使用图像增强来训练小数据集(完成狗猫数据集的两阶段分类实验,原始数据直接训练和数据增强后训练)
使用图像增强来训练小数据集目录
- 一、查看运行的环境
- 二、 数据集准备
- 三、资料预处理
- 四、网络模型
- 五、训练
- 六、使用数据填充
@ 什么是 overfitting(过拟合) 及 数据增强?
overfitting( 过 \color{#FFDDAA}{过} 过 拟 \color{#FFC8B4}{拟} 拟 合 \color{#FFCCCC}{合} 合): 过拟合(over-fitting)也称为过学习,它的直观表现是算法在训练集上表现好,但在测试集上表现不好,泛化性能差。过拟合是在模型参数拟合过程中由于训练数据包含抽样误差,在训练时复杂的模型将抽样误差也进行了拟合导致的。
所谓 抽样误差 ,是指抽样得到的样本集和整体数据集之间的偏差。
| 直观来看,引起过拟合的可能原因有以下几点 |
- 模型本身过于复杂,以至于拟合了训练样本集中的噪声。此时需要选用更简单的模型,或者对模型进行裁剪。
- 训练样本太少或者缺乏代表性。此时需要增加样本数,或者增加样本的多样性。
- 训练样本噪声的干扰,导致模型拟合了这些噪声,这时需要剔除噪声数据或者改用对噪声不敏感的模型。
数据增强: data augmentation,它的意思是让有限的数据通过某种变换操作产生更多的等价数据的过程。数据增强主要用来防止过拟合,用于dataset较小的时候。
数据增强可以分为,有监督的数据增强 和无监督的数据增强 方法
有监督的数据增强分为 单样本数据增强 和多样本数据增强 方法;
无监督的数据增强分为 生成新的数据 和学习增强策略 两个方向。
| 数据增强类型 | 初略解释 |
| 单样本数据增强 | 所谓单样本数据增强,即增强一个样本的时候,全部围绕着该样本本身进行操作,包括几何变换类(包括翻转,旋转,裁剪,变形,缩放...),颜色变换类(包括噪声、模糊、颜色变换、擦除、填充...)等 |
| 多样本数据增强 | 不同于单样本数据增强,多样本数据增强方法利用多个样本来产生新的样本,包括SMOTE、 SamplePairing、mixup等 |
| 生成新的数据 | 通过模型学习数据的分布,随机生成与训练数据集分布一致的图片,代表方法GAN |
学习增强策略 |
通过模型,学习出适合当前任务的数据增强方法,代表方法AutoAugment |
解决计算机视觉运算应用到小数据集问题的策略
- 从头开始训练一个小型模型
- 使用预先训练的模型进行特征提取
- 微调预先训练的模型
一、查看运行的环境
| (这里Tensorflow和 Keras的版本要对应,否则要出错!) |
| Platform | Windows-7-6.1.7601-SP1 |
|---|---|
| Tensorflow version | 1.2.1 |
| Keras version | 2.1.2 |
import platform
import tensorflow
import keras
print("Platform: {}".format(platform.platform()))
print("Tensorflow version: {}".format(tensorflow.__version__))
print("Keras version: {}".format(keras.__version__))
二、 数据集准备
下载图像数据集train.zip,在同一目录下(Home)新建子目录"data",把下载的图像数据集train.zip复制到"data"目录并解压缩。具体如图所示

import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import numpy as np
from IPython.display import Image
import os
根目录路径
root_dir = os.getcwd()
存放图像数据集的目录
data_path = os.path.join(root_dir,'data')
import os,shutil
原始数据集的路径
original_dataset_dir = os.path.join(data_path,'train')
存储小数据集的目标
base_dir = os.path.join(data_path,'cats_and_dogs_small')
if not os.path.exists(base_dir):
os.mkdir(base_dir)
训练图像的目录
train_dir = os.path.join(base_dir,'train')
if not os.path.exists(train_dir):
os.mkdir(train_dir)
验证图像的目录
validation_dir = os.path.join(base_dir,'validation')
if not os.path.exists(validation_dir):
os.mkdir(validation_dir)
测试资料的目录
test_dir = os.path.join(base_dir,'test')
if not os.path.exists(test_dir):
os.mkdir(test_dir)
猫的图片的训练资料的目录
train_cats_dir = os.path.join(train_dir,'cats')
ifnot os.path.exists(train_cats_dir):
os.mkdir(train_cats_dir)
狗的图片的训练资料的目录
train_dogs_dir = os.path.join(train_dir,'dogs')
if not os.path.exists(train_dogs_dir):
os.mkdir(train_dogs_dir)
猫的图片的验证集目录
validation_cats_dir = os.path.join(validation_dir,'cats')
if not os.path.exists(validation_cats_dir):
os.mkdir(validation_cats_dir)
狗的图片的验证集目录
validation_dogs_dir = os.path.join(validation_dir,'dogs')
if not os.path.exists(validation_dogs_dir):
os.mkdir(validation_dogs_dir)
猫的图片的测试数据集目录
test_cats_dir = os.path.join(test_dir,'cats')
if not os.path.exists(test_cats_dir):
os.mkdir(test_cats_dir)
狗的图片的测试数据集目录
test_dogs_dir = os.path.join(test_dir,'dogs')
if not os.path.exists(test_dogs_dir):
os.mkdir(test_dogs_dir)
复制前600个猫的图片到train_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(600)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(train_cats_dir,fname)
if not os.path.exists(dst):
shutil.copyfile(src,dst)
print("Copy next 600 cat images to train_cats_dir complete!")
Copy next 600 cat images to train_cats_dir complete!
复制后面400个猫的图片到validation_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1000,1400)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(validation_cats_dir,fname)
if not os.path.exists(dst):
shutil.copyfile(src,dst)
print('Copy next 400 cat images to validation_cats_dir complete!')
Copy next 400 cat images to validation_cats_dir complete!
复制400张猫的图片到test_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(1500,1900)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(test_cats_dir,fname)
if not os.path.exists(dst):
shutil.copyfile(src,dst)
print("Copy next 400 cat images to test_cats_dir complete!")
Copy next 400 cat images to test_cats_dir complete!
复制前600张狗的图片到train_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(600)]
for fname in fnames:
src = os.path.join(original_dataset_dir,fname)
dst = os.path.join(train_dogs_dir,fname)
if not os.path.exists(dst):
shutil.copyfile(src,dst)
print("Copy first 600 dog images to train_dogs_dir complete!")
Copy first 600 dog images to train_dogs_dir complete!
复制后面400个狗的图片到validation_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1000, 1400)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
if not os.path.exists(dst):
shutil.copyfile(src, dst)
print('Copy next 400 dog images to validation_dogs_dir complete!')
Copy next 400 dog images to validation_dogs_dir complete!
复制400张狗的图片到test_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(1500, 1900)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
if not os.path.exists(dst):
shutil.copyfile(src, dst)
print('Copy next 400 dog images to test_dogs_dir complete!')
Copy next 400 dog images to test_dogs_dir complete!
进行一次检查,计算每个分组中有多少张照片(训练/验证/测试)
print('total training cat images:', len(os.listdir(train_cats_dir)))
print('total training dog images:', len(os.listdir(train_dogs_dir)))
print('total validation cat images:', len(os.listdir(validation_cats_dir)))
print('total validation dog images:', len(os.listdir(validation_dogs_dir)))
print('total test cat images:', len(os.listdir(test_cats_dir)))
print('total test dog images:', len(os.listdir(test_dogs_dir)))
total training cat images: 600
total training dog images: 600
total validation cat images: 400
total validation dog images: 400
total test cat images: 400
total test dog images: 400
有1200个训练图像,然后是800个验证图像,800个测试图像,其中每个分类都有相同数量的样本,是一个平衡的二元分类问题,意味着分类准确度将是合适的度量标准。
三、资料预处理
网络的预处理步骤:
- 读入图像
- 将JPEG内容解码为RGB网格的像素
- 将其转换为浮点张量
- 将像素值(0和255之间)重新缩放到[0,1]间隔
数据应该先被格式化成适当的预处理浮点张量,然后才能输入到神经网络中。
from keras.preprocessing.image import ImageDataGenerator
# 所有的图像将重新进行归一化处理 Rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
# 直接从目录读取图像数据
train_generator = train_datagen.flow_from_directory(
# 训练图像的目录
train_dir,
# 所有图像大小会被转换成150x150
target_size=(150,150),
# 每次产生20个图像的批次
batch_size = 20,
# 由于这是一个二元分类问题,y的label值也会被转换成二元的标签
class_mode = 'binary')
# 直接从目录读取图像数据
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150,150),
batch_size = 20,
class_mode='binary')
Found 1200 images belonging to 2 classes.
Found 800 images belonging to 2 classes.
图像张量生成器(generator)的输出,它产生150x150 RGB图像(形状"(20,150,150,3)")和二进制标签(形状"(20,)")的批次张量。20是每个批次中的样品数(批次大小)
for data_batch,labels_batch in train_generator:
print('data batch shape:',data_batch.shape)
print('labels batch shape:',labels_batch.shape)
break
data batch shape: (20, 150, 150, 3)
labels batch shape: (20,)
四、网络模型
卷积网络(convnets)将是一组交替的Conv2D(具有relu激活)和MaxPooling2D层。从大小150x150(有点任意选择)的输入开始,我们最终得到了尺寸为7x7的Flatten层之前的特征图。
注意特征图的深度在网络中逐渐增加(从32到128),而特征图的大小正在减少(从148x148到7x7)。这是一个你将在几乎所有的卷积网络(convnets)结构中会看到的模式。
由于我们正在处理二元分类问题,所以我们用一个神经元(一个大小为1的密集层(Dense))和一个sigmoid激活函数来结束网络。该神经元将会被用来查看图像归属于那一类或另一类的概率。
from keras import layers
from keras import models
from keras.utils import plot_model
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation='relu',input_shape=(150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dense(512,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
看特征图的尺寸如何随着每个连续的图层而改变,打印网络结构
model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 6272) 0
_________________________________________________________________
dense_5 (Dense) (None, 512) 3211776
_________________________________________________________________
dense_6 (Dense) (None, 1) 513
=================================================================
Total params: 3,453,121
Trainabl params: 3,453,121
Non-trainable params: 0
_________________________________________________________________
在编译步骤里,使用RMSprop优化器。由于用一个单一的神经元(Sigmoid的激活函数)结束了网络,将使用二进制交叉熵(binary crossentropy)作为损失函数。
from keras import optimizers
model.compile(loss='binary_crossentropy',optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
五、训练
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
Epoch 1/30
100/100 [==============================] - 199s 2s/step - loss: 0.6854 - acc: 0.5455 - val_loss: 0.6889 - val_acc: 0.5050
Epoch 2/30
100/100 [==============================] - 197s 2s/step - loss: 0.6512 - acc: 0.6280 - val_loss: 0.6540 - val_acc: 0.6210
Epoch 3/30
100/100 [==============================] - 193s 2s/step - loss: 0.5878 - acc: 0.6890 - val_loss: 0.6632 - val_acc: 0.6040
Epoch 4/30
100/100 [==============================] - 193s 2s/step - loss: 0.5357 - acc: 0.7235 - val_loss: 0.6050 - val_acc: 0.6750
Epoch 5/30
100/100 [==============================] - 193s 2s/step - loss: 0.4880 - acc: 0.7625 - val_loss: 0.6080 - val_acc: 0.6860
Epoch 6/30
100/100 [==============================] - 198s 2s/step - loss: 0.4441 - acc: 0.7980 - val_loss: 0.6200 - val_acc: 0.6800
Epoch 7/30
100/100 [==============================] - 204s 2s/step - loss: 0.3964 - acc: 0.8155 - val_loss: 0.6721 - val_acc: 0.6650
Epoch 8/30
100/100 [==============================] - 200s 2s/step - loss: 0.3592 - acc: 0.8415 - val_loss: 0.6579 - val_acc: 0.6740
Epoch 9/30
100/100 [==============================] - 198s 2s/step - loss: 0.3179 - acc: 0.8660 - val_loss: 0.6550 - val_acc: 0.6940
Epoch 10/30
100/100 [==============================] - 208s 2s/step - loss: 0.2785 - acc: 0.8865 - val_loss: 0.6938 - val_acc: 0.6920
Epoch 11/30
100/100 [==============================] - 214s 2s/step - loss: 0.2472 - acc: 0.9040 - val_loss: 0.7478 - val_acc: 0.6890
Epoch 12/30
100/100 [==============================] - 215s 2s/step - loss: 0.2189 - acc: 0.9160 - val_loss: 0.7710 - val_acc: 0.7030
Epoch 13/30
100/100 [==============================] - 206s 2s/step - loss: 0.1859 - acc: 0.9290 - val_loss: 0.7461 - val_acc: 0.7120
Epoch 14/30
100/100 [==============================] - 199s 2s/step - loss: 0.1484 - acc: 0.9495 - val_loss: 0.8131 - val_acc: 0.6930
Epoch 15/30
100/100 [==============================] - 208s 2s/step - loss: 0.1313 - acc: 0.9585 - val_loss: 1.0099 - val_acc: 0.6970
Epoch 16/30
100/100 [==============================] - 213s 2s/step - loss: 0.1059 - acc: 0.9675 - val_loss: 0.9962 - val_acc: 0.6960
Epoch 17/30
100/100 [==============================] - 209s 2s/step - loss: 0.0831 - acc: 0.9715 - val_loss: 1.1409 - val_acc: 0.6780
Epoch 18/30
100/100 [==============================] - 202s 2s/step - loss: 0.0769 - acc: 0.9770 - val_loss: 1.1242 - val_acc: 0.7020
Epoch 19/30
100/100 [==============================] - 209s 2s/step - loss: 0.0583 - acc: 0.9810 - val_loss: 1.2149 - val_acc: 0.7000
Epoch 20/30
100/100 [==============================] - 197s 2s/step - loss: 0.0478 - acc: 0.9875 - val_loss: 1.2307 - val_acc: 0.7060
Epoch 21/30
100/100 [==============================] - 198s 2s/step - loss: 0.0417 - acc: 0.9895 - val_loss: 1.3518 - val_acc: 0.6810
Epoch 22/30
100/100 [==============================] - 196s 2s/step - loss: 0.0397 - acc: 0.9875 - val_loss: 1.3366 - val_acc: 0.7160
Epoch 23/30
100/100 [==============================] - 203s 2s/step - loss: 0.0282 - acc: 0.9930 - val_loss: 1.3750 - val_acc: 0.6870
Epoch 24/30
100/100 [==============================] - 199s 2s/step - loss: 0.0203 - acc: 0.9940 - val_loss: 1.4814 - val_acc: 0.7020
Epoch 25/30
100/100 [==============================] - 202s 2s/step - loss: 0.0235 - acc: 0.9920 - val_loss: 1.5932 - val_acc: 0.6940
Epoch 26/30
100/100 [==============================] - 205s 2s/step - loss: 0.0207 - acc: 0.9935 - val_loss: 3.0777 - val_acc: 0.6060
Epoch 27/30
100/100 [==============================] - 213s 2s/step - loss: 0.0253 - acc: 0.9935 - val_loss: 1.7332 - val_acc: 0.6850
Epoch 28/30
100/100 [==============================] - 207s 2s/step - loss: 0.0171 - acc: 0.9940 - val_loss: 1.5884 - val_acc: 0.6910
Epoch 29/30
100/100 [==============================] - 197s 2s/step - loss: 0.0083 - acc: 0.9980 - val_loss: 1.7505 - val_acc: 0.6990
Epoch 30/30
100/100 [==============================] - 197s 2s/step - loss: 0.0178 - acc: 0.9930 - val_loss: 1.6967 - val_acc: 0.6940
训练完成后把模型保存下来
model.save('cats_and_dogs_small_2.h5')
使用图表来秀出在训练过程中模型对训练和验证数据的损失(loss)和准确性(accuracy)数据
import matplotlib.pyplot as plt
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs,acc,label='Training acc')
plt.plot(epochs,val_acc,label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs,loss,label='Training loss')
plt.plot(epochs,val_loss,label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()

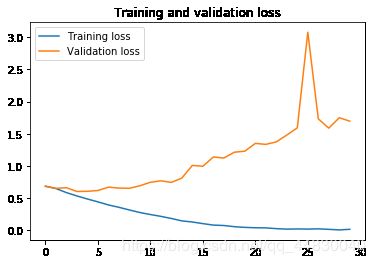
上面图标显示了过度拟合(overfitting)的特征。我们的训练精确度随着时间线性增长,直到接近100%,然而我们的验证精度却停在70%~72%。我们的验证损失在第五个循环(epochs)之后达到最小值,然后停顿,而训练损失在线性上保持下降直到接近0。
因为我们只有相对较少的训练数据(2000个),过度拟合将成为我们的首要的关注点。你已经知道了许多可以帮助减轻过度拟合的技巧。例如Dropout和权重衰减(L2正则化)。我们现在要引入一个新的,特定于电脑视觉影像,并在使用深度学习模型处理图像时几乎普遍使用的技巧:数据扩充(data augmentation)。
六、使用数据填充
过度拟合是由于样本数量太少而导致的,导致我们无法训练能够推广到新数据的模型。
给定无限数据,我们的模型将暴露在手头数据分布的每个可能的方向:我们永远不会过度。数据增加采用从现有训练样本生成更多训练数据的方法,通过产生可信的图像的多个随机变换来"增加"样本。目标是在训练的时候,我们的模型永远不会再看到完全相同的画面两次。这有助于模型暴学习到数据的更多方面,并更好地推广。
在keras中,可以通过配置对我们的ImageDataGenerator实例读取的图像执行多个随机变换来完成。
datagen = ImageDataGenerator(rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
这些只是列出一些可用的选项(更多选项,可以参考keras文档)。快速看一下这些参数:
- rotation_range是以度(0-180)为单位的值,它是随机旋转图片的范围。
- width_shift和height_shift是范围(占总宽度或高度的一小部分),用于纵向或横向随机转换图片。
- shear_range用于随机剪切变换。
- zoom_range用于随机放大图片内容。
- horizontal_flip用于在没有水平不对称假设(例如真实世界图片)的情况下水平地随机翻转一半图像。
- fill_mode是用于填充新创建的像素的策略,可以在旋转或宽/高移位后显示。
看增强后的图像:
import matplotlib.pyplot as plt
from keras.preprocessing import image
# 取得训练数据集中猫的图片列表
fnames = [os.path.join(train_cats_dir,fname) for fname in os.listdir(train_cats_dir)]
# 取一个图像
img_path = fnames[29]
# 读入图像并进行大小处理
img = image.load_img(img_path,target_size=(150,150))
# 转换成Numpy array 并且shape(150,150,3)
x = image.img_to_array(img)
# 重新Reshape成(1,150,150,3)以便输入到模型中
x = x.reshape((1,) + x.shape)
# 通过flow()方法将会随机产生新的图像
# 它会无线循环,所以我们需要在某个时候“断开”循环
i = 0
for batch in datagen.flow(x,batch_size = 1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()




如果我们使用这种数据增强配置来训练一个新的网络,我们的网络将永远不会看到相同重复的输入。然而,它看到的输入仍然是相互关联的,因为它们来自少量的原始图像 - 我们不能产生新的信息,我们只能重新混合现有的信息。因此,这可能不足以完全摆脱过度拟合(overfitting)。为了进一步克服过度拟合(overfitting),我们还将在密集连接(densely-connected)的分类器之前添加一个Dropout层。
model = models.Sequential()
model.add(layers.Conv2D(32,(3,3),activation='relu',input_shape=(150,150,3)))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(64,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Conv2D(128,(3,3),activation='relu'))
model.add(layers.MaxPooling2D((2,2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5))
model.add(layers.Dense(512,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
使用数据填充(data augmentation)和dropout来训练我们的网络
train_datagen = ImageDataGenerator(rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
# 这是图像资料的目录
train_dir,
# 所有的图像大小会被转换成150x150
target_size=(150,150),
batch_size=32,
# 由于这是一个二元分类问题,y的label值也会被转换成二元的标签
class_mode = 'binary')
validation_generator = test_datagen.flow_from_directory(validation_dir,
target_size=(150,150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(train_generator,
steps_per_epoch=100,
epochs=50,
validation_data=validation_generator,
validation_steps=50)
Found 1200 images belonging to 2 classes.
Found 800 images belonging to 2 classes.
Epoch 1/50
100/100 [==============================] - 314s 3s/step - loss: 0.6923 - acc: 0.5144 - val_loss: 0.6824 - val_acc: 0.5925
Epoch 2/50
100/100 [==============================] - 308s 3s/step - loss: 0.6757 - acc: 0.5847 - val_loss: 0.6538 - val_acc: 0.6050
Epoch 3/50
100/100 [==============================] - 323s 3s/step - loss: 0.6595 - acc: 0.6072 - val_loss: 0.6367 - val_acc: 0.6312
Epoch 4/50
100/100 [==============================] - 310s 3s/step - loss: 0.6513 - acc: 0.6178 - val_loss: 0.6296 - val_acc: 0.6375
Epoch 5/50
100/100 [==============================] - 305s 3s/step - loss: 0.6292 - acc: 0.6384 - val_loss: 0.6251 - val_acc: 0.6412
Epoch 6/50
100/100 [==============================] - 323s 3s/step - loss: 0.6186 - acc: 0.6409 - val_loss: 0.5853 - val_acc: 0.6850
Epoch 7/50
100/100 [==============================] - 326s 3s/step - loss: 0.5994 - acc: 0.6653 - val_loss: 0.6025 - val_acc: 0.6675
Epoch 8/50
100/100 [==============================] - 330s 3s/step - loss: 0.5914 - acc: 0.6719 - val_loss: 0.5797 - val_acc: 0.6787
Epoch 9/50
100/100 [==============================] - 311s 3s/step - loss: 0.5738 - acc: 0.6956 - val_loss: 0.5685 - val_acc: 0.6825
Epoch 10/50
100/100 [==============================] - 316s 3s/step - loss: 0.5791 - acc: 0.6881 - val_loss: 0.5778 - val_acc: 0.6837
Epoch 11/50
100/100 [==============================] - 313s 3s/step - loss: 0.5674 - acc: 0.6991 - val_loss: 0.5428 - val_acc: 0.7350
Epoch 12/50
100/100 [==============================] - 318s 3s/step - loss: 0.5584 - acc: 0.7075 - val_loss: 0.5377 - val_acc: 0.7300
Epoch 13/50
100/100 [==============================] - 320s 3s/step - loss: 0.5501 - acc: 0.7144 - val_loss: 0.5348 - val_acc: 0.7050
Epoch 14/50
100/100 [==============================] - 310s 3s/step - loss: 0.5424 - acc: 0.7194 - val_loss: 0.5290 - val_acc: 0.7188
Epoch 15/50
100/100 [==============================] - 309s 3s/step - loss: 0.5357 - acc: 0.7269 - val_loss: 0.5169 - val_acc: 0.7250
Epoch 16/50
100/100 [==============================] - 311s 3s/step - loss: 0.5364 - acc: 0.7309 - val_loss: 0.5184 - val_acc: 0.7450
Epoch 17/50
100/100 [==============================] - 305s 3s/step - loss: 0.5291 - acc: 0.7331 - val_loss: 0.5098 - val_acc: 0.7375
Epoch 18/50
100/100 [==============================] - 314s 3s/step - loss: 0.5249 - acc: 0.7322 - val_loss: 0.5514 - val_acc: 0.7087
Epoch 19/50
100/100 [==============================] - 313s 3s/step - loss: 0.5151 - acc: 0.7356 - val_loss: 0.5113 - val_acc: 0.7500
Epoch 20/50
100/100 [==============================] - 318s 3s/step - loss: 0.5173 - acc: 0.7466 - val_loss: 0.5023 - val_acc: 0.7475
Epoch 21/50
100/100 [==============================] - 310s 3s/step - loss: 0.5124 - acc: 0.7419 - val_loss: 0.4960 - val_acc: 0.7412
Epoch 22/50
100/100 [==============================] - 306s 3s/step - loss: 0.5062 - acc: 0.7481 - val_loss: 0.5011 - val_acc: 0.7475
Epoch 23/50
100/100 [==============================] - 306s 3s/step - loss: 0.5036 - acc: 0.7522 - val_loss: 0.5758 - val_acc: 0.7013
Epoch 24/50
100/100 [==============================] - 309s 3s/step - loss: 0.5075 - acc: 0.7428 - val_loss: 0.5008 - val_acc: 0.7575
Epoch 25/50
100/100 [==============================] - 306s 3s/step - loss: 0.4856 - acc: 0.7703 - val_loss: 0.5587 - val_acc: 0.7188
Epoch 26/50
100/100 [==============================] - 306s 3s/step - loss: 0.5064 - acc: 0.7431 - val_loss: 0.5091 - val_acc: 0.7350
Epoch 27/50
100/100 [==============================] - 304s 3s/step - loss: 0.4979 - acc: 0.7528 - val_loss: 0.4903 - val_acc: 0.7538
Epoch 28/50
100/100 [==============================] - 315s 3s/step - loss: 0.4837 - acc: 0.7684 - val_loss: 0.4861 - val_acc: 0.7575
Epoch 29/50
100/100 [==============================] - 307s 3s/step - loss: 0.4809 - acc: 0.7675 - val_loss: 0.5019 - val_acc: 0.7438
Epoch 30/50
100/100 [==============================] - 313s 3s/step - loss: 0.4730 - acc: 0.7675 - val_loss: 0.4818 - val_acc: 0.7650
Epoch 31/50
100/100 [==============================] - 311s 3s/step - loss: 0.4684 - acc: 0.7722 - val_loss: 0.4748 - val_acc: 0.7750
Epoch 32/50
100/100 [==============================] - 304s 3s/step - loss: 0.4729 - acc: 0.7706 - val_loss: 0.4859 - val_acc: 0.7562
Epoch 33/50
100/100 [==============================] - 304s 3s/step - loss: 0.4720 - acc: 0.7690 - val_loss: 0.4828 - val_acc: 0.7588
Epoch 34/50
100/100 [==============================] - 305s 3s/step - loss: 0.4576 - acc: 0.7791 - val_loss: 0.4704 - val_acc: 0.7638
Epoch 35/50
100/100 [==============================] - 307s 3s/step - loss: 0.4622 - acc: 0.7772 - val_loss: 0.5016 - val_acc: 0.7488
Epoch 36/50
100/100 [==============================] - 308s 3s/step - loss: 0.4478 - acc: 0.7912 - val_loss: 0.4732 - val_acc: 0.7662
Epoch 37/50
100/100 [==============================] - 312s 3s/step - loss: 0.4517 - acc: 0.7847 - val_loss: 0.4694 - val_acc: 0.7800
Epoch 38/50
100/100 [==============================] - 309s 3s/step - loss: 0.4617 - acc: 0.7903 - val_loss: 0.4896 - val_acc: 0.7600
Epoch 39/50
100/100 [==============================] - 322s 3s/step - loss: 0.4453 - acc: 0.7869 - val_loss: 0.5066 - val_acc: 0.7425
Epoch 40/50
100/100 [==============================] - 314s 3s/step - loss: 0.4376 - acc: 0.7931 - val_loss: 0.4877 - val_acc: 0.7650
Epoch 41/50
100/100 [==============================] - 312s 3s/step - loss: 0.4461 - acc: 0.7894 - val_loss: 0.4752 - val_acc: 0.7512
Epoch 42/50
100/100 [==============================] - 327s 3s/step - loss: 0.4432 - acc: 0.7856 - val_loss: 0.4652 - val_acc: 0.7825
Epoch 43/50
100/100 [==============================] - 310s 3s/step - loss: 0.4267 - acc: 0.8066 - val_loss: 0.4942 - val_acc: 0.7612
Epoch 44/50
100/100 [==============================] - 310s 3s/step - loss: 0.4440 - acc: 0.7925 - val_loss: 0.4828 - val_acc: 0.7575
Epoch 45/50
100/100 [==============================] - 306s 3s/step - loss: 0.4260 - acc: 0.7978 - val_loss: 0.5165 - val_acc: 0.7638
Epoch 46/50
100/100 [==============================] - 306s 3s/step - loss: 0.4272 - acc: 0.8003 - val_loss: 0.4672 - val_acc: 0.7812
Epoch 47/50
100/100 [==============================] - 306s 3s/step - loss: 0.4151 - acc: 0.8056 - val_loss: 0.4658 - val_acc: 0.7775
Epoch 48/50
100/100 [==============================] - 315s 3s/step - loss: 0.4130 - acc: 0.8122 - val_loss: 0.6227 - val_acc: 0.7013
Epoch 49/50
100/100 [==============================] - 317s 3s/step - loss: 0.4318 - acc: 0.8016 - val_loss: 0.4559 - val_acc: 0.7925
Epoch 50/50
100/100 [==============================] - 310s 3s/step - loss: 0.4062 - acc: 0.8144 - val_loss: 0.4602 - val_acc: 0.7812
保存模型,将在convnet可视化里使用它
model.save('cats_and_dogs_small_3.h5')
看一遍结果:
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs,acc,label='Training acc')
plt.plot(epochs,val_acc,label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs,loss, label='Training loss')
plt.plot(epochs,val_loss,label='Validation acc')
plt.title('Training and validation loss')
plt.legend()
plt.show()


由于数据增加(data augmentation)和dropout使用,不再有过度拟合(overfitting)的问题:训练曲线相当密切地跟随着验证曲线。现在能够达到82%的准确度,比非正规的模型相比改善了15%。通过进一步利用正规化技术,及调整网络参数(例如每个卷积层的滤波器数量或网络层数),可以获得更好的准确度,可能高达86~87%。