AlphaGo是如何炼成的:解读论文 "Mastering the game of Go with deep neural networks and tree search"
这篇发表在nature 2016年1月27日上的文章题目为:"Mastering the game of Go with deep neural networks and tree search"来自Google deep mind,它阐述了AlphaGo的模型过程和训练方法,让我们对这篇论文进行解读,看看为何AlphaGo可以成为迄今最强大的围棋对弈程序吧。
论文地址为:Mastering the game of Go with deep neural networks and tree search - nature
在进行棋牌游戏的时候,最理想的玩法是先得知棋盘上所有状态的完美状态值函数 v ∗ ( s ) v^* (s) v∗(s),然后根据收益最大的状态来进行游戏。但是问题在于有时候棋盘的所有状态规模非常大,在围棋游戏中,这种方法的复杂度是 25 0 150 250^{150} 250150,这显然是做不到的,但是可以通过两种方式来减少搜索空间,一个是通过位置评估的方式,使用近似的值函数来代替完美状态值函数,以此来减少搜索树的深度。另一种方式是通过一个策略来对可能性更大的动作进行采样,这样可以减少搜索树的宽度。本文以这两种策略为基础,结合目前在视觉等领域已经取得突出成果的深度卷积神经网络和强化学习技术,设计了史上最强大的围棋AI程序。
本文的AlphaGo一共有三个阶段。它的大体流程是这样的:首先训练一个有监督学习的策略网络 p σ p_σ pσ ,其样本来自人类棋手的围棋历史数据,AlphaGo将会在这个阶段进行快速高效的学习,得到一个初步的策略网络。接着应用强化学习对程序自己对弈的游戏收益进行优化,得到一个优化的策略网络 p ρ p_ρ pρ,最后根据 p ρ p_ρ pρ自己对弈的游戏结果,训练一个可以预测对弈胜者的值网络 v θ v_θ vθ。其流程结构如图1所示。
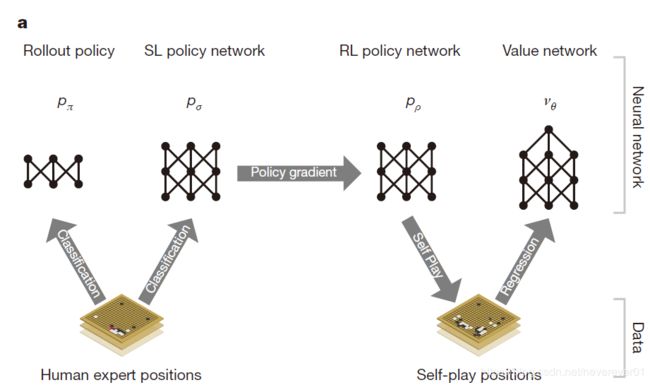
A. 使用有监督学习的策略网络
根据前人工作中的方法,AlphaGo首先使用有监督学习神经网络得到一个快速的策略网络。学习器的输入是棋盘的状态,来自大量的人类玩家的对弈动作历史数据,然后它将随机从动作状态空间的状态-值对 ( s , a ) (s,a) (s,a)中选取一个动作 a a a,然后神经网络通过随机梯度下降的算法最大化在状态 s s s下与人类玩家动作的相似度。换句话说,这个学习的目的就是使得AlphaGo的对弈动作拟合人类对弈的动作。神经网络学习的结果如下表所示。
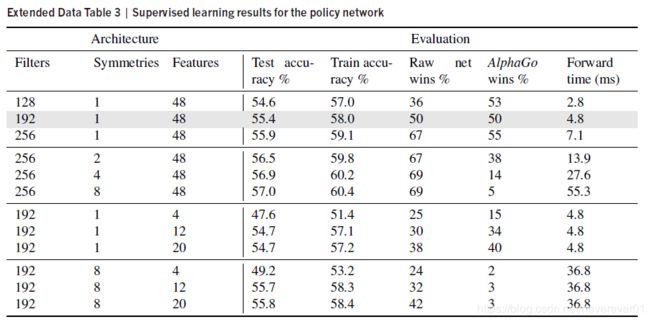
从表中可以看出通过初步的有监督学习,AlphaGo已经获得了与人类玩家平起平坐的实力。
B. 使用强化学习的策略网络
这个阶段的学习的目的是通过策略梯度强化学习来提升上一个阶段得到的策略网络。在这个阶段使用的强化学习策略网络跟上一个阶段的有监督学习策略网络结构一致。并且它的网络权重也初始化为有监督学习网络的权重值。具体训练过程是这样的,将当前的策略网络与随机选取的以前迭代的策略网络进行对弈,在这里奖励函数在除了终止步骤之前的每步都是0,比赛结果每赢一次奖励就+1,输掉则-1,使用 z t z_t zt表示。该网络的权重更新如下面的公式所表示:
Δ ρ ∝ ∂ l o g p ρ ( a t ∣ s t ) ∂ ρ z t \Delta \rho \propto \frac{\partial log p_{\rho}(a_t|s_t)}{\partial \rho}z_t Δρ∝∂ρ∂logpρ(at∣st)zt
使用强化学习的网络进行对弈时,从它的动作概率分布输出中采样得到下一步的动作。从对弈结果来看,使用强化学习的AlphaGo的胜率比使用监督学习的高了 80 % 80\% 80%,并且也远胜另外两种围棋算法。
C. 使用强化学习的值网络
之前说到使用值网络来预测对弈的胜者,也就是位置评估,在这里AlphaGo使用强化学习来训练一个能够预测在一个比赛状态 s s s中使用策略 p p p的双方玩家的回报。值函数的表达式如下所示:
v p ( s ) = E [ z t ∣ s t = s , a t … T ∼ p ] v^p(s)=\mathbb{E}[z_t|s_t=s,a_{t\dots T}\sim p] vp(s)=E[zt∣st=s,at…T∼p]
表示的是在状态 s s s的时候使用策略p所得到的回报,也就是最终的比赛结果的期望。最好的情况是能够得知一个完美的玩家在状态 s s s的值函数,也就是开头提到的完美值函数 v ∗ ( s ) v^* (s) v∗(s),但是这是很难做到的,因此AlphaGo使用值网络去近似值函数,这个值网络用 v θ ( s ) v_θ (s) vθ(s)表示,其中θ是值网络的权重。其更新公式如下:
Δ θ ∝ ∂ v θ ( s ) ∂ θ ( z − v θ ( s ) ) \Delta \theta \propto\frac{\partial v_\theta(s)}{\partial \theta}(z-v_{\theta}(s)) Δθ∝∂θ∂vθ(s)(z−vθ(s))
训练的方法是将状态-回报对 ( s , z ) (s,z) (s,z)进行回归,使用随机梯度下降来最小化预测值与相应的回报z的均方误差。
D. 使用策略网络与值网络进行搜索
AlphaGo使用蒙特卡罗树搜索的方式将策略网络与值网络进行结合。其流程示意如图2所示。

a t = arg max x ( Q ( s t , a ) + u ( s t , a ) ) a_t = \argmax_x(Q(s_t,a)+u(s_t,a)) at=xargmax(Q(st,a)+u(st,a))
其中,额外奖励与子节点中保存的先验概率以及模拟次数有关,公式如下:
u ( s , a ) = ∝ p ( s , a ) 1 + N ( s , a ) u(s,a)=\propto\frac{p(s,a)}{1+N(s,a)} u(s,a)=∝1+N(s,a)p(s,a)
接着通过策略网络对扩展的子节点进行处理,计算出子节点操作的先验概率。在这一步模拟结束的时候,AlphaGo会通过两种方式对子节点进行评估:一种是使用值网络进行评估,另一种是使用一个快速rollout策略将游戏从这一步进行到结束,然后计算回报r。最后依据所有子节点的回报r和值网络的均值对Q进行更新。
N ( s , a ) = ∑ i = 1 n 1 ( s , a , i ) Q ( s , a ) = 1 N ( s , a ) ∑ i = 1 n 1 ( s , a , i ) V ( s L i ) \begin{aligned} N(s,a)&=\sum_{i=1}^n1(s,a,i) \\ Q(s,a)&=\frac{1}{N(s,a)}\sum_{i=1}^n1(s,a,i)V(s_L^i) \end{aligned} N(s,a)Q(s,a)=i=1∑n1(s,a,i)=N(s,a)1i=1∑n1(s,a,i)V(sLi)
值得一提的是,在AlphaGo中监督学习的策略网络表现要比强化学习的策略网络要好,或许是因为人类在对弈的过程中会选择更多可能的下法(监督学习正是模拟人类的下棋行为),然而强化学习的策略只会选择最优的一种下法。但是呢,强化学习的策略网络也不是完全没用,通过它导出的值网络表现要比通过监督学习导出的值网络要好。AlphaGo将蒙特卡罗树搜索与深度学习结合了起来,通过异步多线程的方法在CPU上运行模拟,然后在GPU上并行地计算策略网络和值网络。
E. AlphaGo在比赛中的表现
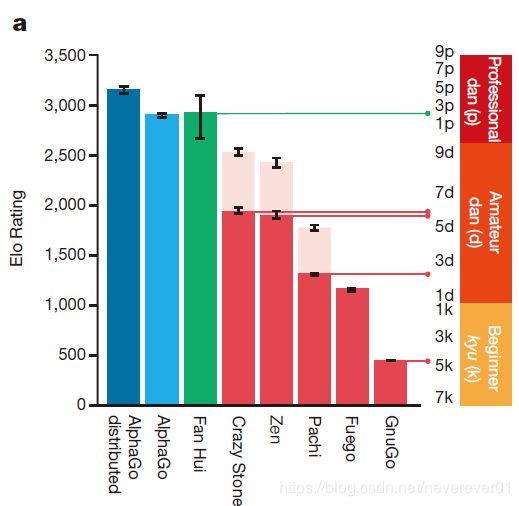
图3展示了AlphaGo在与现在最高水平的围棋程序和人类棋手对弈的能力排名,这些围棋程序都是基于高性能的蒙特卡罗树搜索算法的。可以看出AlphaGo的能力远在其他对手之上。
下图展示了AlphaGo在与人类棋手樊麾下棋的其中一个过程。
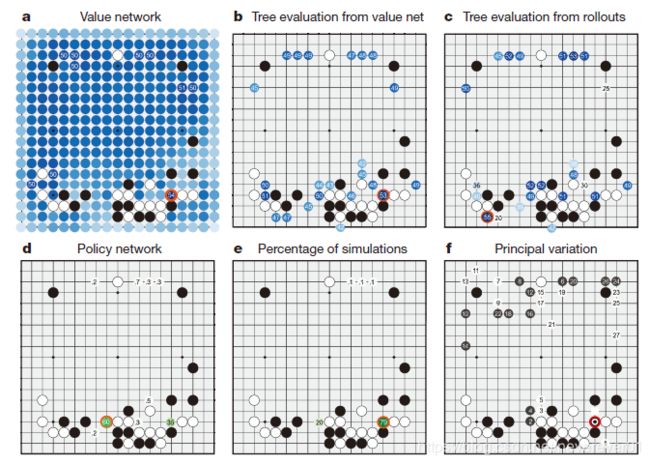
首先AlphaGo会对以该状态s为根节点的树的所有后续节点进行评估,用值网络 v θ ( s ) v_θ (s) vθ(s)估计每个子节点的获胜概率。图4b展示的是以当前状态s为根节点的搜索树各个边的动作值 Q ( s , a ) Q(s,a) Q(s,a),而图4c展示的是以当前状态s为根节点的搜索树各个边的rollout评估值。然后通过监督学习的策略网络预测下一步动作,以概率分布来表示。
F. 总结与感想
可以看到,AlphaGo综合使用了监督学习、强化学习和蒙特卡罗树搜索等多种算法,通过复杂的训练过程才获得了它足以傲视群雄的实力,相比于之前基于蒙特卡罗搜索树的其他围棋程序,AlphaGo多了强化学习导出值网络的过程,这也使他比之前的程序高出一筹。文中提到,由监督学习得到的策略网络的表现甚至要比强化学习得到的策略网络更好,这一点有点超出我的意料,因为强化学习的策略网络从一开始是与监督学习的策略网络一致的,在多轮强化学习之后,其性能居然没有监督学习的效果好,这是否说明在某种特定任务中强化学习会使学习到的东西更加片面,还是说这是强化学习的一个过拟合现象呢?