VGG网络模型详解
如今深度学习发展火热,但很多优秀的文章都是基于经典文章,经典文章中的一句一词都值得推敲和分析。此外,深度学习虽然一直被人诟病缺乏足够令人信服的理论,但不代表我们不能感性分析理解,下面我们将对2014年夺得ImageNet的定位第一和分类第二的VGG网络进行分析,在此过程中更多的是对这篇经典文章的感性分析,希望和大家共同交流产生共鸣,如果有理解不到位的也真诚期待指出错误。

Simonyan, Karen, and Andrew Zisserman. "Very deep convolutional networks for large-scale image recognition." arXiv preprint arXiv:1409.1556 (2014).
论文下载地址:https://arxiv.org/pdf/1409.1556.pdf
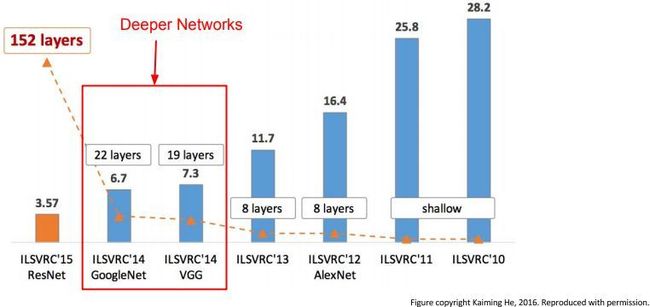
这篇文章是以比赛为目的——解决ImageNet中的1000类图像分类和定位问题。在此过程中,作者做了六组实验,对应6个不同的网络模型,这六个网络深度逐渐递增的同时,也有各自的特点。实验表明最后两组,即深度最深的两组16和19层的VGGNet网络模型在分类和定位任务上的效果最好。作者因此斩获2014年分类第二(第一是GoogLeNet),定位任务第一。
其中,模型的名称——“VGG”代表了牛津大学的Oxford Visual Geometry Group,该小组隶属于1985年成立的Robotics Research Group,该Group研究范围包括了机器学习到移动机器人。下面是一段来自知乎对同年GoogLeNet和VGG的描述:
GoogLeNet和VGG的Classification模型从原理上并没有与传统的CNN模型有太大不同。大家所用的Pipeline也都是:训练时候:各种数据Augmentation(剪裁,不同大小,调亮度,饱和度,对比度,偏色),剪裁送入CNN模型,Softmax,Backprop。测试时候:尽量把测试数据又各种Augmenting(剪裁,不同大小),把测试数据各种Augmenting后在训练的不同模型上的结果再继续Averaging出最后的结果。
需要注意的是,在VGGNet的6组实验中,后面的4个网络均使用了pre-trained model A的某些层来做参数初始化。虽然作者没有提该方法带来的性能增益,但我认为是很大的。不过既然是开篇,先来看看VGG的特点:
小卷积核。作者将卷积核全部替换为3x3(极少用了1x1);
小池化核。相比AlexNet的3x3的池化核,VGG全部为2x2的池化核;
层数更深特征图更宽。基于前两点外,由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓;
全连接转卷积。网络测试阶段将训练阶段的三个全连接替换为三个卷积,测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。
最后我会再次引用CS231n对于VGG的中肯评价进行总结,不过还是先从当时的任务和历史背景开始说明。
任务背景

自从2012年AlexNet将深度学习的方法应用到ImageNet的图像分类比赛中并取得state of the art的惊人结果后,大家都竞相效仿并在此基础上做了大量尝试和改进,先从两个性能提升的例子说起:
小卷积核。在第一个卷积层用了更小的卷积核和卷积stride(Zeiler & Fergus, 2013; Sermanet et al., 2014);
多尺度。训练和测试使用整张图的不同尺度(Sermanet et al., 2014; Howard, 2014)。
作者也是看到这两个没有谈到深度的工作,因而受到启发,不仅将上面的两种方法应用到自己的网络设计和训练测试阶段,同时想再试试深度对结果的影响。
小卷积核
说到网络深度,这里就不得不提到卷积,虽然AlexNet有使用了11x11和5x5的大卷积,但大多数还是3x3卷积,对于stride=4的11x11的大卷积核,我认为在于一开始原图的尺寸很大因而冗余,最为原始的纹理细节的特征变化用大卷积核尽早捕捉到,后面的更深的层数害怕会丢失掉较大局部范围内的特征相关性,后面转而使用更多3x3的小卷积核(和一个5x5卷积)去捕捉细节变化。
而VGGNet则清一色使用3x3卷积。因为卷积不仅涉及到计算量,还影响到感受野。前者关系到是否方便部署到移动端、是否能满足实时处理、是否易于训练等,后者关系到参数更新、特征图的大小、特征是否提取的足够多、模型的复杂度和参数量等等。
计算量
在计算量这里,为了突出小卷积核的优势,我拿同样conv3x3、conv5x5、conv7x7、conv9x9和conv11x11,在224x224x3的RGB图上(设置pad=1,stride=4,output_channel=96)做卷积,卷积层的参数规模和得到的feature map的大小如下:
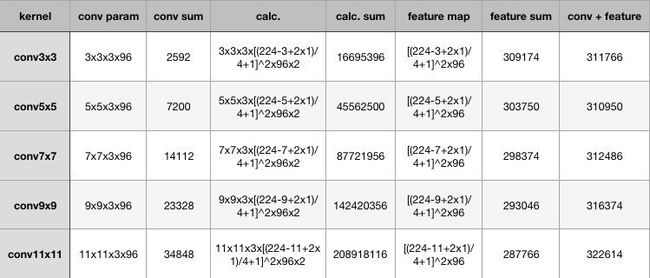
从上表可以看出,大卷积核带来的特征图和卷积核得参数量并不大,无论是单独去看卷积核参数或者特征图参数,不同kernel大小下这二者加和的结构都是30万的参数量,也就是说,无论大的卷积核还是小的,对参数量来说影响不大甚至持平。
增大的反而是卷积的计算量,在表格中列出了计算量的公式,最后要乘以2,代表乘加操作。为了尽可能证一致,这里所有卷积核使用的stride均为4,可以看到,conv3x3、conv5x5、conv7x7、conv9x9、conv11x11的计算规模依次为:1600万,4500万,1.4亿、2亿,这种规模下的卷积,虽然参数量增长不大,但是计算量是惊人的。
总结一下,我们可以得出两个结论:
同样stride下,不同卷积核大小的特征图和卷积参数差别不大;
越大的卷积核计算量越大。
其实对比参数量,卷积核参数的量级在十万,一般都不会超过百万。相比全连接的参数规模是上一层的feature map和全连接的神经元个数相乘,这个计算量也就更大了。其实一个关键的点——多个小卷积核的堆叠比单一大卷积核带来了精度提升,这也是最重要的一点。
感受野
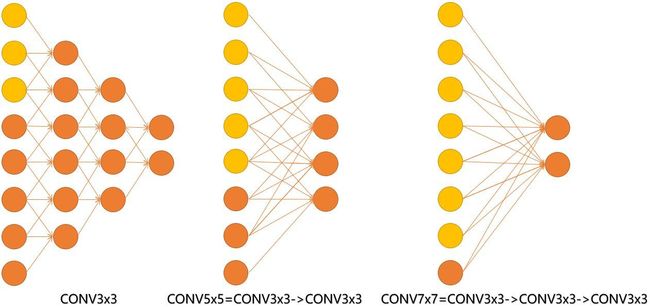
说完了计算量我们再来说感受野。这里给出一张VGG作者的PPT,作者在VGGNet的实验中只用了两种卷积核大小:1x1和3x3。作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。

见下图,输入的8个元素可以视为feature map的宽或者高,当输入为8个神经元经过三层conv3x3的卷积得到2个神经元。三个网络分别对应stride=1,pad=0的conv3x3、conv5x5和conv7x7的卷积核在3层、1层、1层时的结果。因为这三个网络的输入都是8,也可看出2个3x3的卷积堆叠获得的感受野大小,相当1层5x5的卷积;而3层的3x3卷积堆叠获取到的感受野相当于一个7x7的卷积。
input=8,3层conv3x3后,output=2,等同于1层conv7x7的结果;
input=8,2层conv3x3后,output=2,等同于2层conv5x5的结果。
或者我们也可以说,三层的conv3x3的网络,最后两个输出中的一个神经元,可以看到的感受野相当于上一层是3,上上一层是5,上上上一层(也就是输入)是7。
此外,倒着看网络,也就是backprop的过程,每个神经元相对于前一层甚至输入层的感受野大小也就意味着参数更新会影响到的神经元数目。在分割问题中卷积核的大小对结果有一定的影响,在上图三层的conv3x3中,最后一个神经元的计算是基于第一层输入的7个神经元,换句话说,反向传播时,该层会影响到第一层conv3x3的前7个参数。从输出层往回forward同样的层数下,大卷积影响(做参数更新时)到的前面的输入神经元越多。
优点
既然说到了VGG清一色用小卷积核,结合作者和自己的观点,这里整理出小卷积核比用大卷积核的三点优势:
更多的激活函数、更丰富的特征,更强的辨别能力。卷积后都伴有激活函数,更多的卷积核的使用可使决策函数更加具有辨别能力,此外就卷积本身的作用而言,3x3比7x7就足以捕获特征的变化:3x3的9个格子,最中间的格子是一个感受野中心,可以捕获上下左右以及斜对角的特征变化。主要在于3个堆叠起来后,三个3x3近似一个7x7,网络深了两层且多出了两个非线性ReLU函数,(特征多样性和参数参数量的增大)使得网络容量更大(关于model capacity,AlexNet的作者认为可以用模型的深度和宽度来控制capacity),对于不同类别的区分能力更强(此外,从模型压缩角度也是要摒弃7x7,用更少的参数获得更深更宽的网络,也一定程度代表着模型容量,后人也认为更深更宽比矮胖的网络好);
卷积层的参数减少。相比5x5、7x7和11x11的大卷积核,3x3明显地减少了参数量,这点可以回过头去看上面的表格。比方input channel数和output channel数均为C,那么3层conv3x3卷积所需要的卷积层参数是:3x(Cx3x3xC)=27C^2,而一层conv7x7卷积所需要的卷积层参数是:Cx7x7xC=49C^2。conv7x7的卷积核参数比conv3x3多了(49-27)/27x100% ≈ 81%;
小卷积核代替大卷积核的正则作用带来性能提升。作者用三个conv3x3代替一个conv7x7,认为可以进一步分解(decomposition)原本用7x7大卷积核提到的特征,这里的分解是相对于同样大小的感受野来说的。关于正则的理解我觉得还需要进一步分析。
其实最重要的还是多个小卷积堆叠在分类精度上比单个大卷积要好。
小池化核
这里的“小”是相对于AlexNet的3x3的池化核来说的。不过在说池化前,先说一下CS231n的博客里的描述网络结构的layer pattern,一般常见的网络都可以表示为:INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC的形式,其中,?表示pool是一个可选项。这样的pattern因为可以对小卷积核堆叠,很自然也更适合描述深层网络的构建,例如INPUT -> FC表示一个线性分类器。
不过从layer pattern中的[[CONV -> RELU]*N -> POOL?]*M部分,可以看出卷积层一般后面接完激活函数就紧跟池化层。对于这点我的理解是,池化做的事情是根据对应的max或者average方式进行特征筛选,还是在做特征工程上的事情。
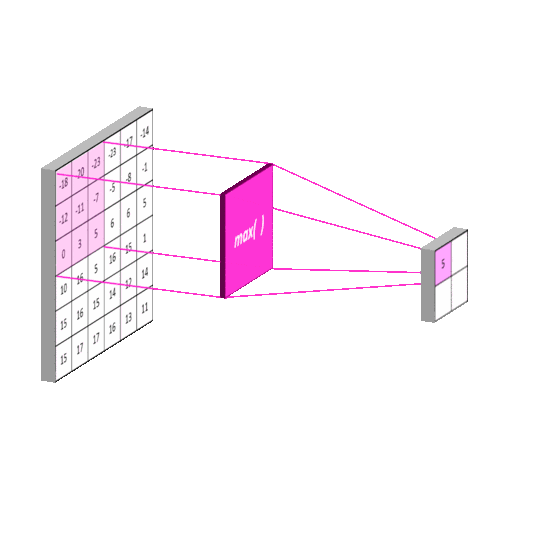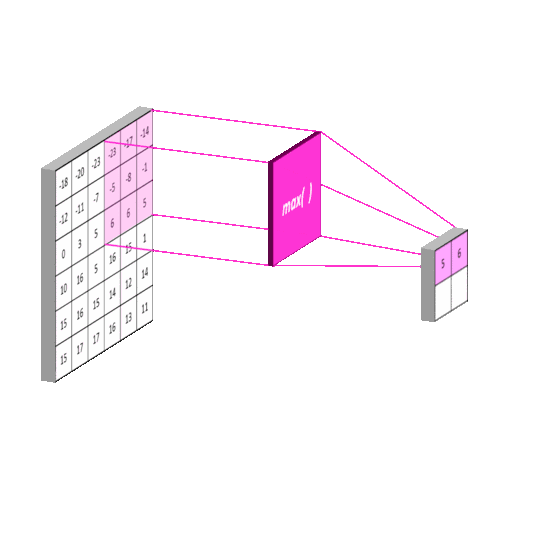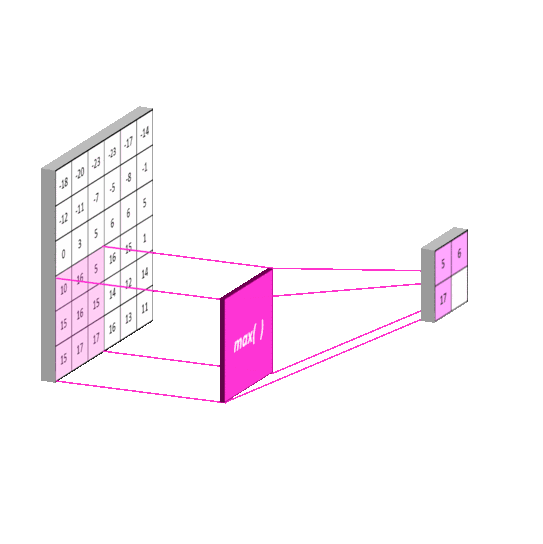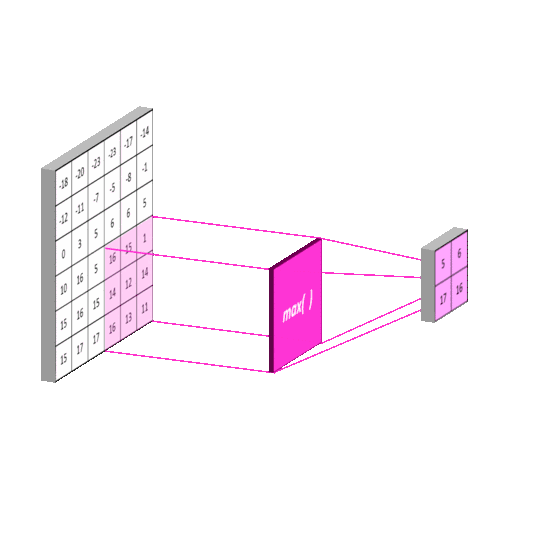
2012年的AlexNet,其pooling的kernel size全是奇数,里面所有池化采用kernel size为3x3,stride为2的max-pooling。而VGGNet所使用的max-pooling的kernel size均为2x2,stride为2的max-pooling。pooling kernel size从奇数变为偶数。小kernel带来的是更细节的信息捕获,且是max-pooling更见微的同时进一步知躇。
在当时也有average pooling,但是在图像任务上max-pooling的效果更胜一筹,所以图像大多使用max-pooling。在这里我认为max-pooling更容易捕捉图像上的变化,梯度的变化,带来更大的局部信息差异性,更好地描述边缘、纹理等构成语义的细节信息,这点尤其体现在网络可视化上。
概述全连接和特征图
全连接
VGG最后三个全连接层在形式上完全平移AlexNet的最后三层,VGGNet后面三层(三个全连接层)为:
FC4096-ReLU6-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
FC4096-ReLU7-Drop0.5,FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
FC1000(最后接SoftMax1000分类),FC为高斯分布初始化(std=0.005),bias常数初始化(0.1)
超参数上只有最后一层fc有变化:bias的初始值,由AlexNet的0变为0.1,该层初始化高斯分布的标准差,由AlexNet的0.01变为0.005。超参数的变化,我的理解是,作者自己的感性理解指导认为,我以贡献bias来降低标准差,相当于标准差和bias间trade-off,或许作者实验validate发现这个值比之前AlexNet设置的(std=0.01,bias=0)要更好。
特征图
网络在随层数递增的过程中,通过池化也逐渐忽略局部信息,特征图的宽度高度随着每个池化操作缩小50%,5个池化l操作使得宽或者高度变化过程为:224->112->56->28->14->7,但是深度depth(或说是channel数),随着5组卷积在每次增大一倍:3->64->128->256->512->512。特征信息从一开始输入的224x224x3被变换到7x7x512,从原本较为local的信息逐渐分摊到不同channel上,随着每次的conv和pool操作打散到channel层级上。
特征图的宽高从512后开始进入全连接层,因为全连接层相比卷积层更考虑全局信息,将原本有局部信息的特征图(既有width,height还有channel)全部映射到4096维度。也就是说全连接层前是7x7x512维度的特征图,估算大概是25000,这个全连接过程要将25000映射到4096,大概是5000,换句话说全连接要将信息压缩到原来的五分之一。VGGNet有三个全连接,我的理解是作者认为这个映射过程的学习要慢点来,太快不易于捕捉特征映射来去之间的细微变化,让backprop学的更慢更细一些(更逐渐)。
换句话说,维度在最后一个卷积后达到7x7x512,即大概25000,紧接着压缩到4096维,可能是作者认为这个过程太急,又接一个fc4096作为缓冲,同时两个fc4096后的relu又接dropout0.5去过渡这个过程,因为最后即将给1k-way softmax,所以又接了一个fc1000去降低softmax的学习压力。
feature map维度的整体变化过程是:先将local信息压缩,并分摊到channel层级,然后无视channel和local,通过fc这个变换再进一步压缩为稠密的feature map,这样对于分类器而言有好处也有坏处,好处是将local信息隐藏于/压缩到feature map中,坏处是信息压缩都是有损失的,相当于local信息被破坏了(分类器没有考虑到,其实对于图像任务而言,单张feature map上的local信息还是有用的)。
但其实不难发现,卷积只增加feature map的通道数,而池化只减少feature map的宽高。如今也有不少做法用大stride卷积去替代池化,未来可能没有池化。
卷积组
说到特征图的变化,我们可以进一步切分网络观察整体结构,再次拿出CS231n的博客里的描述网络结构的layer pattern:INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC,以pooling操作为切分点对整个网络分组的话,我们会得到五组卷积,五组卷积中有2种卷积组的形式,切分后的VGG网络可以描述成下面这样:
前两组卷积形式一样,每组都是:conv-relu-conv-relu-pool;
中间三组卷积形式一样,每组都是:conv-relu-conv-relu-conv-relu-pool;
最后三个组全连接fc层,前两组fc,每组都是:fc-relu-dropout;最后一个fc仅有fc。
虽然CS231n里将这种形式称为layer pattern,但我更喜欢把以卷积起始池化为止的最短结构称之为“卷积组”。
不难发现VGG有两种卷积组,第二种([conv-relu]-[conv-relu]-[conv-relu]-pool)比第一种([conv-relu]-[conv-relu]-pool) 多了一个[conv-relu]。我的理解是:
多出的relu对网络中层进一步压榨提炼特征。结合一开始单张feature map的local信息更多一些,还没来得及把信息分摊到channel级别上,那么往后就慢慢以增大conv filter的形式递增地扩大channel数,等到了网络的中层,channel数升得差不多了(信息分摊到channel上得差不多了),那么还想抽local的信息,就通过再加一个[conv-relu]的形式去压榨提炼特征。有点类似传统特征工程中,已有的特征在固定的模型下没有性能提升了,那就用更多的非线性变换对已有的特征去做变换,产生更多的特征的意味;
多出的conv对网络中层进一步进行学习指导和控制不要将特征信息漂移到channel级别上。
上一点更多的是relu的带来的理解,那么多出的[conv-relu]中conv的意味就是模型更强的对数据分布学习过程的约束力/控制力,做到信息backprop可以回传回来的学习指导。本身多了relu特征变换就加剧(权力释放),那么再用一个conv去控制(权力回收),也在指导网络中层的收敛;
其实conv本身关注单张feature map上的局部信息,也是在尝试去尽量平衡已经失衡的channel级别(depth)和local级别(width、height)之间的天平。这个conv控制着特征的信息量不要过于向着channel级别偏移。
关于Layer pattern,CS231n的博客给出如下观点:
串联和串联中带有并联的网络架构。近年来,GoogLeNet在其网络结构中引入了Inception模块,ResNet中引入了Residual Block,这些模块都有自己复杂的操作。换句话说,传统一味地去串联网络可能并不如这样串联为主线,带有一些并联同类操作但不同参数的模块可能在特征提取上更好。 所以我认为这里本质上依旧是在做特征工程,只不过把这个过程放在block或者module的小的网络结构里,毕竟kernel、stride、output的大小等等超参数都要自己设置,目的还是产生更多丰富多样的特征。
用在ImageNet上pre-trained过的模型。设计自己模型架构很浪费时间,尤其是不同的模型架构需要跑数据来验证性能,所以不妨使用别人在ImageNet上训练好的模型,然后在自己的数据和问题上在进行参数微调,收敛快精度更好。 我认为只要性能好精度高,选择什么样的模型架构都可以,但是有时候要结合应用场景,对实时性能速度有要求的,可能需要多小网络,或者分级小网络,或者级联的模型,或者做大网络的知识蒸馏得到小网络,甚至对速度高精度不要求很高的,可以用传统方法。
层维度
要说到layer pattern,不得不提到sizing pattern,其实这里相当于前面feature map维度变化的补充,这也是CS231n里所讲到的。对于每种层,有不同的默认设定:
输入层
大都是2的N次方,这和网络中卷积或者池化层出现的stride为2的次数有关,比方VGGNet中每个pattern的卷积不会对feature map的宽度和高度有改变,而每个pattern结束前总会做一个stride为2的下采样,因为有5组,那么做5次就是32,所以VGGNet网络input大小一般都是32的倍数,即,n是下采样的次数,a是最终卷积和池化得到的feature map大小,如224或者384。
卷积层
现在常用的是小卷积核如3x3或者1x1。卷积为了保留feature map不变,通常会采取pad为1的操作,其实具体来说应该是:为了保证卷积后的feature map的宽度和高度不变,那么有pad=(F-1)/2,但我觉得这个有点问题,可以改成更一般的形式,不过首先可以看看计算下一层feature map宽高的公式:
因为要保证和一样,有,那么可以导出:
当Stride=1时,那么pad=(F-1)/2。因为现在stride=1的3x3卷积用的多,所以大家会默认说是pad=1(关于这点上,也是由于实验发现这样保留feature map的宽高情况下,性能好的缘故,我认为填补主要是针对stride大于1的情况带来的边界问题,如果input尺寸不是事先设定的,那么就会有边界无法卷积到的问题带来信息丢失。不过这种填补我认为也有一定问题,就是说原本conv3x3去计算对应位置的3x3,而填补后为0,这样相当于少算了一些值,这肯定还是有影响的)。但若stride不是1,那么要保证前后feature map的宽高一样,就要根据上面的公式计算得出。
另一个点是通常与Input比较接近的conv会采用大卷积核。关于接近input层使用较大的卷积核这点,我认为先是考虑到后面的操作,先尽可能用大的卷积核cover更多的原始信息(虽然经过了卷积有一些变换),第二点在于大卷积核带来的大感受野,后面的卷积层能的一个神经元能看到更大的input,第三点是GPU的显存受限,经典的例子就是AlexNet使用stride=4的conv11x11,目的就是从一开始就减少显存占用,其实这里的大stride,我觉得起到了一些正则的作用。但缺点也很明显,因为卷积核变大,矩阵乘法实现卷积时,若没有大stride,那么第一个矩阵的列数,也就是第二个矩阵的行数,会变大,带来大的计算量。所以在AlexNet中,大卷积核也对应使用了大的stride值。
池化层
常见2x2的max-pooling,少见3x3或者更大的kernel。更大的kernel带来的问题是信息丢失带来的信息损失,此外,stride通常为2;
其实按照以上的设定看来,也是有好处的。卷积专注于保留空间信息前提下的channel变换,而池化则专注于空间信息的变换(下采样)。
全连接转卷积
VGG比较神奇的一个特点就是“全连接转卷积”,下面是作者原文test小节中的一句:
Namely, the fully-connected layers are first converted to convolutional layers (the first FC layer to a 7 × 7 conv. layer, the last two FC layers to 1 × 1 conv. layers).
也就是说,作者在测试阶段把网络中原本的三个全连接层依次变为1个conv7x7,2个conv1x1,也就是三个卷积层。改变之后,整个网络由于没有了全连接层,网络中间的feature map不会固定,所以网络对任意大小的输入都可以处理,因而作者在紧接着的后一句说到: The resulting fully-convolutional net is then applied to the whole (uncropped) image。
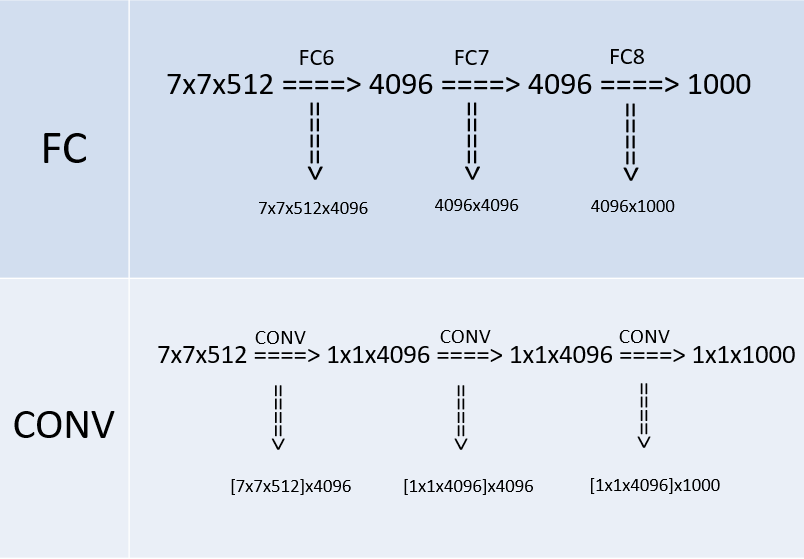
上图是VGG网络最后三层的替换过程,上半部分是训练阶段,此时最后三层都是全连接层(输出分别是4096、4096、1000),下半部分是测试阶段(输出分别是1x1x4096、1x1x4096、1x1x1000),最后三层都是卷积层。下面我们来看一下详细的转换过程(以下过程都没有考虑bias,略了):
先看训练阶段,有4096个输出的全连接层FC6的输入是一个7x7x512的feature map,因为全连接层的缘故,不需要考虑局部性, 可以把7x7x512看成一个整体,25508(=7x7x512)个输入的每个元素都会与输出的每个元素(或者说是神经元)产生连接,所以每个输入都会有4096个系数对应4096个输出,所以网络的参数(也就是两层之间连线的个数,也就是每个输入元素的系数个数)规模就是7x7x512x4096。对于FC7,输入是4096个,输出是4096个,因为每个输入都会和输出相连,即每个输出都有4096条连线(系数),那么4096个输入总共有4096x4096条连线(系数),最后一个FC8计算方式一样,略。
再看测试阶段,由于换成了卷积,第一个卷积后要得到4096(或者说是1x1x4096)的输出,那么就要对输入的7x7x512的feature map的宽高(即width、height维度)进行降维,同时对深度(即Channel/depth维度)进行升维。要把7x7降维到1x1,那么干脆直接一点,就用7x7的卷积核就行,另外深度层级的升维,因为7x7的卷积把宽高降到1x1,那么刚好就升高到4096就好了,最后得到了1x1x4096的feature map。这其中卷积的参数量上,把7x7x512看做一组卷积参数,因为该层的输出是4096,那么相当于要有4096组这样7x7x512的卷积参数,那么总共的卷积参数量就是:
[7x7x512]x4096,这里将7x7x512用中括号括起来,目的是把这看成是一组,就不会懵。
第二个卷积依旧得到1x1x4096的输出,因为输入也是1x1x4096,三个维度(宽、高、深)都没变化,可以很快计算出这层的卷积的卷积核大小也是1x1,而且,通道数也是4096,因为对于输入来说,1x1x4096是一组卷积参数,即一个完整的filter,那么考虑所有4096个输出的情况下,卷积参数的规模就是[1x1x4096]x4096。第三个卷积的计算一样,略。
其实VGG的作者把训练阶段的全连接替换为卷积是参考了OverFeat的工作,如下图是OverFeat将全连接换成卷积后,带来可以处理任意分辨率(在整张图)上计算卷积,而无需对原图resize的优势。
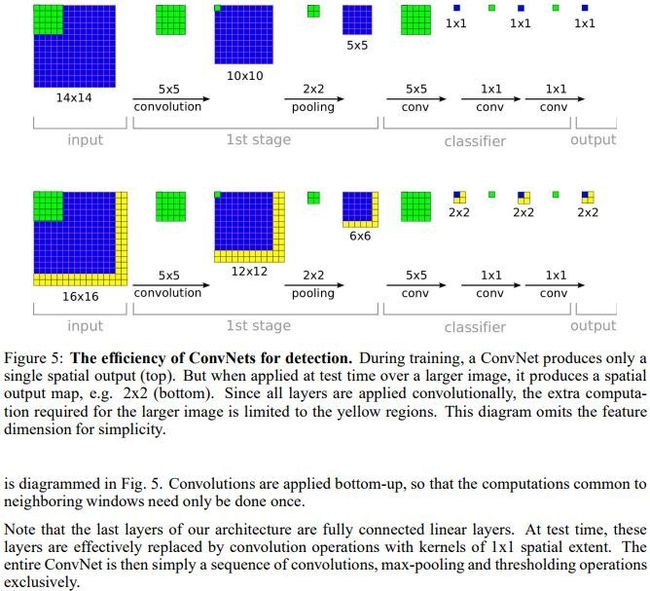
不过可以看到,训练阶段用的是crop或者resize到14x14的输入图像,而测试阶段可以接收任意维度,如果使用未经crop的原图作为输入(假设原图比crop或者resize到训练尺度的图像要大),这会带来一个问题:feature map变大了。比方VGG训练阶段用224x224x3的图作为模型输入,经过5组卷积和池化,最后到7x7x512维度,最后经过无论是三个卷积或者三个全连接,维度都会到1x1x4096->1x1x4096->1x1x1000,而使用384x384x3的图做模型输入,到五组卷积和池化做完(即),那么feature map变为12x12x512,经过三个由全连接变的三个卷积,即feature map经历了6x6x4096->6x6x4096->6x6x1000的变化过程后,再把这个6x6x1000的feature map进行average,最终交给SoftMax的是1x1x1000的feature map进行分类。
以上便是将全连接转换成卷积以及将转换后的全卷积网络应用到测试阶段的方式。其实进一步来看卷积与全连接,二者最明显的差异不外乎一个前者是局部连接,但其实二者都有用到全局信息,只是卷积是通过层层堆叠来利用的,而全连接就不用说了,全连接的方式直接将上一层的特征图全部用上,稀疏性比较大,而卷积从网络深度这一角度,基于输入到当前层这一过程逐级逐层榨取的方式利用全局信息。
1x1卷积
VGG在最后的三个阶段都用到了1x1卷积核,选用1x1卷积核的最直接原因是在维度上继承全连接,然而作者首先认为1x1卷积可以增加决策函数(decision function,这里的决策函数我认为就是softmax)的非线性能力,非线性是由激活函数ReLU决定的,本身1x1卷积则是线性映射,即将输入的feature map映射到同样维度的feature map。作者还提到“Network in Network” architecture of Lin et al. (2014).这篇文章就大量使用了1x1卷积核。
此外,查了知乎简单总结下1x1卷积的特点(就不说加入非线性这个conv自带的特点了):
专注于跨通道的特征组合:conv1x1根本不考虑单通道上像素的局部信息(不考虑局部信息),专注于那一个卷积核内部通道的信息整合。conv3x3既考虑跨通道,也考虑局部信息整合;
对feature map的channel级别降维或升维:例如224x224x100的图像(或feature map)经过20个conv1x1的卷积核,得到224x224x20的feature map。尤其当卷积核(即filter)数量达到上百个时,3x3或5x5卷积的计算会非常耗时,所以1x1卷积在3x3或5x5卷积计算前先降低feature map的维度。
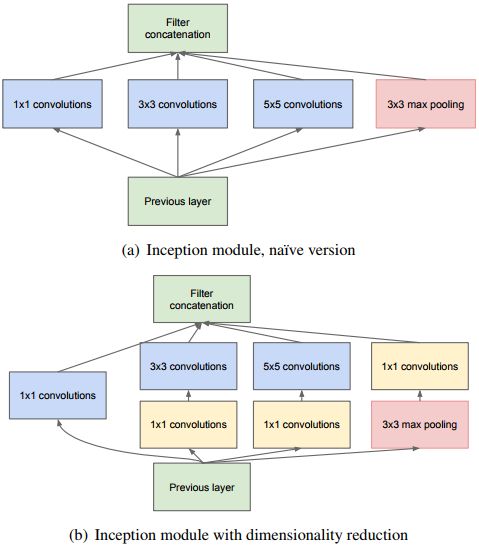
关于小卷积核前人就有使用,如Ciresan et al. (2011)还有Goodfellow et al. (2014),后者使用11层的网络解决街道数量的识别问题(street number classification,我也没看懂是回归还是分类),结果显示更深的网络可以带来更好地网络性能。而作者在小卷积核的基础上使用了更多层数,2014年ImageNet分类比赛的第一名使用GoogLeNet,Szegedy et al., (2014)也使用了更小的卷积核、更深达到22层的网络,使用了5x5、3x3和1x1卷积(实际还用到了7x7的卷积,第一层卷积)。但GoogLeNet的拓扑结构比较复杂,上图是Inception module的结构图,可以看到module内直接使用了常见的三种卷积核进行并联,并将最后的结果feature map直接concate到一起,而VGGNet则是使用传统卷积核串联的方式。

然而,分类性能上同样的单模型,VGGNet比GoogLeNet在top5的错分率要低,虽然不确定是否是因为GoogLeNet没做multi-crop和dense eval.,但假设他们都做了,这样看来似乎VGG从实验结果上表现出其结构设计上比GoogLeNet更适合解决分类问题。
但总之,这种将全连接转成卷积的方式还是很有意思的。但转换后是直接拿来用先前的参数好还是否需要做参数微调转换后的卷积层,还需要实验说明。
实验结论和评价
12年到14年的挑战赛都使用的是1000个类别的ILSVRC-2012数据集(Large Scale Visual Recognition Challenge),其中:
训练集:130万张图片;
验证集:5万张图片;
测试集:10万张图片,这组数据的label没有给出(with held-out class labels)。
两个性能评估准则:top-1和top-5 error。前一个是多类分类错误率,错分的图像的比率。后一个是ILSVRC中主要的评估指标,计算的是预测出来的top5的类别里没有ground truth的比率,即top-5 error。
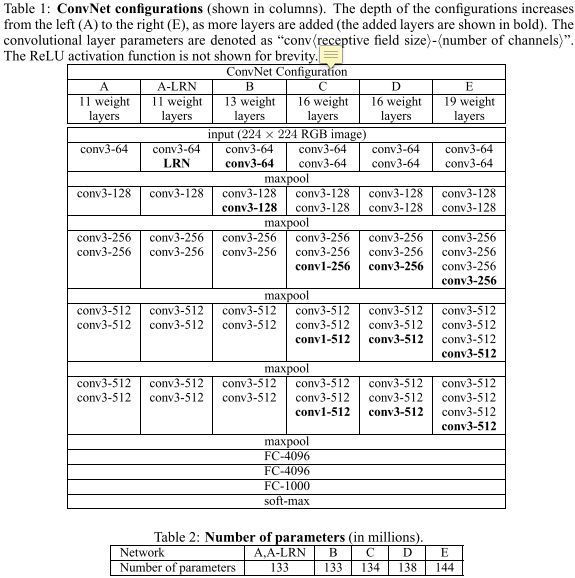
实验结论
因为作者自己在下面实验的缘故,当然没有测试集的ground truth类别,所以作者就用验证集当做测试集来观察模型性能。这里作者使用两种方式来评估模型在测试集(实际的验证集)的性能表现:single scale evaluation和multi-scale evaluation。实验结论:
LRN层无性能增益(A和A-LRN)。作者通过网络A和A-LRN发现AlexNet曾经用到的LRN层(local response normalization,LRN是一种跨通道去normalize像素值的方法)没有性能提升,因此在后面的4组网络中均没再出现LRN层。 当然我也感觉没啥用,想到max-pooling比average-pooling效果好,我就感觉这个LRN没啥用,不过如果把LRN改成跨通道的max-normal,我感觉说不定会有性能提升。特征得到retain更明显。
深度增加,分类性能提高(A、B、C、D、E)。从11层的A到19层的E,网络深度增加对top1和top5的error下降很明显,所以作者得出这个结论,但其实除了深度外,其他几个网络宽度等因素也在变化,depth matters的结论不够convincing。
conv1x1的非线性变化有作用(C和D)。C和D网络层数相同,但D将C的3个conv3x3换成了conv1x1,性能提升。这点我理解是,跨通道的信息交换/融合,可以产生丰富的特征易于分类器学习。conv1x1相比conv3x3不会去学习local的局部像素信息,专注于跨通道的信息交换/融合,同时为后面全连接层(全连接层相当于global卷积)做准备,使之学习过程更自然。
多小卷积核比单大卷积核性能好(B)。作者做了实验用B和自己一个不在实验组里的较浅网络比较,较浅网络用conv5x5来代替B的两个conv3x3。多个小卷积核比单大卷积核效果好,换句话说当考虑卷积核大小时:depths matters。
评价
最后贴出CS231n的评价:
The runner-up in ILSVRC 2014 was the network from Karen Simonyan and Andrew Zisserman that became known as the VGGNet. Its main contribution was in showing that the depth of the network is a critical component for good performance. Their final best network contains 16 CONV/FC layers and, appealingly, features an extremely homogeneous architecture that only performs 3x3 convolutions and 2x2 pooling from the beginning to the end. Their pretrained model is available for plug and play use in Caffe. A downside of the VGGNet is that it is more expensive to evaluate and uses a lot more memory and parameters (140M). Most of these parameters are in the first fully connected layer, and it was since found that these FC layers can be removed with no performance downgrade, significantly reducing the number of necessary parameters.
不难提炼出如下结论:
深度提升性能;
最佳模型:VGG16,从头到尾只有3x3卷积与2x2池化。简洁优美;
开源pretrained model。与开源深度学习框架Caffe结合使用,助力更多人来学习;
卷积可代替全连接。整体参数达1亿4千万,主要在于第一个全连接层,用卷积来代替后,参数量下降(这里的说法我认为是错的,替代前后用同样的输入尺寸,网络参数量、feature map、计算量三者没有变化)且无精度损失。
参考
以下是一些参考文献,虽然不少地方引用了,但是偷懒没有在文中具体标明。老实说,有时间能看原汁原味的东西就不要看别人吃过的,即使是我写的这篇,看原版的东西我觉得收获更大一些。
ILSVRC-2014 presentation http://www.robots.ox.ac.uk/~karen/pdf/ILSVRC_2014.pdf
http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture9.pdf
Convolutional neural networks on the iPhone with VGGNet http://machinethink.net/blog/convolutional-neural-networks-on-the-iphone-with-vggnet/
A Matlab Toolkit for Distance Metric Learning http://www.cs.cmu.edu/~liuy/distlearn.htm
图像处理中的L1-normalize 和L2-normalize - CSDN博客 注:公式写错了 http://blog.csdn.net/a200800170331/article/details/21737741
Feature Visualization https://distill.pub/2017/feature-visualization/#enemy-of-feature-vis
TensorFlow 教程 #14 - DeepDream(多图预警) https://zhuanlan.zhihu.com/p/27546601
caffe/pooling_layer.cpp at 80f44100e19fd371ff55beb3ec2ad5919fb6ac43 · BVLC/caffe https://github.com/BVLC/caffe/blob/80f44100e19fd371ff55beb3ec2ad5919fb6ac43/src/caffe/layers/pooling_layer.cpp
VGG网络中测试时为什么全链接改成卷积? - 知乎 https://www.zhihu.com/question/53420266
pooling mean max 前向和反向传播 - CSDN博客 http://blog.csdn.net/junmuzi/article/details/53206600
caffe/pooling_layer.cpp at 80f44100e19fd371ff55beb3ec2ad5919fb6ac43 · BVLC/caffe https://github.com/BVLC/caffe/blob/80f44100e19fd371ff55beb3ec2ad5919fb6ac43/src/caffe/layers/pooling_layer.cpp
Deep learning:四十七(Stochastic Pooling简单理解) - tornadomeet - 博客园 https://www.cnblogs.com/tornadomeet/p/3432093.html
Convolutional Neural Networks - Basics · Machine Learning Notebook https://mlnotebook.github.io/post/CNN1/
在 Caffe 中如何计算卷积? - 知乎 https://www.zhihu.com/question/28385679
High Performance Convolutional Neural Networks for Document Processing Kumar Chellapilla, Sidd Puri, Patrice Simard https://hal.archives-ouvertes.fr/file/index/docid/112631/filename/p1038112283956.pdf