介绍
Inception 又叫Googlenet是Google于2014年为参加ILSVRC大赛而提出的CNN分类模型。它发表于2014年的CVPR上面。在深度学习领域Google出品几乎必为精品,Inception也不例外。
它乍看上去像是蛮复杂的,但细看其结构就会发现它其实就是用一个个Inception module给堆起来的。它的设计充满了科学理论与工程实践的结合,是一个典型的data scientist与软件工程师结合搞出来的东东。
在此之前经典的CNN模型像LeNet/Alexnet/VGG等无不是一个模子即使用Conv/Pool/Normalization/Activation等层来不断累积而成。模型对数据集概率分布的表达能力则往往通过单纯增加模型的深度(层数)或宽度(层的channels数)来提高(当然这也亦是当下深度学习领域的共识)。但这样进行网络设计一般会等来巨量的计算开销,因为每一层channels数目的增加都会随着层深而指数级增加,这大大地限制了模型的实际应用。
GoogleNet团队在考虑网络设计时不只注重增加模型的分类精度,同时也考虑了其可能的计算与内存使用开销。他们借鉴了诸多前人的观点与经验(尤其是Network in Network中使用1x1 conv及AvgPool的idea),想通过一种spared layer architecture来实现较优的多维度特征表达,然后通过对这种结构进行叠加,中间不时再插入一些MaxPool层以减少参数数目(从而节省内存与计算开销),最终就行成了Inception v1分类模型。它作为2014年ILSVRC图像分类大赛中的最优选手,取得了非常大的成功。后来GoogleNet团队再接再厉接连提出了融入更新思想,同时分类精度也更高的Inception v2/Inception v3/Inception v4及Inception-Resnet等模型,从而将Inception的思想推至了当下的巅峰。此是后话,欲知Inception系列模型的渊源还是须从这个最早的Inception v1开始。
Inception模块设计
传统的CNN模型设计,其能力增加往往通过增加层数及增宽层的通道数来实现。但这会带来两个问题,首先这两种设计思路都是在高密度计算的单元上(如FC层/Conv层)实现的,它会带来大量的训练参数增加,而过多的参数往往意味着容易出现过拟合;其次单纯曾加密集计算单元的层数或每层宽度都会招至后须扩展的指数级的计算量增加。
显然通过使用一种稀疏的层次结构而非使用像FC/Conv这样的全级联式的结构有助于计算开销的降低。而且一旦这种稀疏的结构设计良好可以有效地扩大表达特征的范围,从而更有效地对图片信息进行表达。可过于稀疏的结构计算一般都不大高效(当下用于CPU/GPU上的一些高效加速库多是在密集计算上进行优化的),同时也会带来较多的cache miss及内存地址非连续搜索的overhead。最终GoogleNet团队选择了中间路线即使用由密集计算子结构组合而成的稀疏模块来用于特征提取及表达,这就是用于构建Inception v1的Inception module如下图中a所示。
其中1x1/3x3/5x5这三种Conv kernels的选择决定是基于方便(因为这几种kernels用的多啊,而且比较容易对齐,padding)来定的(汗)。
图a的这个基本module显然在计算开销上隐藏着重大问题即它的输出将每个不同尺度的conv的输出级连起来用于下一个module的输入。这势必会招至计算量的指数级增加。因此作者借鉴Network in Network中的idea,在每个子conv层里使用了1x1的conv来作上一层的输入feature maps的channels数缩减、归总。如此每个Inception module里的计算都由各自的1x1 conv来隔离,从而不会像传统CNN深度模型那样随着深度增加其计算量也指数级增加。这就是最终用于构建Inception 网络的基础模块inception即图b。
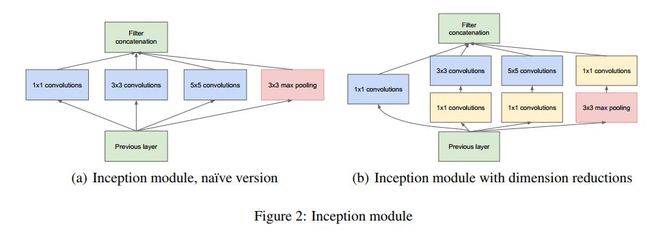
Inception模块
GoogleNet

GoogleNet网络结构
上表即为GoogleNet的网络结构设计概况。可以看出并非整个网络都是由Inception module来组成。它的前面几层采用了类似于经典网络的那种单尺度Conv/Pool/ReLu的设计,这主要是出于用于进行模型计算的系统架构的实际考虑。
作者表明我们可以灵活地根据自己所有的硬件/软件/系统等情况来选择Inception网络中各模块的使用(modules数目及其上的conv的channels数)。而上表所列的这个有着22个参数层的GoogleNet只是在作者他们实验所用的机器上得到的较优网络。因此我们不必过于拘泥于它的具体实现细节,只需了解它的本质设计思想即可。
模型的最后会选通过一个AvgPool层来处理最终的feature maps,然后再由FC层汇总生成1000个输出,进而由Softmax来得到1000类的概率分布。随着CNN模型的加深,它最终表达的特征也愈加地抽象,只使用最后层次的特征可能会招至对小尺度目标的忽略,因此作者分别在中间及较靠后层的地方插入了两个独立的分类层以在训练时协同发挥影响。下图即为最终的GoogleNet模型。
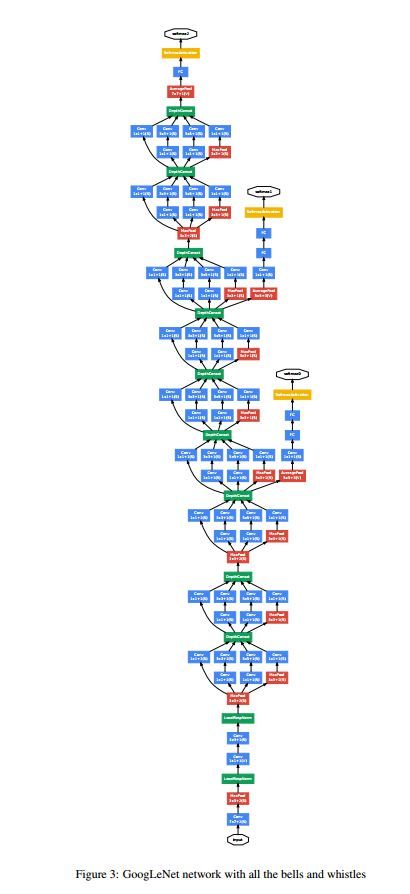
GoogleNet模型
模型训练
这算是当时最为复杂的模型了,多达22层。它的训练难度显然也是空前的。作者使用他们内部的DistBelief分布式系统对模型进行训练,中间使用了模型并行与数据并行两种多节点并行方式(这个难度其实还是蛮高的,玩过多节点训练的人都懂!)。另外他们还使用了Async sgd的方式进行模型参数更新(这使得模型的训练难度更是增加了,没办法估计他们当时也是觉着训练时间实在太久了,所以才会选择使用Async sgd这种加速收敛的方式吧)。
此外作者使用了集成多个模型(6个结构相同,1个略不同;相用相同的初始化,只是不同的shuffle过的数据集)来提高分类准确率的做法。同时也使用了像resize/不同scales/镜像及color distortation等多种数据增强的方式。
实验结果
下表中即为GoogleNet网络与其它模型的结果对比。
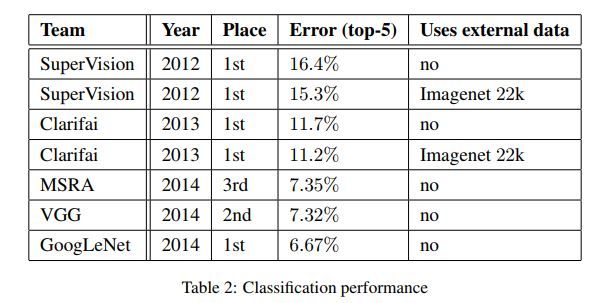
GoogleNet与其它模型的分类结果对比
代码分析
当下大多数的经典模型都已经在Intel caffe里面有了良好实现。我们甚至不需要GPU,单单用自己家datacenter里面的CPUs也能玩转下模型训练及推理。
下面为data layer层,与VGG等的并无差别。
layer{name:"data"type:"Data"top:"data"top:"label"include { phase: TRAIN }transform_param{mirror: true crop_size:224mean_value:104mean_value:117mean_value:123}data_param{source:"examples/imagenet/ilsvrc12_train_lmdb"batch_size:32backend: LMDB }}
以下数层则为网络中inception_3a 模块的组成情况。
layer{name:"inception_3a/1x1"type:"Convolution"bottom:"pool2/3x3_s2"top:"inception_3a/1x1"param { lr_mult:1decay_mult:1}param{lr_mult:2decay_mult:0}convolution_param{num_output:64kernel_size:1weight_filler { type:"xavier"}bias_filler{type:"constant"value:0.2} }}layer{name:"inception_3a/relu_1x1"type:"ReLU"bottom:"inception_3a/1x1"top:"inception_3a/1x1"}layer{name:"inception_3a/3x3_reduce"type:"Convolution"bottom:"pool2/3x3_s2"top:"inception_3a/3x3_reduce"param { lr_mult:1decay_mult:1}param{lr_mult:2decay_mult:0}convolution_param{num_output:96kernel_size:1weight_filler { type:"xavier"}bias_filler{type:"constant"value:0.2} }}layer{name:"inception_3a/relu_3x3_reduce"type:"ReLU"bottom:"inception_3a/3x3_reduce"top:"inception_3a/3x3_reduce"}layer{name:"inception_3a/3x3"type:"Convolution"bottom:"inception_3a/3x3_reduce"top:"inception_3a/3x3"param { lr_mult:1decay_mult:1}param{lr_mult:2decay_mult:0}convolution_param{num_output:128pad:1kernel_size:3weight_filler { type:"xavier"}bias_filler{type:"constant"value:0.2} }}layer{name:"inception_3a/relu_3x3"type:"ReLU"bottom:"inception_3a/3x3"top:"inception_3a/3x3"}layer{name:"inception_3a/5x5_reduce"type:"Convolution"bottom:"pool2/3x3_s2"top:"inception_3a/5x5_reduce"param { lr_mult:1decay_mult:1}param{lr_mult:2decay_mult:0}convolution_param{num_output:16kernel_size:1weight_filler { type:"xavier"}bias_filler{type:"constant"value:0.2} }}layer{name:"inception_3a/relu_5x5_reduce"type:"ReLU"bottom:"inception_3a/5x5_reduce"top:"inception_3a/5x5_reduce"}layer{name:"inception_3a/5x5"type:"Convolution"bottom:"inception_3a/5x5_reduce"top:"inception_3a/5x5"param { lr_mult:1decay_mult:1}param{lr_mult:2decay_mult:0}convolution_param{num_output:32pad:2kernel_size:5weight_filler { type:"xavier"}bias_filler{type:"constant"value:0.2} }}layer{name:"inception_3a/relu_5x5"type:"ReLU"bottom:"inception_3a/5x5"top:"inception_3a/5x5"}layer{name:"inception_3a/pool"type:"Pooling"bottom:"pool2/3x3_s2"top:"inception_3a/pool"pooling_param { pool: MAX kernel_size:3stride:1pad:1}}layer{name:"inception_3a/pool_proj"type:"Convolution"bottom:"inception_3a/pool"top:"inception_3a/pool_proj"param { lr_mult:1decay_mult:1}param{lr_mult:2decay_mult:0}convolution_param{num_output:32kernel_size:1weight_filler { type:"xavier"}bias_filler{type:"constant"value:0.2} }}layer{name:"inception_3a/relu_pool_proj"type:"ReLU"bottom:"inception_3a/pool_proj"top:"inception_3a/pool_proj"}layer{name:"inception_3a/output"type:"Concat"bottom:"inception_3a/1x1"bottom:"inception_3a/3x3"bottom:"inception_3a/5x5"bottom:"inception_3a/pool_proj"top:"inception_3a/output"}
最后则是其AvgPool/DropOut/FC的使用。及最终所生成的loss与accuracy top-1/top-5实现。
layer{name:"pool5/7x7_s1"type:"Pooling"bottom:"inception_5b/output"top:"pool5/7x7_s1"pooling_param { pool: AVE kernel_size:7stride:1}}layer{name:"pool5/drop_7x7_s1"type:"Dropout"bottom:"pool5/7x7_s1"top:"pool5/7x7_s1"dropout_param { dropout_ratio:0.4}}layer{name:"loss3/classifier"type:"InnerProduct"bottom:"pool5/7x7_s1"top:"loss3/classifier"param { lr_mult:1decay_mult:1}param{lr_mult:2decay_mult:0}inner_product_param{num_output:1000weight_filler { type:"xavier"}bias_filler{type:"constant"value:0} }}layer{name:"loss3/loss3"type:"SoftmaxWithLoss"bottom:"loss3/classifier"bottom:"label"top:"loss3/loss3"loss_weight:1}layer{name:"loss3/top-1"type:"Accuracy"bottom:"loss3/classifier"bottom:"label"top:"loss3/top-1"include { phase: TEST }}layer{name:"loss3/top-5"type:"Accuracy"bottom:"loss3/classifier"bottom:"label"top:"loss3/top-5"include { phase: TEST }accuracy_param{top_k:5}}
参考文献
Going deeper with convolutions, Christian-Szegedy, 2014
https://github.com/intel/caffe
作者:manofmountain
链接:https://www.jianshu.com/p/57cccc799277
來源:
著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。