Python 绘制全球 2019-nCoV 地图

国内 2019-nCoV 得到控制后,我就没怎么再关心过 2019-nCoV ,最近看到一条新闻,全球 2019-nCoV 累计确诊人数已经突破 500w 大关,看到这个数字我还是有点吃惊的。
思来想去,还是写一篇全球 2019-nCoV 的分析的文章,本文包括网络爬虫、全球 2019-nCoV 地图绘制等方面。
网络爬虫
我之前有分享过 2019-nCoV 数据的来源,用的是 AKShare 的数据源,好用是真好用,就是网络太慢了, AKShare 的数据很多是来源于 GitHub ,我的网络访问太平洋彼岸的数据还是有点力不从心。
这次我换了新的数据源,来源腾讯新闻的实时数据,站点链接如下:
- 腾讯新闻:https://news.qq.com/zt2020/page/feiyan.htm
本来我以为需要解析页面元素,才能获取到数据,但是等我分析了 network 以后发现,竟然可以直接找到数据接口,这大大的方便了我们数据抓取。
获取全球 2019-nCoV 数据接口如下:
https://api.inews.qq.com/newsqa/v1/automation/foreign/country/ranklist
把这个接口放在 PostMan 里面模拟访问一下:
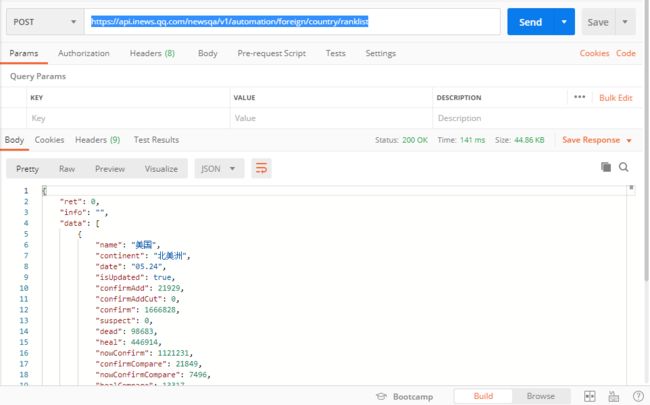
毫无反爬手段,header 神马的都不需要配置,直接访问就能拿到数据,到这里,我们可以开始写爬虫的代码了,最终代码如下:
import requests
from datetime import datetime
def catch_data():
"""
抓取当前实时数据,并返回 国家、大洲、确诊、疑似、死亡、治愈 列表
:return:
"""
url = 'https://api.inews.qq.com/newsqa/v1/automation/foreign/country/ranklist'
data = requests.post(url).json()['data']
date_list = list() # 日期
name_list = list() # 国家
continent_list = list() # 大洲
confirm_list = list() # 确诊
suspect_list = list() # 疑似
dead_list = list() # 死亡
heal_list = list() # 治愈
for item in data:
month, day = item['date'].split('.')
date_list.append(datetime.strptime('2020-%s-%s' % (month, day), '%Y-%m-%d'))
name_list.append(item['name'])
continent_list.append(item['continent'])
confirm_list.append(int(item['confirm']))
suspect_list.append(int(item['suspect']))
dead_list.append(int(item['dead']))
heal_list.append(int(item['heal']))
return date_list, name_list, continent_list, confirm_list, suspect_list, dead_list, heal_list
def save_csv():
"""
将数据存入 csv 文件
:return:
"""
date_list, name_list, continent_list, confirm_list, suspect_list, dead_list, heal_list = catch_data()
fw = open('2019-nCoV.csv', 'w', encoding='utf-8')
fw.write('date,name,continent,confirm,suspect,dead,heal\n')
i = 0
while i < len(date_list):
date = str(date_list[i].strftime("%Y-%m-%d"))
fw.write(date + ',' + str(name_list[i]) + ',' + str(continent_list[i]) + ',' + str(confirm_list[i]) + ',' + str(suspect_list[i]) + ',' + str(dead_list[i]) + ',' + str(heal_list[i]) + '\n')
i = i + 1
else:
print("csv 写入完成")
fw.close()
if __name__ == '__main__':
save_csv()
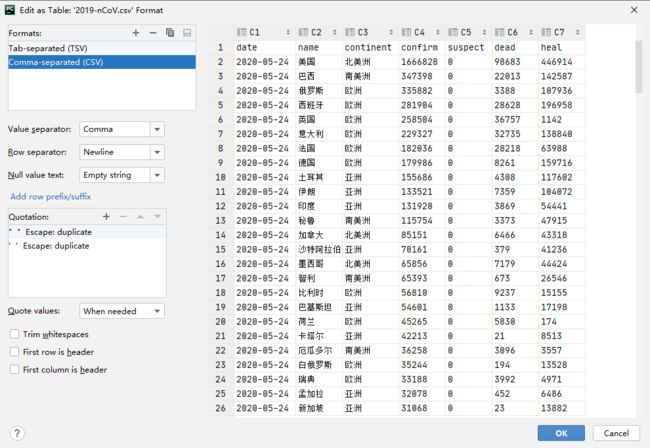
最终得到的 csv 文件是这样的:
全球 2019-nCoV 地图
前端或网站开发的朋友应该都使用过强大的 Echarts 插件。 ECharts 是一个纯 Javascript 的图表库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器,底层依赖轻量级的 Canvas 类库 ZRender ,提供直观、生动、可交互、可高度个性化定制的数据可视化图表。 ECharts 提供了常规的折线图、柱状图、散点图、饼图、K线图,用于统计的盒形图,用于地理数据可视化的地图、热力图、线图,用于关系数据可视化的关系图、treemap,多维数据可视化的平行坐标,还有用于 BI 的漏斗图、仪表盘,并且支持图与图之间的混搭。
既然 Echarts 如此强大, Python 肯定有相应的第三方扩展包支持,它就是我们接下来绘制世界地图要用到的 PyEcharts 。 PyEcharts 是一个用于生成 Echarts 图表的类库,即 Echarts 与 Python 的对接。
安装语句如下:
pip install pyecharts
PyEcharts 安装完成后我们就可以开始写接下来的代码了,如下:
from pyecharts import options as opts
from pyecharts.charts import Map
import pandas as pd
import namemap
def read_country_code():
"""
获取国家中英文字典
:return:
"""
country_dict = {}
for key, val in namemap.nameMap.items(): # 将 nameMap 列表里面键值互换
country_dict[val] = key
return country_dict
def read_csv():
"""
读取数据,返回国家英文名称列表和累计确诊数列表
:return:
"""
country_dict = read_country_code()
data = pd.read_csv("2019-nCoV.csv", index_col=False)
countrys_names = list()
confirmed_count = list()
for x in range(len(data.index)):
if data['name'].iloc[x] in country_dict.keys():
countrys_names.append(country_dict[data['name'].iloc[x]])
confirmed_count.append(data['confirm'].iloc[x])
else:
print(data['name'].iloc[x])
return countrys_names, confirmed_count
def draw_map():
"""
绘制世界地图
遇到一个很神奇的问题:
两个列表必须写死数据地图才会渲染数据,如果数据是从方法中获得,则地图不渲染数据
:return:
"""
# countrys_names, confirmed_count = read_csv()
# print(countrys_names)
# print(confirmed_count)
countrys_names = ['United States', 'Brazil', 'Russia'...]
confirmed_count = [1666828, 347398, 335882...]
c = (
Map()
.add(
"确诊人数",
[list(z) for z in zip(countrys_names, confirmed_count)],
is_map_symbol_show=False,
maptype="world",
label_opts=opts.LabelOpts(is_show=False),
itemstyle_opts=opts.ItemStyleOpts(color="rgb(49,60,72)")
)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="全球 2019-nCoV 地图"),
visualmap_opts=opts.VisualMapOpts(max_=1700000),
)
.render("map_world.html")
)
if __name__ == '__main__':
draw_map()
最终结果如下:
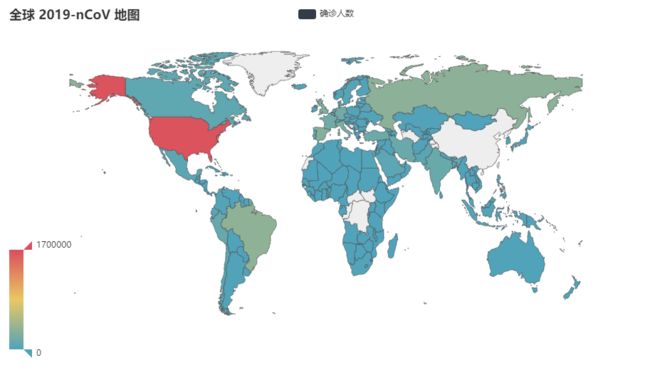
在绘制全球 2019-nCoV 地图的时候,我们最终使用的国家的名称是英文的,所以需要用到一个中英文国家名称对照字典,这个字典我找到了两个版本,一个是 Python 格式的文件 namemap.py ,还有一个是 json 格式的文件 country-code.json , 使用这两个文件中的任意一个将我们在前面获取到的数据中的中文国家名称转换为英文。这两个文件我都会提交到代码仓库,有需要的同学可以在公众号里回复关键字获取。
另外,在最后绘制地图的时候遇到了一个很奇葩的问题,国家名称列表和累计确诊人数列表如果是从前面的方法中获取到的,在最后渲染成 map_world.html 的时候,将不会渲染数字,所有的数字都是 null ,但是如果这两个列表 copy 出来,写死在代码中,就可以成功的渲染,有清楚这个问题的朋友可以在留言中解答一下,万分感激。
