【MySQL那些事】join的底层原理
前言
在日常开发中,只要写了sql,难免会使用的join关键字连接两个或多个表,在这里还是先解释一下inner join、left join、right join之间的区别以及驱动表的概念。
INNER JOIN:查询两个表之间的交集
取值时遵循笛卡尔乘积,即利用双层循环遍历两个表的数据,若table1的结果集比较少,那么就拿它当作外层循环,称为驱动表,外层循环每取一条数据,就拿该数据去内层循环table2表中匹配结果集,此时table2称为被驱动表
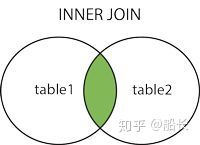
LEFT JOIN:取左表(驱动表)的全部数据,右表(被驱动表)如果有对应数据就显示,没有就为NULL
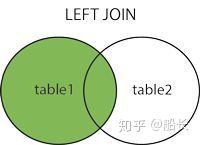
RIGHT JOIN:取右表(驱动表)的全部数据,左表(被驱动表)如果有对应数据就显示,没有就显示为NULL
join连接查询原理
相信大家理解了上面join的用法之后,都会发出这样一个疑问:这效率岂不是低成鬼了?如果你有这种敏感的觉悟,那么恭喜你被认证为实打实的程序猿

但是我们一抓头发马上就能料到,MySQL能活那么久,至今还那么受企业欢迎,怎么会允许这种低效率的事情发生?所以这其中一定有鬼!
没错,MySQL使用了一种算法去优化它:Nested-Loop Join(嵌套循环连接),但是这个算法有三个变种,分别是
Simple Nested-Loop Join 简单嵌套循环连接
Index Nested-Loop Join 索引嵌套循环连接
Block Nested-Loop Join 块索引嵌套连接简单嵌套循环连接
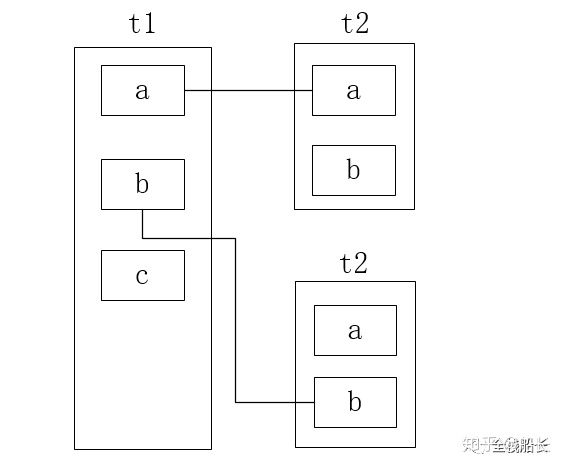
所谓简单嵌套循环连接,其实真的很简单,就是啥都不做,利用循环嵌套对join的所有表逐一去遍历。如下两个表,以t1作为驱动表,遍历到元素a时,从被驱动表t2中匹配与a相等的行,并将匹配结果存储到结果集中,这种方法的效率无疑是非常低的,其时间复杂度O(n) = t1 * t2,真的做了一次笛卡尔乘积。
上面的查询逻辑的伪代码如下
for(M id : main){
for(S main_id : second){
if(id==main_id){
//添加到结果集
}
}
}我们可以思考一下,这两层循环可以怎么去优化它呢?
说到mysql的优化,我们的第一个念头肯定就是加索引。没错,我们可以通过减少循环次数来达到优化的效果。例如被驱动表t2中的字段加了索引,而这个字段刚好就是驱动表t1中遍历的那个字段,那岂不是美滋滋?直接拿这个字段的值去被驱动表t2中取值不就得了。下面这个算法就是根据索引进行的优化
索引嵌套循环连接
如果上面的解释还不是十分明白,我们可以通过伪代码来理解
//假如有两个表,主表main和从表second,主键均是id且second表的main_id加了索引
select m.* from main m
inner join second s on s.main_id = m.id执行上面这条查询语句时的取值代码类似下面
for(M id : main){
if(second.contains(id)){
//添加到结果集
}
}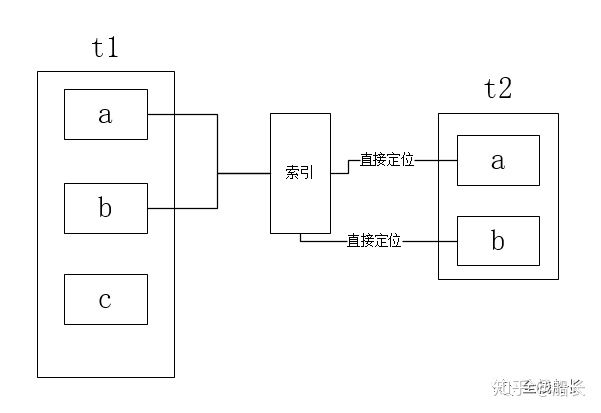
从代码层面来看,我们马上就能感受到循环次数的量级变化,但是其实拿id去匹配被驱动表second时,还是会有一个回表的操作,降低了效率。
各位猿友可能又会问,什么又是回表?
这涉及到索引的底层原理了,但是上了我这条船的人,船长我一定会给他讲得明明白白。
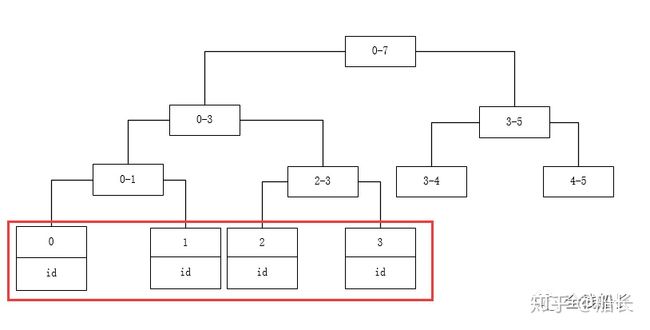
比如有个表的状态列state添加了索引,并存储了0、1、2、3、4、5、6、7共8个元素,那么它的索引就是下面的B+树结构,其中最下面的叶子节点存储的才是真正的元素,而叶子节点除了存储索引列本身的值外,还会存储这行记录的id,那么我们又需要拿着这个id值从主键id的索引树中找到这行记录的所有元素,这个过程就称为回表查询。
可见回表查询降低了查询效率
块嵌套循环连接
如果join后面的条件不是索引列表怎么办呢?使用简单嵌套循环连接是不可能的,这辈子都不可能的了
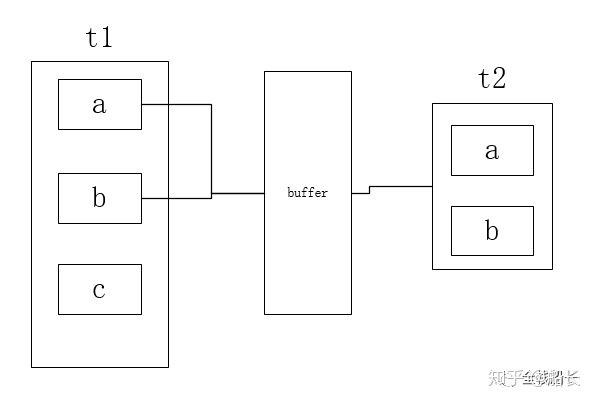
mysql使用了一个叫join buffer的缓冲区去减少循环次数,这个缓冲区默认是256KB,可以通过命令show variables like 'join_%'查看
其具体的做法是,将驱动表t1中符合条件的列一次性查询到缓冲区中,然后遍历一次被驱动表t2,并逐一和缓冲区的所有值比较,将比较结果加入结果集中
这里直接用文字描述可能有点晦涩难懂,那还是举一个例子,大家肯定立马就懂了
假设t1表中有100行记录,t2表中有50行记录,而块嵌套循环算法会每次读取t1表中的10条记
录,并加入到缓冲区buffer中。然后遍历一次t2表,对于t2表中的每行记录,都会与与buffer
中的10条记录进行比较,并将相等的加入结果集。如此一来,循环次数变为10*50=500次
扫描下方二维码 关注全栈船长
