NLG ≠ 机器写作 | 专家专栏
允中 转自 百炼智能
量子位 出品 | 公众号 QbitAI
编者按:NLG——自然语言生成,是近年AI领域最受关注的前沿方向之一,也是争议和论辩最激烈的领域之一,甚至去年还引发过2位AI大神的隔空激辩。
但对于更多关注者来说,可能首要任务还是在于追本溯源,知道NLG究竟是什么?原理如何?能做及不能做什么?
所以我们推荐这篇不错的专家专栏,原作者是AI创业公司百炼智能——或者说他们就是NLG领域的纵深前行者,核心创始团队源自北大天网实验室,在AI领域从业多年,而且难能可贵的是,本文还是有技术有应用举例的科普佳作。
好了,一起开始学习吧~
引子
2017年5月31日,包括 Aaron Courville(《Deep Learning》一书作者)在内的五位作者,在 arXiv 上提交了一篇论文《Adversarial Generation of Natural Language》,提出了一种新的基于生成对抗网络(Generative Adversarial Networks, GAN)的自然语言生成(Natural Language Generation,NLG)方法,在自动写诗这件事情上取得了非常好的效果,但这并不是重点。
重点是,这篇文章引发了自然语言处理(Natural Language Processing, NLP)大神 Yoav GoldGerg和深度学习(Deep Learning, DL)大神 Yann LeCun 的论战。
Yoav 先是在 Twitter 上发了一篇推文表明自己不喜欢这篇论文的工作,之后又写了一篇Medium长文(图1)表达自己的观点:
“拜托你们这帮搞深度学习的人,别再抓着语言不放并声称自己已经解决语言的问题了!”,认为这篇论文并没有解决自然语言生成(NLG) 的问题。
△ YoavGoldBerg的 Medium 长文截屏(后来Yoav修改了这篇文章)
随后,Yann LeCun 在 Facebook 上对 Yoav 的观点进行了反击(图2),然后又反复数个回合。

△ Yann LeCun 在 Facebook 上的反击
引发这次争论的主题就是自然语言生成(以下简称 NLG),也是接下来系列文章里我们要讨论的主题。
何为 NLG?
提到 NLG,首先会联想到一个不知疲倦的机器人,可以每周7×24小时地奋笔疾书,产出各种各样的小说、情书、剧本、新闻、财报等各种类型的文字。
现实中,的确也有一些机器生成的书出版(例如用165行 Python 代码自动生成的书《World Clock》,由 Harvard Book Store press 出版 ),甚至在 Amazon 上有了一定的销量和用户好评(例如 Philip M. Parker 用机器写了一大堆书在 Amazon 上卖)。
但实际的 NLG,更多的是基于已有文本/数据/图像生成自然语言形式的文本,离真正的「机器写作」差的还很远。
NLG是自然语言处理(NLP)的重要组成部分。NLP研究如何实现自然语言形式的人机交互,其研究涉及语言学、计算机科学和数学等多个领域。
NLP 包含自然语言理解 (Natural Language Understanding,NLU) 和自然语言生成(Natural Langauge Generation, NLG)两个重要方向,如下图所示。

△ 自然语言处理主要技术领域
其中,NLU 旨在让机器理解自然语言形式的文本内容。从 NLU 处理的文本单元来讲,可以分为词(term)、句子(sentence)、文档(document)三种不同的类型:
词层面的基础 NLU 领域包括分词(汉语、缅甸语、泰语等非拉丁语系语言需要)、词性标注(名词、动词、形容词等)、命名实体识别(人物、机构、地点等)和实体关系提取(例如人物-出生地关系、公司-所在地关系、公司收购关系等);
句子层面的基础 NLU 领域包括句法结构解析(获取句子的句法结构)和依存关系解析(获取句子组成部分的依赖关系);
文档层面的基础 NLU 领域包含情感分析(分析一篇文档的情感倾向)和主题建模(分析文档内容的主题分布)。
与NLU不同,NLG旨在让机器根据确定的结构化数据、文本、音视频等生成人类可以理解的自然语言形式的文本。根据数据源的类型,NLG可以分为三类:
Text to text NLG,主要是对输入的自然语言文本进行进一步的处理和加工,主要包含文本摘要(对输入文本进行精简提炼)、拼写检查(自动纠正输入文本的单词拼写错误)、语法纠错(自动纠正输入文本的句法错误)、机器翻译(将输入文本的语义以另一种语言表达)和文本重写(以另一种不同的形式表达输入文本相同的语义)等领域;
Data to text NLG,主要是根据输入的结构化数据生成易读易理解的自然语言文本,包含天气预报(根据天气预报数据生成概括性的用于播报的文本)、金融报告(自动生成季报/年报)、体育新闻(根据比分信息自动生成体育新闻)、人物简历(根据人物结构化数据生成简历)等领域的文本自动生成;
Vision to text NLG,主要是给定一张图片或一段视频,生成可以准确描述图片或视频(其实是连续的图片序列)语义信息的自然语言文本,同时 text to vision 的自动生成近几年也有一些有趣的进展。
近年来,随着CNN(Convolutinal Neural Network)、RNN(Recurrent Neural Network)、GAN(Generative Adversarial Network)等深度学习技术的应用,NLP(尤其是 NLG)领域取得了明显的进展,也涌现了一些有趣的 NLG 应用。
有趣的 NLG 应用
在 Text to text NLG 领域,令人瞩目的进展当属 GNMT (Google Neural Machine Translation)。它基于带 Attention 机制的 Encoder(8层LSTM)- Decoder(8层LSTM) 框架(图4),通过引入残差连接(Residual Connection),并基于 Google 打造的 TPU (Tensor Processing Unit)进行并行化处理,高效地进行 GNMT 模型的训练和预测。
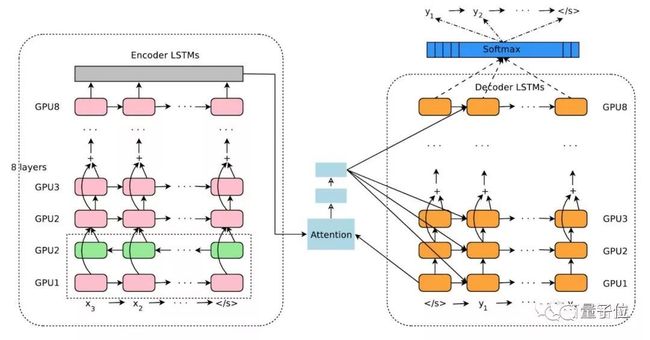
△ GNMT 的 Encoder-Decoder 框架
GNMT 相对传统的 PBMT(Phrase-Based Machine Translation)模型,在多个主要语言对的翻译中将翻译误差降低了 55%-85% 以上。
同时,Google 在 GNMT中借鉴迁移学习(Transfer Learning)的思路,通过不同语言对的翻译模型共享参数,实现了未经训练的语言对之间的自动翻译(即「Zero-Shot Translation」)。
在 Data to text NLG 领域,一项有趣的工作是Facebook AI Research 2016年发表在 EMNLP 会议上的一篇论文研究了如何利用人物的结构化数据(通常是表格化的数据)生成人物 biography 的工作,并通过抽取维基百科的 infobox 和正文第一段话,自动化地构建了一个大型平行语料库 WikiBio,包含了超过70万条平行数据和超过40万的词表。
它基于条件神经语言模型,利用表格数据作为条件,进行自然语言形式的 biography 文本生成(图5)。
它将表格数据以局部条件(local conditioning,描述之前生成的词序列与表格数据的关系)和全局条件(global conditioning,利用表格中所有的域和对应数据对人的特征进行建模)的形式加入到神经网络模型中,并设计了一种 copy 机制使模型可以灵活考虑表格中出现过的词。
基于这样的机制,可以达到类似下面例子的结果。

△ 人物 biography 文本生成示例
Vision to text NLG 领域的典型应用当属 Image Captioning(看图说话),它的输入为一张图片(Video Captioning 中输入为一个图片序列,但技术方案类似),输出是描述该图片语义的自然语言文本。
下图中有一些有趣的例子。

△ 一些有趣的 vision-to-text NLG 例子
同机器翻译的GNMT方案类似,Image Captioning 的技术方案也基于 Encoder-Decoder 框架,只是 Encoder 部分的神经网络从 LSTM 替换成了 CNN,用以准确刻画图片的语义信息。
同 GNMT 类似,引入 Attention 机制来智能选择影响 Decoder 部分生成文字的图像空间特征。具体的模型结构如图7所示。
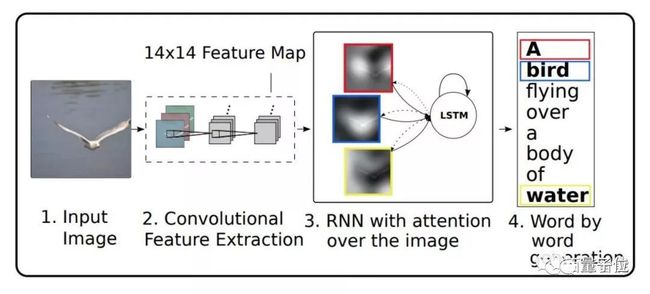
△ Image Captioning 模型结构
NLG 技术的能力边界
NLG 技术,一个核心在于NL,即自然语言形式的文本,更易于普通人阅读;另一个核心在于G,即生成,但不是创作,不涉及深入地分析、提炼和推理。
在 Text to text NLG 中,本质上是将输入文本进行处理,映射到一个语义向量空间中,然后再用输出文本来表达同样的语义,而这一过程中语义信息本身并没有经过进一步加工。
Data to text NLG 的目的是将结构化数据嵌入自然语言文本中,便于普通人的快速阅读,即使有一些看似推理的结果(例如天气预报中根据下周七天的天气数据,输出「未来一周大部分时间晴好,仅周三有短时小雨」这样的文本),其实也是人为定义了新的结构化数据字段。
Vision to text NLG 中也是如此,只是用自然语言文本来表达原先图像表达的语义,也不涉及语义的进一步加工。
换句话说,目前的 NLG 技术并不能实现人类的「写作」过程 - 其中包括对大量输入信息的理解、提炼、分析、推理和重组,而仅能够给出输入信息(文本、数据和图像)的自然语言形式的表示。
NLG 技术生成的文本,单篇文本看起来会非常规范和优质,但把大量的生成文本放在一起,就会感觉出浓浓的机器味儿 - 更为模式化且缺少灵活性。因此,用「机器写作」来作为 NLG 的别称,是有点过于高看其能力了。
即便如此,由于机器可以不知疲倦且客观地工作,NLG 技术在下述场景中有了广泛的应用:
需要利用海量数据生成大量的自然语言文本,且零错误,如企业年报等
需要极高的时效性,全天候检测热点/异常点,并实时生成文本内容,如突发新闻快讯等;
生成客观不带情感的内容,如财经快讯、体育快讯等;
根据受众特点,对相同的输入文本/数据/图像,生成符合受众特点的个性化文本内容,如商品文案等。
预告
这会是一个关于NLG技术的系列文章,读者定位是对NLG技术感兴趣的所有人,所以在写作过程中,会兼顾客观性与趣味性,也会兼顾深度与广度,期望能帮助大家开阔思路。
接下来系列文章的主题会是:
工业界中的 NLG
学术界中的 NLG
NLG 关键技术方案
用 GAN 来 NLG
行业大咖和八卦
敬请期待!
传送门
关于百炼智能,欢迎移步量子位前情报道:
《又一北大系AI公司浮出水面,百炼智能宣布获千万元天使投资》
如果你对该话题感兴趣,也欢迎投稿与我们交流,邮件可发送:[email protected],或添加量子位小助手,加入NLP专业交流群。
— 完 —
活动推荐

华为云•普惠AI,让开发充满AI!
爱上你的代码,爱做 “改变世界”的行动派!
大会将首次发布AI开发框架,从AI模型训练到AI模型部署的全套开发一站式完成!让AI开发触手可及!

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态