,1,1,0,0,1],
[0,0,0,0,1,1,0,0,0,0,0,0],
[0,0,0,0,1,0,1,0,0,0,0,0],
[0,0,0,0,1,1,0,0,0,0,0,0],
[0,0,0,0,0,0,0,0,0,1,1,0],
[0,0,0,0,0,0,0,0,0,1,0,1],
[0,0,0,0,0,0,0,0,0,0,1,1]])
print(result)
为了验证效果,我们人为的构造3类数据,从上面也可以清楚的看到前5个样本属于一类,接下来3个属于一类,最后3个属于一类
mbk1.fit(result)
mbk2.fit(result)
print(mbk1.inertia_)
print(mbk2.inertia_)
print(mbk1.cluster_centers_)
print(mbk2.cluster_centers_)
print(mbk1.predict(result))
print(mbk2.predict(result))![]()
from e3fp.fingerprint.metrics.array_metrics import tanimoto
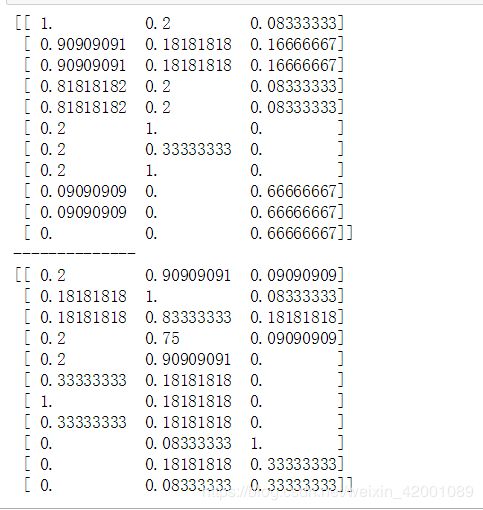
print(tanimoto(result,mbk1.cluster_centers_))
print('--------------')
print(tanimoto(result,mbk2.cluster_centers_))