2.5 线性回归的问题
在本章,我们已经看到了在尝试构建线性回归模型的时候遇到某些问题的一些示例。我们讨论过的一大类问题是和模型在线性、特征独立性和同方差性及误差的正态性等方面的假设相关的。我们还具体看到了诊断这类问题的方法,要么借助像残差图这样的图,或者利用能识别非独立成分的函数。本节要探讨线性回归中可能出现的一些其他问题。
2.5.1 多重共线性
作为预处理步骤的一部分,我们会尽力去除相互线性相关的特征。在此过程中,我们寻找的是一种完全的线性关系,这就是完全共线性(perfect collinearity)的示例。共线性(collinearity)是描述两个特征近似具有一种线性关系的性质。这对于线性回归会产生一个问题,因为我们会尝试给相互之间接近是线性函数的变量分配独立的系数。这样会导致的情况是:两个高度共线性的特征具有较大的p值表明它们和输出变量不相关,但如果去除其中一个特征并重新训练该模型,剩下的那个特征就会具有较小的p值。共线性的另一种典型迹象是某个系数出现不正常的符号,例如在一个预测收入水平的线性模型里,教育背景的系数为负。两个特征之间的共线性可以通过配对相关系数进行检测。处理共线性的一种方式是把两个特征合并为一个(例如通过取平均值);另一种方式是直接去除其中一个特征。
多重共线性(multicollinearity)出现在线性关系涉及多于两个特征的情况。检测它的一种标准方法是对线性模型中的每个输入特征计算其方差膨胀因子(variance inflation factor,VIF)。简而言之,VIF可以用来估计由于该特征和其他特征共线性而直接导致在具体系数的估计过程中能观察到的方差的增量。这通常是通过拟合一个线性回归模型来进行的,我们把其中的一个特征作为输出特征,把其他特征仍保留为常规的输入特征。然后我们对这个线性模型计算统计量,并据此利用公式计算我们选取的那个特征的VIF。在R语言中,car包包含了vif()函数,它能方便地对一个线性回归模型中的所有特征计算VIF值。这里有一个经验规则是,VIF分数为4或更大的特征就是可疑的,而分数大于10就表明了多重共线性的极大可能性。既然看到了二手车数据中存在必须去除的线性依赖特征,就让我们来调查在余下的特征中是否存在多重共线性:
library(car)
vif(cars_model2)

这里有3个值略大于4,但没有更大的了。作为一个示例,如下的代码演示了sedan特征的VIF值是如何计算的:
sedan_model <- lm(sedan ~ .-Price -Saturn, data = cars_train)
sedan_r2 <- compute_rsquared(sedan_model$fitted.values, cars_train$sedan)
1 / (1 - sedan_r2)
[1] 4.550556
2.5.2 离群值
当观察我们的两个模型的残差时,我们会看到有某些观测数据比其他数据具有明显更大的残差。例如,根据CPU模型的残差图,我们可以看到观测数据200有非常大的残差。这就是一个离群值(outlier)的示例,它是一种预测值距离其实际值非常远的观测数据。由于对残差取平方的原因,离群值对RSS往往会产生显著的影响,给我们带来模型拟合效果不佳的印象。离群值可能是因为测量误差产生的,对它们的检测很重要,因为它们可能预示着不准确或非法的数据。另一方面,离群值也可能只是没有选对特征或创建了错误种类的模型的结果。
因为我们通常并不知道某个离群值是一个数据收集过程中的错误数据还是真实的观测数据,处理离群值会非常棘手。有时候,尤其是当我们有很少的离群值时,一种常见的手段是去除它们,因为包括它们往往会产生显著改变预测模型系数的效果。我们要说,离群值经常是具有较高影响(influence)的点。
离群值并不是具有高影响的唯一观测数据。高杠杆率点(high leverage point)也是这样的观测数据,在它们的特征中至少有一个具有极端值,因而远离大部分其他观测数据。cook距离(cook's distance)是一个结合了离群值和高杠杆率的概念来识别对数据具有高影响的那些点的典型衡量指标。要更深入地探索线性回归的诊断方法,有一个很好的参考书是John Fox编写的《An R Companion to Applied Regression》,由Sage Publications出版。
为了展示去除一个离群值的效果,我们要通过利用去掉观测数据 200 的训练数据创建一个新的CPU模型。然后,观察新模型是否在训练数据上有所改善。这里,我们会显示所采取的步骤和只有最后三行的模型摘要片段:
machine_model2 <- lm(PRP ~ ., data = machine_train[!rownames(machine_train) %in% c(200), ])
summary(machine_model2)

正如从减小的RSE和调整后的统计量看到的,我们在训练数据上得到了更好的拟合。当然,模型精确度的实际衡量还要看它在测试数据上的表现,我们也无法保证把观测数据200标记为虚假离群值的决定一定是正确的。
machine_model2_predictions <- predict(machine_model2, machine_test)
compute_mse(machine_model2_predictions, machine_test$PRP)
[1] 2555.355
我们得到了一个比以前更小的测试MSE,这往往是表明我们作出了正确选择的一个良好迹象。这里要再说一遍,因为测试集比较小,所以我们也无法肯定这个事实,尽管从MSE迹象来看是正面的。
2.6 特征选择
我们的CPU模型只有6个特征。通常,我们遇到实际环境的数据集会具有来自多种不同观测数据的非常大量的特征。另外,我们会在不太确定哪些特征在影响输出变量方面比较重要的情况下,不得不采用大量的特征。除此之外,我们还有会遇到可能要分很多水平的分类变量,对它们我们只能创建大量的新指示变量,正如在第1章里所看到的那样。当面对的场景涉及大量特征时,我们经常会发现输出只依赖于它们的一个子集。给定k个输入特征,可以形成2k个不同的子集,因此即使对于中等数量的特征,子集的空间也会大到无法通过逐个子集的拟合来进行完整的探索。
要理解为什么可能的特征子集会有个,一种简单的方式是这样的:我们可以给每个子集分配一个独立的识别码,这个识别码是k位的二进制数字构成的字符串,如果我们选择在该子集中包含第i个特征(特征可以任意排序),那么第i个位上的数字就是1。例如,如果我们有三个特征,字符串101就对应了只包括第一个和第三个特征的子集。在这种方式下,我们构建了所有可能的二进制字符串,它从由k个0构成的字符串一直排到由k个1构成的字符串,因此我们就得到了从0到的所有整数,也就是总计个子集。
特征选择(feature selection)指在模型中选择一个特征子集以构成一个带有更少特征的新模型的过程。它会去除我们认为和输出变量无关的特征,因而产生一个更易于训练和解释的更简单模型。有很多方法被设计用来进行这项任务,它们一般不会用穷举的方式去搜遍可能的子集空间,而是在该空间进行引导式搜索(guided search)。
这类方法之一是前向选择(forward selection),它是通过一系列步骤进行特征选择的逐步回归(stepwise regression)的一个范例。对于前向选择,它的思路是从一个没有选择特征的空模型起步,接着进行k次(针对每个特征进行一次)简单线性回归并从中选取最好的一个。这里比较的是有相同特征数量的模型,因此可以使用统计量来指导我们的选择,虽然我们也可以使用AIC之类的衡量指标。一旦选择了要加入的第一个特征,我们就可以从余下的k-1个特征中选取要加入的另一个特征。因此,现在我们可以针对每个可能的特征配对进行k-1次多元回归,配对中的其中一个特征是在第一步选择的那个特征。我们可以继续按这种方式增加特征,直到我们评价了包含所有特征的模型并结束这个过程。注意,在每一个步骤里,我们都为所有后续的步骤作出了把哪个特征包含进来的艰难选择。例如,在多于一个特征的模型当中,没有包含我们在第一步选择的那个特征的那些模型就永远不需要考虑了。因此,我们并不是穷举式地搜索我们的空间。实际上,如果考虑到我们还评估了空模型,我们就可以计算进行了线性回归的模型总数为:
这个计算结果的数量级是在的量级上,即使对于比较小的k值而言,也已经明显比小多了。在前向选择过程的最后阶段,我们必须从对应每个步骤结束时得到的子集所构成的k+1个模型中进行选择。由于过程的这个最终部分要比较带有不同数量特征的模型,我们通常会使用诸如AIC的准则或调整后的R2来作出模型的最终选择。对于CPU数据集,可以通过运行下列命令来演示这个过程:
machine_model3 <- step(machine_model_null,
scope = list(lower = machine_model_null,upper = machine_model1),
direction = 'forward')
step()函数实现了前向选择的过程。我们首先给它提供了通过在训练数据上拟合无特征的线性模型而得到的空模型。对于scope参数,我们指定的是要求算法从空模型开始一直逐步处理到包含所有6个特征的完整模型。在R语言里发出这条命令会产生一个输出,它会显示迭代每一步指定了哪个特征子集。为了节省空间,我们在下表呈现这个结果以及每个模型的AIC值。注意,AIC值越小,模型就越好。
| 步骤 | 子集里含有的特征 | AIC值 |
|---|---|---|
| 0 | { } | 1839.13 |
| 1 | {MMAX} | 1583.38 |
| 2 | {MMAX, CACH} | 1547.21 |
| 3 | {MMAX, CACH, MMIN} | 1522.06 |
| 4 | {MMAX, CACH, MMIN, CHMAX} | 1484.14 |
| 5 | {MMAX, CACH, MMIN, CHMAX, MYCT} | 1478.36 |
step()函数对前向选择采用了一种替代性的规格,它会在任何一个剩余的特征加入当前特征子集都无法改善总体评分的情况下终止。对于数据集而言,只有一个特征会从最终模型中排除,因为把它加入进来并没有提高总体评分。既有趣又令人放心的是,这个被排除的特征就是CHMIN,它也是唯一具有相对较高p值的变量,说明在有其他特征存在的情况下我们无法确信输出变量和这个特征是相关的。
有人可能会想知道是否可以从相反方向进行变量选择,也就是从一个完整的模型开始,根据去除哪个特征会给模型评分带来最大的改善来逐个去除特征。这样实际上是可以的,这样的过程被称为后向选择(backward selection)或后向淘汰(backward elimination)。在R语言里的做法是利用step()函数,指定direction参数为backward并从完整模型开始。可以用二手车数据集来演示这个过程,并把结果保存到一个新的二手车模型里:
cars_model_null <- lm(Price ~ 1, data = cars_train)
cars_model3 <- step(cars_model2,
scope = list(lower = cars_model_null, upper = cars_model2),
direction = 'backward')
[out] Start: AIC=1839.13
PRP ~ 1
Df Sum of Sq RSS AIC
+ MMAX 1 3914840 1215559 1583.4
+ MMIN 1 3342632 1787766 1652.4
+ CACH 1 2188545 2941854 1741.6
+ CHMIN 1 2149395 2981003 1744.0
+ CHMAX 1 1870998 3259401 1759.9
+ MYCT 1 488950 4641448 1823.2
5130399 1839.1
Step: AIC=1583.38
PRP ~ MMAX
Df Sum of Sq RSS AIC
+ CACH 1 233408 982151 1547.2
+ MMIN 1 232513 983046 1547.4
+ CHMAX 1 148938 1066621 1562.0
+ CHMIN 1 136138 1079420 1564.1
1215559 1583.4
+ MYCT 1 3819 1211740 1584.8
Step: AIC=1547.21
PRP ~ MMAX + CACH
Df Sum of Sq RSS AIC
+ MMIN 1 138216 843935 1522.1
+ CHMAX 1 71519 910631 1535.7
+ CHMIN 1 38724 943427 1542.0
+ MYCT 1 18056 964094 1545.9
982151 1547.2
Step: AIC=1522.06
PRP ~ MMAX + CACH + MMIN
Df Sum of Sq RSS AIC
+ CHMAX 1 168689 675246 1484.1
+ MYCT 1 21984 821951 1519.3
+ CHMIN 1 13407 830528 1521.2
843935 1522.1
Step: AIC=1484.14
PRP ~ MMAX + CACH + MMIN + CHMAX
Df Sum of Sq RSS AIC
+ MYCT 1 28745.9 646500 1478.4
675246 1484.1
+ CHMIN 1 54.6 675191 1486.1
Step: AIC=1478.36
PRP ~ MMAX + CACH + MMIN + CHMAX + MYCT
Df Sum of Sq RSS AIC
646500 1478.4
+ CHMIN 1 20.335 646479 1480.3
在二手车数据集上得到的最终线性回归模型的公式如下:
cars_model3$call
[out] lm(formula = Price ~ Mileage + Cylinder + Doors + Leather + Buick +
Cadillac + Pontiac + Saab + convertible + hatchback + sedan,
data = cars_train)
正如我们所见,最终的模型丢弃了Cruise、Sound和Chevy特征。观察我们之前的模型摘要,我们可以看到,这三个特征都具有较高的p值。前面的两种方法是一种贪心算法(greedy algorithm)的示例。这也就是说,一旦作出了是否包含某个变量的选择,它就是最终决定,之后也不能撤销了。为了对它进行弥补,就有了第三种变量选择的方法,它称为混合选择(mixed selection)或双向淘汰(bidirectional elimination),它一开始会表现为前向选择方法,采用的是增加变量的前向步骤,但是在能够改善AIC的情况下也可以包含后向的步骤。不出所料,step()函数在direction参数被指定为both时就是这样做的。
既然有了两个新模型,我们就可以观察它们在测试集上的表现:
machine_model3_predictions <- predict(machine_model3, machine_test)
compute_mse(machine_model3_predictions, machine_test$PRP)
cars_model3_predictions <- predict(cars_model3, cars_test)
compute_mse(cars_model3_predictions, cars_test$Price)

对于CPU模型,我们在测试数据集上的表现比初始模型略有改善。合适的下一步的工作可以是探索这个缩减后的特征集是否和去除离群值配合起来效果更好,这个问题留给读者作为练习。相比之下,对于二手车模型,作为去除所有这些特征的结果,我们看到测试MSE略有增加。
2.7 正则化
变量选择是一个重要的过程,因为它试图通过去除与输出无关的变量,让模型解释更简单、训练更容易,并且没有虚假的关联。这是处理过拟合问题的一种可能的方法。总体而言,我们并不期望一个模型能完全拟合训练数据。实际上,过拟合问题通常意味着,如果过分拟合训练数据,对我们在未知数据上的预测模型精确度反而是有害的。在关于正则化(regularization)的这一节,我们要学习一种减少变量数以处理过拟合的替代方法。正则化实质上是在训练程序中引入刻意的偏误或约束条件,以此防止系数取值过大的一个过程。因为这是一个尝试缩小系数的过程,所以我们要观察的这种方法也称为收缩方法(shrinkage method)。
2.7.1 岭回归
当参数的数量非常大的时候,尤其是和能获得的观测数据的数量相比很大时,线性回归往往会表现出非常高的方差。这也就是说,在一些观测数据中的微小变化会导致系数的显著变化。岭回归(ridge regression)是一种通过其约束条件引入偏误但能有效地减小模型的方差的方法。岭回归试图把残差平方和(RSS)加上系数的平方和乘以一个用希腊字母表示的常数构成的项()的累加和最小化。对于一个带有k个参数的模型(不包括常数项0)以及带有n条观测数据的数据集,岭回归会使下列数量最小化:
在这里,我们还是想把RSS最小化,但第二个项是惩罚项,当任何系数很大时它也会很大。因此,在最小化的时候,我们就会有效地把系数压缩到更小的值。参数被称为元参数(meta parameter),它是我们需要选择或调优的。一个非常大的值会掩盖RSS项并把系数压缩到0。过小的值对于过拟合就没什么效果,而一个等于0的参数则只是进行普通的线性回归。
当进行岭回归时,经常需要通过把所有特征值除以它们的方差来进行比例缩放。这对于普通线性回归不适用,因为如果某个特征用一个等于10的因子进行缩放,那么系数也会被一个等于1/10的因子进行缩放来补偿。在岭回归里,特征的缩放则是通过惩罚项来影响所有其他特征的计算的。
2.7.2 最小绝对值收缩和选择算子
最小绝对值收缩和选择算子(lasso)是岭回归的一种替代正则化方法。它们之间的差别只是体现在惩罚项里,它最小化的是系数的绝对值之和。
其实,惩罚项里的这个差别是非常显著的,由于lasso会把某些系数完全收缩到0,所以它兼具了收缩和选择的功能,而这对于岭回归是不具备的。即便如此,在这两种模型之间并没有明确的赢家。依赖于输入特征的某个子集的模型往往用lasso表现更好;很多不同变量的系数具有较大分散度的模型则往往在岭回归下有更好的表现。两者通常都是值得尝试的。
岭回归里的惩罚项经常被称为惩罚项,而lasso里的惩罚项被称为惩罚项。这是来自向量的范数(norm)的数学概念。向量的范数是一个函数,它会给该向量分配一个代表其长度或大小的正数。l1和l2范数都是一类被称为p范数(p-norm)的范数中的范例,对于具有n个分量的向量v,p范数具有下面的一般形式:
原著貌似有错,原著中此处公式为
2.7.3 在R语言里实现正则化
有很多不同的函数和扩展包都实现了岭回归,例如MASS包里的lm.ridge()函数和genridge包里的ridge()函数。对于lasso来说,也有lars包可用。在本章,我们会采用来自glmnet包的glmnet()函数,这是因为它具有一致且友好的接口。正则化处理的关键是确定采用一个适当的值。glmnet()函数采用的方法是利用一组不同的值,并针对每个值训练一个回归模型。然后,你既可以手工挑出一个值,也可以利用某个技术来估算最佳的值。我们可以通过lambda参数指定要尝试的值序列;否则,函数会采用默认的100个值的序列。给glmnet()函数的第一个参数必须是一个特征矩阵,它可以利用model.matrix()函数来构建。
第二个参数是一个带有输出变量的向量。最后,alpha参数是岭回归(参数取值为0)和lasso(参数取值为1)之间的切换开关。我们现在准备用二手车数据集来训练一些模型:
library(glmnet)
cars_train_mat <- model.matrix(Price ~ . - Saturn, cars_train)[, -1]
lambdas <- 10 ^ seq(8, -4, length = 250)
cars_models_ridge <- glmnet(cars_train_mat, cars_train$Price, alpha = 0, lambda = lambdas)
cars_models_lasso <- glmnet(cars_train_mat, cars_train$Price, alpha = 1, lambda = lambdas)
因为提供了250个值的序列,所以我们实际上训练了250个岭回归模型和另外250个lasso模型。可以对第100个模型来查看glmnet()函数产生的对象的lambda属性里的值,并对该对象调用coef()函数来获得对应的系数,如下所示:
cars_models_ridge$lambda[100]
coef(cars_models_ridge)[, 100]

也可以调用plot()函数来获得一个绘图,显示系数的值是如何随着值的对数变化而变化的。把岭回归和 lasso 的对应绘图并排显示是非常有帮助的:
layout(matrix(c(1, 2), 1, 2))
plot(cars_models_ridge, xvar = 'lambda', main = 'Ridge Regression\n')
plot(cars_models_lasso, xvar = 'lambda', main = 'Lasso Regression\n')

这两幅图的关键差异在于,lasso会强制把很多系数减小到正好为0,而在岭回归里,系数往往是平滑地减小,只有当取极端值时才会全部一起变为0。这个规律可以进一步从两幅图的上部水平轴上的数值看出来,它显示的是当取不同值时非零系数的个数。从这个意义上说,lasso在两个方面具有明显优势:它经常可以用来进行特征选择(因为系数为0的特征实际上是不包含在模型中的),以及为了把过拟合问题最小化而进行正则化。我们可以通过改变赋予xvar参数的值来获得其他有用的绘图。它取值为norm时会在x轴绘制系数的l1范数,取值为dev时则会绘制该模型所解释的偏差(deviance)的百分比。我们会在下一章学习有关偏差的内容。
为了处理给找到一个合适值的问题,glmnet包提供了cv.glmnet()函数。它对训练数据运用了一种称为交叉验证(cross-validation)的技术(我们会在第5章中学习到它),从而找到能够最小化均方差(MSE)的合适的值。
ridge.cv <- cv.glmnet(cars_train_mat, cars_train$Price, alpha = 0)
lambda_ridge <- ridge.cv$lambda.min
lasso.cv <- cv.glmnet(cars_train_mat, cars_train$Price, alpha = 1)
lambda.lasso <- lasso.cv$lambda.min
lambda_ridge
lambda.lasso
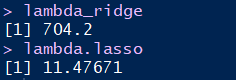
如果我们绘制cv.glmnet()函数产生的结果,可以看到MSE是如何随着的不同取值而变化的:
plot.cv.glmnet(ridge.cv, main = '岭回归\n')
plot.cv.glmnet(lasso.cv, main = 'Lasso\n')

每个点上下的竖条是为每个的绘制值而显示的MSE估计值上下的标准差的误差条。绘图还显示了两条垂直的虚线。第一条垂直线对应的是lambda.min的值,它是交叉验证提出的优化值。右侧的第二条垂直线是lambda.1se属性的值。它对应了距离lambda. min一个标准误(standard error)的值,并产生了一个更为正则化的模型。
在glmnet包里也有一个predict()函数,它现在可以在多种不同的背景下执行。例如,可以针对某个不在原始清单里的值求得模型的系数。例如,进行如下操作:
predict(cars_models_lasso, type = 'coefficients', s = lambda.lasso)
[out] 15 x 1 sparse Matrix of class "dgCMatrix"
1
(Intercept) -480.5213264
Mileage -0.1860034
Cylinder 3617.3014597
Doors 1386.5497734
Cruise 309.2066613
Sound 336.2299484
Leather 828.8331974
Buick 1142.5951628
Cadillac 13384.9977234
Chevy -497.3176664
Pontiac -1316.6902766
Saab 12315.4833247
convertible 11150.3382165
hatchback -6043.4365872
sedan -4155.2443470
注意,貌似lasso在这个示例中并没有把任何系数强制为0,这说明根据MSE的情况,不建议去除二手车数据集里的任何系数。最后,我们可以再次调用predict()函数,通过newx参数为要进行预测的观测数据提供一个特征矩阵,从而用一个正则化的模型来作出预测:
cars_test_mat <- model.matrix(Price~.-Saturn, cars_test)[, -1]
cars_ridge_predictions <- predict(cars_models_ridge, s = lambda_ridge, newx = cars_test_mat)
compute_mse(cars_ridge_predictions, cars_test$Price)
cars_lasso_predictions <- predict(cars_models_lasso, s = lambda.lasso, newx = cars_test_mat)
compute_mse(cars_lasso_predictions, cars_test$Price)
> compute_mse(cars_ridge_predictions, cars_test$Price)
[1] 7672071
> compute_mse(cars_lasso_predictions, cars_test$Price)
[1] 7173818
在测试数据上,lasso模型的效果最好,且略好于普通模型,而不像岭回归在这个示例中的表现那么不理想。
2.8 小结
在本章,我们学习了线性回归,这是一种让我们能在有监督学习环境下拟合线性模型的方法,在这种环境下,我们有一些输入特征和一个数值型的输出。简单线性回归是对只有一个输入特征的情况的命名,而多元线性回归则描述了具有多个输入特征的情况。线性回归是解决回归问题很常用的第一步骤。它假定输出是输入特征的线性加权组合,再加上一个无法化简、符合正态分布、具有0均值和常数方差的误差项。这种模型也假设特征是相互独立的。线性回归的性能可以通过一组不同的衡量指标来进行评价,从更标准的MSE到诸如R2 统计量等其他指标。我们探讨了几种模型诊断和显著性检验方法,它们用于检测从不成立的假设到离群值等问题。最后,我们还讨论了如何用逐步回归进行特征选择,以及利用岭回归和lasso进行正则化。
线性回归模型具有多种优势,包括快速和开销小的参数计算过程,以及易于解释和推断的模型,这是因为它具有形式简单的优点。有很多检验方法可以用来诊断关于模型拟合的问题,并对系数的显著性进行假设检验。总体来说,可以认为它是低方差的一种方法,因为它对于数据中的小误差比较健壮(robust)。就其不足之处而言,因为它作出了非常严格的假设,尤其是输出函数在模型参数里必须是线性的,所以它就会引入很高程度的偏误,对于比较复杂或高度非线性的一般函数,这种方法往往就表现不佳。此外,我们也看到了,当输入特征数量变得很多时,我们就不能依赖于系数的显著性检验。当我们在一个高维特征空间里工作时,这个事实再加上特征之间的独立性假设,就会使线性回归成为相对较差的一种选择。