sqoop2安装与配置以及常见问题
一、sqoop2的安装:
安装sqoop2前,首先安装配置好Hadoop,sqoop2是在Hadoop的基础上运行的。
1.sqoop2的版本:sqoop-1.99.7-bin-hadoop200.tar.gz
解压缩即可: tar -zxvf sqoop-1.99.7-bin-hadoop200.tar.gz
2.环境变量的配置:vi /etc/profile
添加(根据自己的安装路径):
- export SQOOP_HOME=/data/software/sqoop-1.99.7-bin-hadoop200
- export CATALINA_HOME=$SQOOP_HOME/server
- export PATH=$SQOOP_HOME/bin:$PATH
3.修改Hadoop下的core-site.xml文件
添加:
特别要注意的是sqoop2是提交任务的用户名,这里要改成你提交任务的用户,否则会报
org.apache.hadoop.security.authorize.AuthorizationException: User: root is not allowed to impersonate root
-
hadoop.proxyuser.sqoop2.hosts -
* -
hadoop.proxyuser.sqoop2.groups -
*
4.配置文件vi conf/sqoop.properties
(1)把$HADOOP_HOME替换为自己实际路径
- org.apache.sqoop.submission.engine.mapreduce.configuration.directory=$HADOOP_HOME/etc/hadoop
(2)将以下注释放开
- org.apache.sqoop.security.authentication.type=SIMPLE
- org.apache.sqoop.security.authentication.handler=org.apache.sqoop.security.authentication.SimpleAuthenticationHandler
- org.apache.sqoop.security.authentication.anonymous=true
(3)创建目录mkdir /home/hadoop/sqoop/logs
将@LOGDIR@替换为/home/hadoop/sqoop/logs;BASEDIR替换为/home/hadoop/sqoop
5.下载mysql JDBC Driver 到sqoop/server/lib 下
- cp mysql-connector-java-xxx.jar sqoop/server/lib (若安装了hive,在/home/hadoop/Hive/apache-hive-2.3.3-bin/lib目录下)。
6.初始化:bin/sqoop2-tool upgrade
7.启动/关闭sqoop server:
sqoop.sh server start/stop
8.启动交互命令:
sqoop2-shell 出现sqoop:000>
二、sqoop2的应用
1.启动Hadoop和sqoop server,
查看进程命令jps:可以看到以下进程
- 2898 SecondaryNameNode
- 3219 NodeManager
- 2643 NameNode
- 3109 ResourceManager
- 2742 DataNode
- 5798 SqoopShell
- 10153 Jps
- 3644 SqoopJettyServer
2.设置端口
set server --host localhost --port 12000 --webapp sqoop
3.创建连接(show connector)
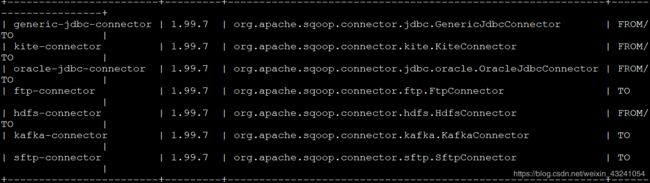
(1)创建MySQL连接
create link -connector generic-jdbc-connector
Creating link for connector with name generic-jdbc-connector
Please fill following values to create new link object
Name: First Link 自己起连接名
Database connection
Driver class: com.mysql.jdbc.Driver
Connection String: jdbc:mysql://localhost:3306/test test为数据库
Username: root
Password: ******
Fetch Size: 100
Connection Properties:
There are currently 0 values in the map:
entry#
SQL Dialect
Identifier enclose: 注意 这里不能直接回车!要打一个空格符号!因为如果不打,查询mysql表的时候会在表上加上“”,导致查询出错!
New link was successfully created with validation status OK and name First Link
#HDFS Link
sqoop:000> create link -connector hdfs-connector
Creating link for connector with name hdfs-connector
Please fill following values to create new link object
Name: Second Link
HDFS cluster
URI: hdfs://xiaobin:9000/
Conf directory: /home/hadoop/etc/hadoop hadoop配置文件目录
Additional configs::
There are currently 0 values in the map:
entry#
New link was successfully created with validation status OK and name Second Link
(2)创建job
create job -f First Link -t Second Link
Creating job for links with from name First Link and to name Second Link
Please fill following values to create new job object
Name: Sqoopy 自己起job名
Database source
Schema name: test 数据库名
Table name: emp 表名
SQL statement:
Column names:
There are currently 0 values in the list:
element#
Partition column:
Partition column nullable:
Boundary query:
Incremental read
Check column:
Last value:
Target configuration
Override null value:
Null value:
File format:
0 : TEXT_FILE
1 : SEQUENCE_FILE
2 : PARQUET_FILE
Choose: 0
Compression codec:
0 : NONE
1 : DEFAULT
2 : DEFLATE
3 : GZIP
4 : BZIP2
5 : LZO
6 : LZ4
7 : SNAPPY
8 : CUSTOM
Choose: 0
Custom codec:
Output directory: /test/sqoop Hadoop的目录 注意必须为空,报错Invalid input/output directory - Output directory is not empty
Append mode:
Throttling resources
Extractors:
Loaders:
Classpath configuration
Extra mapper jars:
There are currently 0 values in the list:
element#
New job was successfully created with validation status OK and name Sqoopy
(3)启动/关闭/查看job
- start/stop/status job -name Sqoopy -name也可改为-n
- start job -name Sqoopy -s 加-s,显示执行进度
(4)浏览器查看状态
http://192.168.159.11:8088
三、常见错误
(1)org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
原因:hadoop的lib库没有设置环境变量,添加环境变量如下:
- export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
- export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
(2)Message: GENERIC_JDBC_CONNECTOR_0016:Can't fetch schema -
原因:配置job时,Schema name:配置错误导致的,Schema name在MySQL中为数据库名,在Oracle中为用户名。
(3)User: root is not allowed to impersonate root
原因:未配置文件core-site.xml,添加:
-
hadoop.proxyuser.sqoop2.hosts -
* -
hadoop.proxyuser.sqoop2.groups -
*
(4)Message: GENERIC_HDFS_CONNECTOR_0007:Invalid input/output directory - Unexpected exception
原因:文件夹没有权限或者无此文件夹,或者文件夹不为空。
(5)Message: COMMON_0023:Unable to create new job data
原因:可能创建的job名已经存在。
(6)sqoop:000> stop job -n sql_hdfs
Exception has occurred during processing command
Exception: org.apache.sqoop.common.SqoopException Message: MAPREDUCE_0003:Can't get RunningJob instance -
原因:由于没有启动historyserver引起的
解决办法:在mapred-site.xml配置文件中添加:
mapreduce.jobhistory.address
hadoop-allinone-200-123.wdcloud.locl:10020
执行命令:mr-jobhistory-daemon.sh start historyserver
(7)出现以下情况:
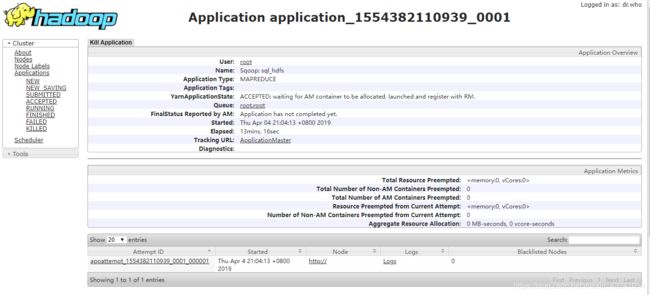
ACCEPTED: waiting for AM container to be allocated, launched and register with RM.
这种情况可能是因为资源有限,保证硬盘使用率在90%以下。