论文阅读(7):VarGFaceNet: An Efficient Variable Group Convolutional Neural Network for Lightweight FR

论文链接: VarGFaceNet: An Efficient Variable Group Convolution Neural Network for Lightweight Face Recognition
代码链接:GitHub/zma-c-137/VarGFaceNet
一、问题与挑战
-
人脸识别被广泛应用于监控、商场以及生物领域,但时由于大量的identity需要被分类,在计算成本有限的移动设备或嵌入式系统上实现人脸识别仍然具有挑战性。
-
现有的轻量级网络如SqueezeNet, MobileMet, MobileNetV2, ShuffleNet等虽然运用了少量的计算量并达到很好的效果,但在嵌入式硬件和相应编译器上的嵌入式系统的优化问题仍然存在。
-
针对以上方法,地平线曾在2019年提出一个使用与一般计算机视觉任务的轻量级网络VarGNet(论文链接),有效解决块内计算强度不平衡的问题。 但是VarGNet的一些内部设计不适用于人脸识别任务。
二、本文提出
本文在VarGNet的基础上进行修改,提出了一个用于轻量级人脸识别任务的网络VarGFaceNet。主要修改的几个方面有:
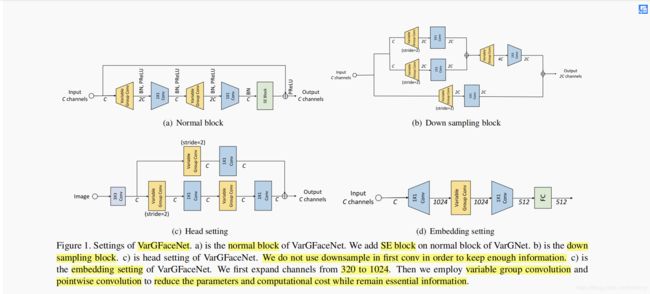
- 为了提高VarGNet用于轻量级人脸识别上的判别能力,在VarGNet blocks内加入了SE block 和 PReLU。并在网络开始位置删掉了downsample,为人脸图像保留更多信息。
- 为了减少网络的参数,本文在最后的FC layer之前加入Variable Group Convolution,将特征图缩到 1 ∗ 1 ∗ 512 1*1*512 1∗1∗512 的大小.
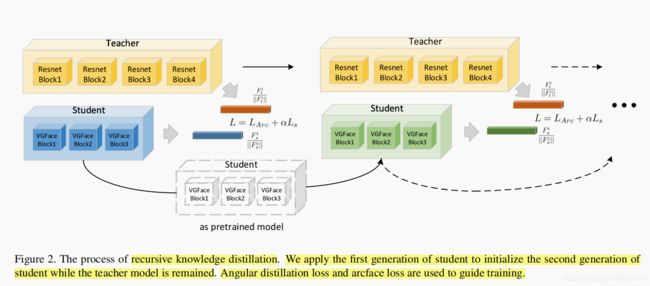
- 为了提高轻量级网络的解释能力(这里指网络提取图像特征的能力),本文在网络训练时运用了只是蒸馏来指引VarGFaceNet的学习。本文应用了 Angular Distillation Loss 的等效形式来作为student网络的指引,并提出 Recursive Knowledge Distillation 将当前训练好的模型作为下一代的预训练模型。
论文 / 参考博客链接:
SE block 参考博客:SENet(Squeeze-and-Excitation Networks)算法笔记
PeReLU 参考博客:PReLU激活函数 - 简书
Variable Group Convolution(VarGNet) 论文链接: VarGNet: Variable Group Convolutional Neural Network for Efficient Embedded Computing
Angular Dstillation Loss 论文链接:ShrinkTeaNet: Million-scale Lightweight Face Recognition via Shrinking Teacher-Student Networks
三、方法
1. Variable Group Convolution
常规卷积: 卷积参数量:C * H * W * N

Seperable Convolution: 卷积参数量:C * H * W * N


参考博客1:Group Convolution分组卷积,以及Depthwise Convolution和Global Depthwise Convolution
参考博客2:卷积神经网络中的Separable Convolution
问题: MobileNetV1/V2提出的depthwise separable convolution 95%的计算量都在1 * 1 Conv上,在两个连续层之间存在很大的 MAdds gap(即 1 * 1 Conv 和 3 * 3 Conv 之间)。
提出: 为了平衡好一个block内的计算强度,VarGNet 提出的将群卷积中每组的通道数设为常量S,固定不变。则组数G根据输入feature map的通道数而变化,即 G = C/S 。计算量为:

其后的pointwise convolution计算量则为:
 可变群卷积与pointwise convolution的计算量比例,比seperable convolution的计算量比例要大,因此可变群卷积更能达到块内的计算平衡。
可变群卷积与pointwise convolution的计算量比例,比seperable convolution的计算量比例要大,因此可变群卷积更能达到块内的计算平衡。
2. Lightweight Network for Face Recognition
前面提到 VarGNet 的某些结构设置不适用于大规模人脸识别,因此分别在 VarGNet 的head, embedding 部分了一些修改。
(1)head setting : 用 3 * 3 Conv with stride = 1 代替 3 * 3 Conv with stride = 2,保留更多人脸信息
(2)embedding setting : 为减少最后FC layer的参数以设计一个轻量级网络,在最后FC layer前面增加可变群卷积,减少参数的同时避免信息的丢失。做法是:
1)用 1 * 1 Conv 将通道从320扩增到1024, 避免减少参数量而导致的重要信息丢失;
2)用 7 * 7 Conv 的可变群卷积(S = 8)将特征张量从 7 * 7 * 1024 压缩到 1 * 1 * 1024;
3)用 pointwise convolution 来连接上述的通道,并输出 1 * 1 * 512 大小的特征张量,最后输入FC layer.
说明: 经过embedding setting,该block仅占5.78M内存,而原始的FC layer占30M内存(7 * 7 * 320 * 512)
VarGFaceNet 结构图
VarGFaceNet 整体结构表

3. Angular Distillation Loss
论文链接:ShrinkTeaNet: Million-scale Lightweight Face
Recognition via Shrinking Teacher-Student Networks
参考博客: 【distillation】shrinkTeaNet:Million-scale Lightweight Face Recognition via Shrinking T-S Networks
知识蒸馏 常被用为轻量级网络训练的方法,它可以将复杂网络(Teacher)的解释能力迁移到轻量级网络(Student)中。SOTA知识蒸馏方法都是用Tea Net的预测分数/预测概率,或者嵌入/特征来计算L2距离或者交叉熵损失来作为Loss。
对于开集任务来说,由于测试集中的类别在训练集中未出现过,训练集的score/logit不能为测试阶段提供有用的信息,而且计算teacher和student特征间的L2距离作为损失,要求二者提取的特征进行精确匹配(exact match),在某种情况下会使student net 过正则化。
因此,ShrinkTeaNet提出了Angular Distillation Loss,将Teacher 特征的方向作为知识蒸馏,通过让student与teacher的特征方向相近,使student学习到teacher超球面上的样本分布,即样本与所属类别的角度小,不同类别间的角度间隔大。公式如下:
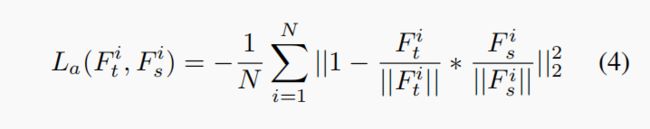
VarGFaceNet采取的是上式的等效形式:

另外应用ArcFace Loss作为类别损失,同样也是关注于角度信息:

因此,总的目标函数是上述两个公式之和:

4. Recursive Knowledgr Distillation
如果teacher和student模型存在较大的差异,仅一次的知识蒸馏可能不足以迁移足够的知识到student modal中。为了提高本文student modal的判别性能力和泛化能力,本文使用递归知识蒸馏,用第一代的student modal来初始化第二代的student modal。有两个好处:
(1)好的初始化可使student更容易接近teacher的的指引方向;
(2)分类损失和作为指导的指引的角度信息之间的冲突能在第二代中得到缓和。
递归知识蒸馏结框架图
四、实验
-
数据集和评价方法
训练集:MS1M dataset
测试集:Trillion Pairs dataset, LFW, CFP-FP, AgeDB-30
人脸检测方法:RetinaFace -
VarGFaceNet trained from scratch

-
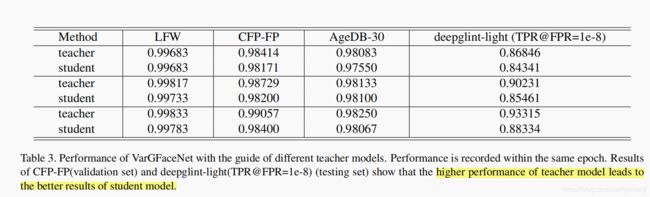
VarGFaceNet guided by ResNet-100

-
Recursive Knowledge Distillation

五、总结
- 本文针对轻量级人脸识别提出了VarGFaceNet网络,在效率与性能上达到一个平衡
- 为提高轻量级网络的解释能力,应用Angular Distillation Loss,作为知识蒸馏的目标函数,并提出Recursive Knowledge Distillation,提高轻量级网络的泛化能力。