驾考X典API参数分析,主讲分析技巧涵盖网络原理,依然满满的干货
前言
朋友想抓取驾考X典的题库,本以为非常简单,实际尝试之后发现另有玄机,写下此篇记录分析过程,并且会讲讲我对网络的理解
准备
- 一定的计算机知识,熟悉基本的高级编程语言语法
- Chromium内核浏览器,推荐使用Edge或Chrome
- Fiddler一个非常好用的抓包工具
WEB中的API是什么意思
在计算机领域中API全称是Application Programming Interface(应用程序接口),接口就是一种规约,举个生活中常见的例子:电器需要从插座中获取电能,插座分为双相和三相,那电器的插头就必然是双相或三相的。双相和三相就是一种规约,可以理解为一种接口,只有插头符合插座定义的接口标准(双相或三相)就能从中获取电能。
放到计算机WEB领域里,我们通过浏览器访问一个URL就能获得资源(可以是文本,音频,视频等),这样的URL我们称之为API
例如我们日常都会使用的搜索引擎,他的URL是这样的:
https://www.baidu.com/
那我们尝试搜索123,可以看到如下的URL
https://www.baidu.com/s?wd=123&rsv_spt=1&rsv_iqid=0xff96bdc80000e19e&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb&rsv_sug3=4&rsv_sug1=1&rsv_sug7=100&rsv_sug2=0&rsv_btype=i&inputT=325&rsv_sug4=1178
可以看出https://www.baidu.com/s?wd=123这里有个wd参数,它的值正是我们搜索的内容,为什么我们访问了这个URL就能获得相应的搜索结果呢?这就需要网络原理知识了,我会在文章后部讲两句。
实践
通过上文我们已经明白了API是什么意思(能获取资源的URL),来看看我们这次实践的目标,驾考X典
我们打开科目一考试的顺序练习,看到浏览器上方地址栏中的URL如下
https://www.jiakaobaodian.com/mnks/exercise/0-car-kemu1-tianjin.html?id=800000
我们的目的是要获取所有的题目和答案,那自然是开Fiddler抓包分析了(此处默认读者有一定基础知识,了解爬虫相关的知识,不太明白的读者可以先看文章后部的基础知识讲解)
打开Fiddler,刷新页面抓包,猜测题目主体和答案会通过JSON格式返回(因为JSON是现在的常用格式),我们先过一遍所有返回结果是JSON的包
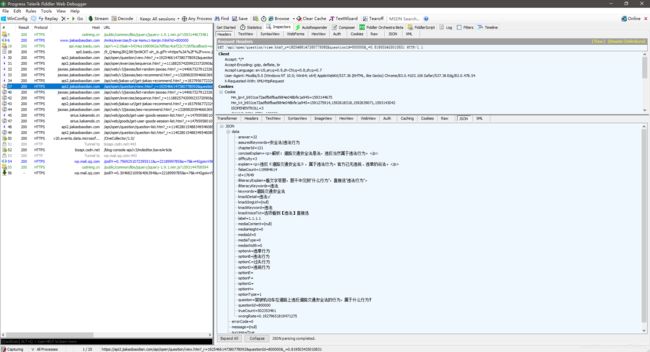
可以看到,这个包的返回体中就包含了题目内容和答案
我们来看看这个请求头
GET /api/open/question/view.htm?_r=1925466147380778092&questionId=800000&_=0.819503435010831
很明显questionId代表了题目的ID,还另外有两个不知道做什么用的参数,把这条请求拖入Fiddler的Composer界面,这里可以直接向服务器发送我们构造的请求,我们尝试删除掉另外的两个参数之后发送看看还能否正确的请求到资源
请求头:
GET /api/open/question/view.htm?questionId=800000 HTTP/1.1
返回体:
{"data":null,"errorCode":507,"message":"URL H5\u7B7E\u540D\u9519\u8BEF","success":false}
返回体中的\u7B7E\u540D\u9519\u8BEF是Unicode编码,我们将它解码结果为签名错误
可以推断另外两个参数应当是用于验证的,不符合规范的服务器将不会提供服务(返回资源)
那我们的目的就是找到这两个参数是如何创建的,首先明确浏览器(客户端)发出请求的逻辑都是通过JS来实现的,那我们就需要定位这段产生验证参数的函数
之前的文章说过,浏览器自带的开发者工具实乃神器,我们在驾考X典页面祭出开发者工具,切换到网络选项卡,重新刷新页面,抓包

找到我们之前看到的返回内容是题目主题的请求,切换到发起程序,这个页面中我们能看到是谁发起了这个请求
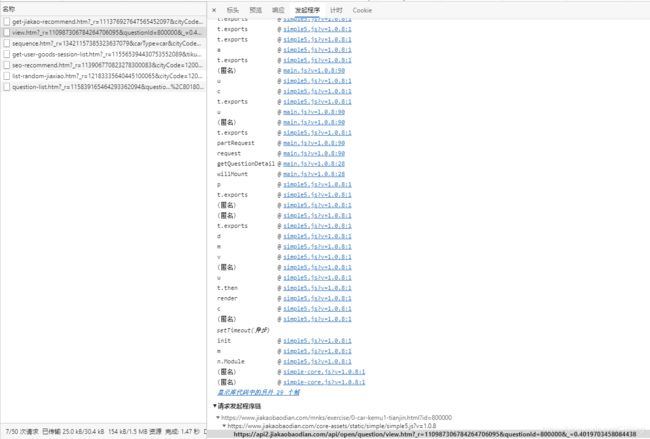
从下面的请求发起程序链能看到,这个请求是由一个叫simple5.js的文件发起的
我们点击请求调用堆栈的第一条就可以跳转到这个js文件中
最终只有一行代码说明JS文件是经过了压缩的,点击优质打印,从函数名变量名我们也能看出文件是经过混淆的
由于是压缩过的文件,我们无法通过点击调用堆栈的第一条来找到具体函数,因为都是在JS第一行发起的
我们不得不使用其他方法来确定是哪个函数法出了请求,自然而然的我们想到断点调试法,可我们断点放在那里呢?总不能从头开始调试吧?这就要说到开发者工具中的一个功能了,XHR断点,也就是在发出网络请求的下断点,我们点击加号创建如下断点
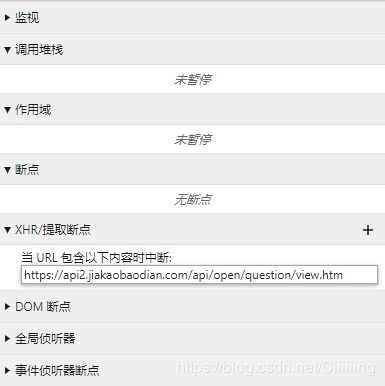
重新刷新页面
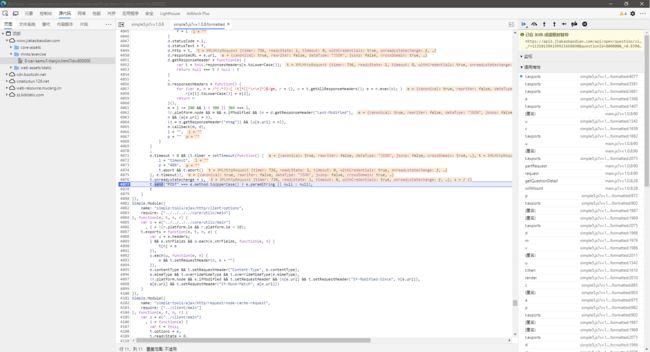
成功在网络请求发出的前一步中断了下来,在右边的作用域中,查看本地变量的值,可以看到,在发出之前,另外两个参数已经被附加上了

那我们就需要找出是在哪里附加的,从条用堆栈中选择上一条,并继续查看本地变量


依然是附带了参数的,重复上述步骤,找到请求不带参数的一层
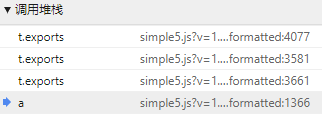

这一层中,请求还没有附加上参数,也就是说,请求会在这之后的过程中附加上参数,我们在这里加入条件断点,在断点上点右键即可添加条件,这里的条件是o="jiakao://api/open/question/view.htm"时下断,

取消之前的XHR断点,刷新页面,断下后单步步入

此时,URL还是未凭借参数的,我们单步执行

执行到函数尾部,发现URL已经携带了参数,说明实在这段函数中添加了参数,怀疑是其中的C函数,给C函数下断,
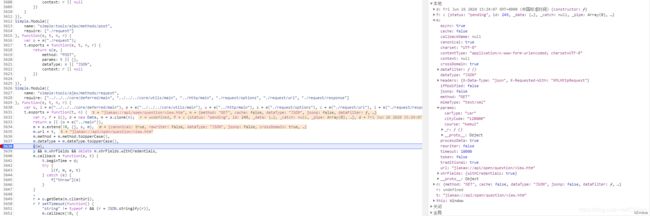
执行C函数前,URL依然是不带参数的,我们单步步进到C函数内

可以看出,这里是在处理URL,那很可能参数就是在这里拼接的,注意我标了断点的这一行有函数o.param这个极有可能是拼接函数,我们持续步入看看,步入的过程中,我们注意到有如下函数段,_r看起来这里就是数值生成的地方了,继续步入

来到了上方函数

这段也就是_r生成的函数段了,阅读该段函数可知(配合调试观察)
o = Math.abs(parseInt((new Date).getTime() * Math.random() * 10000)).toString()
_r = "1" + "o" + (o各位和 + o长度)
一个参数的生成方式已经有了,一路步过,寻找另一个参数的生成方式
最终我们发现,另一个参数就是随机数

至此,我们已经搞清楚了所有需要的参数,至于questionId=810000这个参数的值看看其它几个API就能看到驾考X典会从某个API一次获取全部的题目ID,之后我们就可用任何喜欢的语言来写爬虫了
总结一下,本篇用到的几个技巧:XHR断点和条件断点
为什么需要使用XHR断点呢?大部分请求都是通过XHR来发送的,我们做爬虫主要也是分析XHR请求的参数,返回值,所以XHR断点是很有价值的,尤其遇到这种JS被压缩为1行,无法定位发包函数的情况下
为什么需要条件断点呢?因为你找到的发包函数除了你先分析的API,其他请求也在使用,我们不希望在其他无关请求调用法宝函数时也被中断,所以使用条件断点
技巧讲完了,我们来讲讲别的知识吧
原理篇
网站是如何运行的
不知道大家有没有玩过土电话,就是拿两个杯子,杯子底部用线连起来,这样一边说另一边就能听到。网络其实也是这样,两台计算机之间用网线连起来,这样就能彼此通信了。但实际上计算机之间想要通信只靠一根网线是不行的,还要遵循复杂的协议。
来看看最基本的OSI模型,这是构建一个网络的基本模型,各层的具体应用,大家可以百度之

在上图中,对应的层之间没有直接通信,而是逻辑上的对应关系,真实情况是,假设左边是发送方右边是接收方,左边从应用层一直向下走到物理层再流向接收方也就是右边的物理层,再从右边的物理层走到最上方的应用层。
对用户而言,除应用层以外的都是透明的,用户不关心也无需关心。
那我们的网页是如何工作的呢?
我们的浏览器(客户端)发出HTTP/HTTPS请求(HTTP是应用层协议),通过物理基础设施(网线,路由)发送到目标服务器,目标服务器收到后进行相应的操作,把结果原路返回给我们,并由浏览器解析渲染出来,最终呈现再我们的显示器上。这样就完成了客户端和服务器之间的一次通信。
当然这是极度简化的,实际上传输过程中会涉及很多协议,例如应用层的HTTP协议,传输层的TCP/UDP协议,网络层的IP协议等等。
我们把上面的结论在简化一下就是:客户端发送请求,服务端处理请求并向客户端返回处理结果。
有些新人朋友可能不理解客户端和服务端有什么区别,实际上两者物理上都是计算机没有区别,但运行的软件不同,功能不同。
举个例子:我们给10086的人工台打电话,我们就是客户端,10086的接话员就是服务端,都是人,只不过一方提出问题,另一方反馈问题的答案
那我们所谓的抓包是什么意思呢?就是通过一些工具将浏览器发出的HTTP请求截获下来,让我们知道客户端到底发了什么信息到服务端
当然,Fiddler只是针对HTTP协议的抓包工具,还有很多其他不使用HTTP协议的,比如网游或者一些桌面应用,当然他们也有对应的工具可以抓包分析,封包式外挂就是这么分析了之后伪造请求包制作的
一些网络相关的小科普
什么是局域网与广域网有什么区别?
其实局域网和广域网是一个相对概念,小规模数量的计算机被称为局域网,大规模的被称为广域网,其实两者并没有本质区别。
什么是公网IP
其实公网IP是不得已出现的,首先IP就是我们在网络世界中的身份证,每个人具有唯一的一个,这样就能在网络上确定谁是谁了。我们现在使用的IP协议是IPv4协议,IPv4使用32位(4字节)地址,因此地址空间中只有4,294,967,296(2^32)个地址,实际因为一些原因,比这个数量还要少。在以前只有电脑需要联网的时候,这个IP地址的数量还能满足一台电脑对应一个IP地址,但随着现在智能设备的普及,需要入网的设备越来越多,IP地址不够用了,因此产生了名为NAT的技术,多个设备公用同一个IP地址,由这一个地址对外交互,这个对外交互的IP地址被称为公网IP。
我们大部分人都是处于多人共用一个IP的情况,所以我们在自己的电脑上部署了服务,外界却无法访问(同一个局域网可访问),而公司往往都是花钱购买了公网IP的,所以他们可以对外提供服务
当然随着IPv6技术的普及,我们将拥有2^138次方个IP地址可供使用,甚至能给每一粒沙子都分配一个IP地址了,人手一个公网IP不是梦
12306为什么会挂掉
这里我们要介绍到一种互联网攻击手段:DDoS即分布式拒绝服务攻击
大家内心可能会有疑惑,难道我买个票还造成了网络攻击吗?
这里我们先来说说DDoS到底是什么
首先服务器也是一台计算机,一台计算机的计算力是有限的(CPU负载,内存负载等)我们每一个请求发送给服务器,服务器都要花费算力去处理,之后返回结果
那我们如果同时很多人访问这个服务器,服务器的算力不够用了(带宽不够也有可能),那服务器就无法提供服务了,这就是DDoS攻击
也就是说大量的流量造成服务器无法提供服务,这就是DDoS攻击
对抗DDoS有几种方式,比如:提高服务器性能,增大带宽或者像上文出现的驾考X典一样,对每一个请求做验证,不符合的直接拒绝处理,用最小的算力来处理不合法的请求。
那这和12306崩溃有什么关系呢?
大家想想每年过年的时候那么多人同时抢票,服务器承受不住了,那自然而然就无法提供服务了
那我们犯罪了吗?当然没有,我们是正常请求服务器,DDoS特指恶意请求,目的就是使目标服务器瘫痪。这里只是想说明,12306在春节期间的瘫痪其实是受到了庞大流量的冲击(其实最主要的流量来自抢票软件,机器发请求可比人快多了,这也是近年为什么有程序员因为制作爬虫软件入狱了,不是说你爬取数据本身犯法,毕竟爬虫只是帮忙把本就公开的数据自动收集起来了,搜索引擎就是最大的爬虫,那为什么还会被抓呢,是因为爬取请求过高,毕竟还有分布式爬虫呢,导致对方服务器瘫痪了,或者使用抓取的数据从事商业活动,非法盈利的这就是犯罪行为了)
那大家又会问了,12306就不能加验证吗?当然可以了,不过你也看到了,类似请求参数认证,这种都是可以被分析出来的。那比较靠谱的方法是什么呢?验证码的方式,图像识别可比分析请求参数难多了,这也是有些网站访问多了会要求你填写验证码的原因。不过这也促生了打码平台的诞生…
近年随着云服务和分布式服务的发展,可以在流量高峰期使用额外的云服务器进行动态扩容,提高服务器的吞吐量,这也不失为一种解决方案
因此DDoS其实是无法防止的,只能是对抗,看进攻方和防守方谁掌握的算力更强
本篇也快一万字了,就先这么多吧,之后想到什么在更