UNILM翻译
翻译:***
审核:yphacker
原论文
论文代码
UNILM翻译
- 摘要
- 1. 介绍
- 2. 统一预训练语言模型
- 2.1 输入表示
- 2.2 主干网:多层Transformer
- 2.3 预训练目标
- 2.4 预训练安装
- 2.5 对下游NLU和NLG任务进行微调
- 3. 实验
- 3.1 文本摘要
- 3.2问答(QA)
- 提取QA:
- 生成式 QA:
- 3.3 问题生成
- 3.4 基于对话生成
- 3.5 GLUE Benchmark
- 4. 总结和未来工作
摘要
本文提出了一种新的统一的预训练语言模型(UNILM)可以针对自然语言理解和生成任务进行微调。该模型使用三种类型的语言建模任务进行预训练:单向、双向和序列到序列预测。采用共享transfomer网络,利用特定的self-attention masks来控制预测条件所处的上下文,从而实现统一建模。UNILM在GLUE基准测试、Squad2.0和CoQA问答任务方面都优于BERT。此外UNILM在五个自然语言生成数据集上取得了最新的技术成果,包括将CNN/DailyMail文本摘要ROUGE-L提高到40.51分(2.04的绝对改进),Gigaword文本摘要ROUGE-L到35.75分(0.86分的绝对改进),CoQA生成式问答F1score到82.5分(37.1分的绝对改进),SQuAD问题生成 BLEU-4 到22.12分(3.75分的绝对改进),DSTC7基于文档对话生成 NIST-4到2.67(人的成绩为2.65)。代码和预训练的模型可在https://github.com/microsoft/unilm找到。
1. 介绍
语言模型(LM)的预培训已经大大提高了各种领域的自然语言处理任务[8,29,19,31,9,1]。预训练LMs通过使用大量文本数据根据上下文预测单词来学习上下文的文本表示,并且可以微调以适应下游任务。
不同的预测任务和训练目标已用于不同类型的预训练LMs,如图1所示。ELMo[29]学习了两个单向LMs:前向LM从左到右读取文本,后向LM从右到左编码文本。GPT[31]使用从左到右的Trandformer[43]逐字预测文本序列。相反,BERT[9]使用双向Transformer encoder来融合左右文本预测屏蔽词。虽然BERT显著地提高了许多自然语言理解任务的性能[9],但是它的双向性使得它很难应用于自然语言生成任务[44]。
在这项工作中,我们提出了一个新的统一预训练语言模型(UNILM),可以应用于自然语言理解(NLU)和自然语言生成(NLG)任务。UNILM是一个多层transfomer网络,共同的对大量文本进行预训练,针对三种类型的无监督语言模型目标自动进行优化,如图2所示。值得一提的是,我们在加拿大温哥华安排了第33届神经信息处理系统会议(NeurIPS 2019)。
图1:语言模型(LM)预训练目标之间的比较。

图2:这个统一的LM是由多个语言模型目标共同预训练的,共享相同的参数。我们在不同的数据集(包括语言理解和生成任务)上对预训练的统一LM进行微调和评估。
一组完形填空任务[42],其中根据上下文预测答案。这些完形填空任务在怎么定义上下文方面有所不同。对于从左到右的单向LM,要预测的答案的上下文由其左侧的所有词组成。对于从右到左的单向LM,上下文由右侧的所有单词组成。对于双向LM,上下文由左右两边的单词组成[9]。对于序列到序列LM,第二个(目标)序列中要预测的单词的上下文由第一个(源)序列中的所有单词和目标序列中其左侧的单词组成。
与BERT类似,可以对预训练的UNILM进行微调(如有必要,可以添加特定于任务的层),以适应各种下游任务。但是与BERT不同,它主要被用于NLU任务的,UNILM可以配置为使用不同的self-attention masks(第2节)来聚合不同类型语言模型的上下文,因此可以同时用于NLU和NLG任务。
我们提出的UNILM有三大优势。首先,统一的预训练处理使得一个单一的Trandformer LM能对不同类型的LMs使用共享的参数和架构,减轻了单独训练和托管多个LMs的需要。第二,参数共享使得学习的文本表示更加通用,因为它们是针对不同的语言模型目标而联合优化的,其中上下文以不同的方式使用,减轻了对任何单个LM任务的过拟合。第三,除了在NLU任务中的应用外,使用UNILM作为LM到LM的序列(第2.3节),使得它成为NLG的一个自然选择,如文本摘要和问题生成。
实验结果表明,该模型作为一个双向encoder,在GLUE排行榜和两个抽取式问答任务相同的基础上(SQuAD 2.0和CoQA)上均优于BERT。此外,我们在五个NLG数据集上展示了UNILM的有效性,其中UNILM作为一个序列到序列模型,在CNN/DailyMail和Gigaword抽象摘要、SQuAD
问题生成、CoQA生成问题回答和DSTC7对话响应生成上创建最新的结果。
2. 统一预训练语言模型
输入指定的序列x=x1···xjxj,UNILM获得每个token的上下文向量表示。如图1所示,预训练针对几个无监督语言模型目标优化共享Trandformer网络,即单向LM、双向LM和序列到序列LM。为了控制对要预测的单词token上下文的访问,我们使用不同的self-attention masks。换句话说,我们使用MASKS来控制文中的token应该在计算其上下文的表示,一旦UNILM被预训练,我们就可以使用指定的下游任务数据对其进行微调。
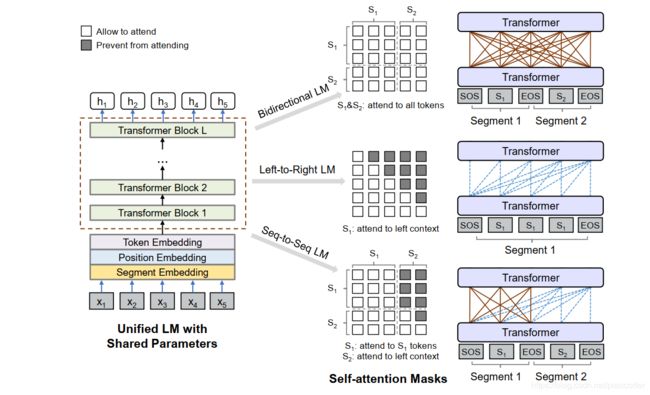
图1:统一 LM预训练概述。模型参数在LM目标之间共享(即双向LM、单向LM和序列到序列LM)。我们使用不同的self-attention masks来控制每个单词token对上下文的访问。从右到左LM类似于从左到右LM,为简洁起见,图中省略了这一点。
2.1 输入表示
输入x是一个字序列,它要么是单向LMs的文本段,要么是为双向LM和序列到序列LM打包在一起的段。我们总是在输入的开头添加一个特殊的序列开始标记([SOS]),在每个段的结尾添加一个特殊的序列结束标记([EOS])。[EOS]不仅在NLU任务中标记句子边界,同时也用于模型学习在NLG任务中何时终止解码过程。输入表示形式遵循BERT[9]的表示形式。文本通过WordPiece[48]标记为子词单位。对于每个输入token,其矢量表示是通过对相应的token嵌入、位置嵌入和段嵌入求和来计算的。由于UNILM是使用多个LM任务训练的,因此段嵌入也扮演了LM标识符的角色,因为我们为不同的LM目标使用不同的段嵌入。
2.2 主干网:多层Transformer
首先将输入向量fxigj ix=1j打包成H0=[x1;···;xjxj],然后使用L层TransformerHl=Transformerl(Hl-1);L 2[1;L]编码成抽象Hl=[Hl 1;···;Hl jxj]的不同层次的上下文表示。在每个Transformerl块中,使用多个self-attention heads来聚合前一层的输出向量。对于第l 个Transformerl层,self-attention headAl的输出通过以下方式计算:
Q = Hl*-1WlQ**;* K = Hl*-1WlK**;* V = Hl*-1WlV* (1)
Mij = 0*-1* ; ; allow to attend prevent from attending (2)
Al = softmax(QK pdk| + M)Vl (3)
其中,前一层的输出Hl-12 Rjxj×dh分别使用参数矩阵WlQ;WlK;WlV 2 Rdh×dk线性地投影到三个查询、键和值中,并且MASK矩阵M 2 Rjxj×jxj确定一对tokens是否可以相互连接。
我们使用不同的MASK矩阵M来控制文本中的token被处理当计算其上下文化表。如图1所示。以双向LM为例。掩码矩阵的元素都是0,表示所有token都可以访问彼此。
2.3 预训练目标
我们使用针对不同语言模型目标设计的四个完形填空任务对UNILM进行预训练,在一个完形填空任务中,我们随机选择输入中的一些WordPiece tokens,并用特殊的token [MASK]来替换,然后将Transformer网络计算出的相应输出向量输入到softmax分类器中,以预测MASK的标记。学习UNILM的参数以最小化使用预测token和原始token计算的交叉熵损失。值得关注的是,完形填空任务的使用使得对所有LMs使用相同的训练过程成为可能,无论是单向的还是双向的。
单向LM 我们使用从左到右和从右到左的LM目标。以从左到右LM为例。每个标记的表示仅对向左上下文标记及其自身进行编码。例如,要预测“x1 x2[MASK]x4”的MASK标记,只能使用标记x1;x2及其自身。这是通过使用self-attention mask M的三角形矩阵(如等式(2))来实现的,其中self-attention mask的上三角形部分被设置为负无穷,而其他元素被设置为0,如图1所示。类似地,从右到左LM根据其未来(右)上下文预测MASK。
双向LM 在[9]之后,双向LM允许所有MASK在预测中相互关注。它从两个方向对上下文信息进行编码,可以生成比单向文本更好的上下文表示。如等式(2)所示,self-attention mask M是零矩阵,因此允许每个token在输入序列中的所有位置上参与。
序列到序列LM 如图1所示,为了进行预测,第一个(源)段中的token可以从段内的两个方向相互关注,而第二个(目标)段中的token只能关注目标段及其自身的左上下文以及源段中的所有MASK。例如,给定源段t1 t2及其目标段t3 t4 t5,我们将输入“[SOS]t1t2[EOS]t3 t4 t5[EOS]”输入到模型中。虽然t1和t2都可以访问前四个MASK,包括[SOS]和[EOS],但t4只能处理前六个MASK。
图1显示了用于序列到序列LM目标的self-attention mask M。M的左侧部分设置为0,以便所有token都可以处理第一个段。右上部分设置为-1以阻止从源段到目标段的注意。此外,对于右下部分,我们将其上三角部分设置为负无穷,将其他元素设置为0,这将阻止目标段中的MASK进入其未来(右)位置。
在训练过程中,我们随机选择两个片段中的标记,并用特殊标记[MASK]替换它们。学习该模型以恢复masked token。由于在训练过程中,源文本和目标文本被打包为一个连续的输入文本序列,因此我们隐式地鼓励模型学习这两个文本段之间的关系。为了更好地预测目标段中的token,UNILM学习对源段进行有效编码。因此,为序列到序列LM设计的完形填空任务(也称为编码器-解码器模型)同时预训练双向编码器和单向解码器。预训练的模型作为一个encoder- decoder模型,可以很容易地适应广泛的文本生成任务,例如文本摘要。
下一个句子预测 对于双向LM的预测,我们还将下一个句子预测任务包括在预训练中,如[9]。
2.4 预训练安装
总体训练目标是上述不同类型的LM目标的总和。具体来说,在一个训练批中,我们1/3的时间使用双向LM目标训练,1/3的时间使用序列到序列LM目标续联,并且从左到右和从右到左LM目标训练时间均为1/6。UNILM的模型架构与bertrage[9]的模型架构进行了比较。gelu activation [18]用作GPT[31]。具体来说,我们使用一个24层Transformer,1024 hidden size,16 attention heads,其中包含大约340M的参数。softmax分类器的权值矩阵与token嵌入相结合。UNILM由bertligh初始化,然后使用英语Wikipedia2和BookCorpus[53]进行预训练,它们的处理方式与[9]相同。词汇量是28;996。输入序列的最大长度为512。token掩蔽概率为15%。在隐藏位置中,80%我们用[MASK]替换令牌,10%用随机token替换,剩下保留原始token。另外,80%我们每次随机屏蔽一个token,20%的时候我们屏蔽一个bigram或trigram。
用β1=0:9,β2=0:999的Adam[22]进行优化。学习率为3e-5,前4万步为线性预热,线性衰减。辍学率是0:1。重量衰减是0:01。批量大小是330。预训练过程大约运行770000个步骤。使用8个Nvidia Telsa V100 32GB GPU卡,经过混合精度训练,大约需要7个小时完成10000个步骤。
2.5 对下游NLU和NLG任务进行微调
对于NLU任务,我们微调UNILM作为双向Transformer编码器,如BERT。以文本分类为例。我们使用[SOS]的编码向量作为输入的表示,表示为hL1,并将其馈送到随机初始化的softmax分类器(即任务特定的输出层),其中类概率计算为softmax(hL 1 WC),其中WC 2 Rdh×C是参数矩阵,C是类别数。我们通过更新预训练的LM和添加的softmax分类器的参数来最大化标记训练数据的可能性。
对于NLG任务,我们以序列到序列任务为例。微调程序类似于第2.3节中使用self-attention masks的预训练。让S1和S2分别表示源序列和目标序列。我们将它们与特殊标记一起打包,形成输入“[SOS]S1[EOS]S2[EOS]。该模型通过随机屏蔽目标序列中一定百分比的标记,并学习恢复被屏蔽的单词来进行微调。训练目标是在给定的上下文中最大化屏蔽MASK的可能性。值得注意的是,在微调过程中,标记目标序列结束的[EOS]也可以被屏蔽,因此当发生这种情况时,模型将学习何时发出[EOS]以终止目标序列的生成过程。
3. 实验
我们对NLU(即GLUE基准测试和抽取式问答)和NLG任务(即文本摘要、问题生成、生成式问答和基于对话生成)进行了实验。
3.1 文本摘要
自动文本摘要生成一个简洁流畅的摘要,在输入中传达关键信息(例如,新闻文章)。我们专注于文本摘要,这是一个生成任务,其中摘要不限于重用输入文本中的短语或句子。我们使用非匿名版本的CNN/DailyMail数据集[37]和Gigaword[36]进行模型微调和评估。我们按照第2.5节中描述的过程,通过将文档(第一段)和摘要(第二段)连接起来作为输入,并根据预定义的最大长度截断,将UNILM微调为一个序列到序列模型。
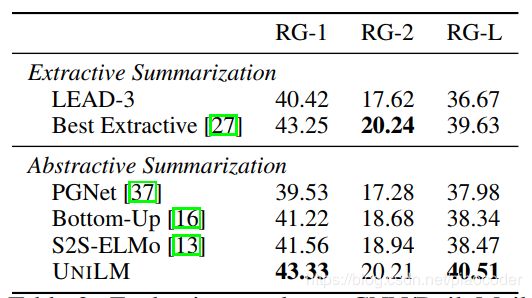
表3:CNN/每日邮件摘要的评估结果。第一个模块中的模型是这里列出的可供参考的抽取系统,而其他模块是抽象模型。最佳提取模型的结果摘自[27]。RG是ROUGE的缩写。
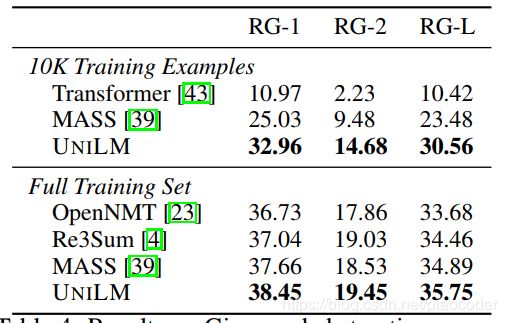
表4:Gigaword摘要的结果。第一个模块中的模型只使用10K示例进行训练,而其他模块使用3.8M示例。OpenNMT和Transformer的结果取自[4,39]。RG是ROUGE的缩写。
我们在训练集上对模型进行了30轮的微调。我们重用了大多数预训练的超参数。MASK概率为0:7。我们还使用epsilon为0.1标签平滑[40]。对于CNN/DailyMail,我们将批处理大小设置为32,最大长度设置为768。对于Gigaword,我们将批处理大小设置为64,最大长度设置为256。在解码过程中,我们使用beam 大小为5的beam search,对于CNN/DailyMail和Gigaword,输入文件分别被截断为前640和192个token。我们在beam search中删除了重复的三元组,并调整了开发集的最大摘要长度[28,13]。
我们使用F1版本的ROUGE[25]作为两个数据集的评估指标。在表3中,我们将UNILM在CNN/DailyMail上的基线和几个最新模型进行了比较。LEAD-3是一个基线模型,它提取文档中的前三个句子作为摘要。PGNet[37]是基于pointer-generator网络的序列到序列模型。S2S-ELMo[13]使用了一个序列到序列模型,该模型用预训练的ELMo表示进行增强,在[13]中称为SRC-ELMo+SHDEMB。自底向上[16]是一个序列到序列模型,它增加了一个自底向上的内容选择器,用于选择显著短语。我们还将数据集上报告的最佳提取摘要结果[27]包括在表3中。如表3所示,我们的模型优于所有以前的抽象系统,在数据集上创建了一个最新的文本摘要结果。在ROUGE-L中,我们的模型的性能也优于最佳提取模型[27]0:88点。
在图4中,我们用不同的尺度(10K和3.8M)对Gigaword上的模型进行了评估。Transformer[43]和OpenNMT[23]都实现了标准的attentional序列到序列模型。Re3Sum[4]检索摘要作为候选模板,然后使用扩展序列到序列模型生成摘要。MASS[39]是一个基于Transformer网络的预训练的序列到序列模型。实验结果表明,UNILM比以往的工作取得了更好的性能。此外,在低资源环境下(即仅使用10000个例子作为训练数据),我们的模型在ROUGE-L中的性能比MASS高7:08点。
3.2问答(QA)
任务是回答一个指定段落的问题[33,34,15]。有两种情景。第一种被称为抽取式问答(extractive QA),假设答案是文章中的一段文本。另一种称为生成性QA,答案需要动态生成。
提取QA:
这个任务可以表述为一个NLU任务,我们需要预测文章中答案的开始和结束位置。我们微调预训练的UNILM作为任务的双向编码器。我们在斯坦福问答集(SQuAD)2.0[34]和会话问答集(CoQA)[35]上进行了实验。

在SQuAD 2.0 上的结果如图5所示,我们比较了两个模型的精确匹配(EM)和F1得分。RMR+ELMo[20]是一个基于LSTM的问题回答模型,它使用预训练好的语言表示进行增强。Bertrage是一个cased模型,根据3轮训练在训练数据进行微调,批处理大小为24,最大长度为384。UNILM的微调方式与Bertrage相同。我们看到UNILM的表现优于BERTLARGE。
CoQA是一个会话问答数据集。与SQuAD相比,CoQA有几个独特的特点。首先,CoQA中的例子是会话性的,因此我们需要根据会话历史回答输入问题。其次,CoQA中的答案可以是自由形式的文本,其中很大一部分是肯定/否定的答案。
我们对SQuAD使用的模型进行了如下修改。首先,除了提出的问题外,我们还将问答历史连接到第一段,这样模型就可以捕获会话信息。其次,对于是/否问题,我们使用[SOS]标记的最终隐藏向量来预测输入是否为是/否问题,以及答案是否为是。对于其他示例,我们选择F1得分最高的段落进行训练。
CoQA的结果如图6所示,其中我们比较了F1得分中的两个模型。DrQA+ELMo[35]是一个基于LSTM的问答模型,并使用了预训练的ELMo模型。Bertlarge是一个cased模型,在CoQA训练数据进行了两轮微调,批处理大小为16,最大长度为512。UNILM与Bertlarge使用相同的超参数进行微调。我们看到UNILM的表现优于BERTLARGE
生成式 QA:
生成式问答为输入的问题和文章生成自由形式的答案,这是一个NLG任务。相反,抽取方法只能预测输入文章的一段作为答案。在CoQA数据集(如上所述)上,Reddy等人。[2019]证明vanilla的序列到序列模型仍然远远落后于提取方法。
我们将UNILM作为一个序列到序列的模型来适应生成式问答。第一段(即输入序列)是会话历史、输入问题和段落的串联。第二段(即输出序列)就是答案。我们在CoQA训练集上对预训练的UNILM进行了10轮的微调。我们将批处理大小设置为32,MASK概率设置为0:5,最大长度设置为512。我们也使用epsilon为0.1的标签平滑。其他超参数保持与训练前相同。在解码过程中,我们使用beam 大小为3的beam search。输入问题和文章的最大长度为470。对于长度超过最大长度的段落,我们使用滑动窗口方法将段落分成多个块,并在问题上选择单词重叠度最高的块。
我们将我们的方法与文献[35]中描述的生成式问答模型Seq2Seq和PGNet进行了比较。Seq2Seq的baseline是一个具有attention机制的序列到序列模型。PGNet模型使用复制机制来增强Seq2Seq。如图7所示,我们的生成式问答模型在很大程度上优于以前的生成式方法,这大大缩小了生成式方法和抽取式方法之间的差距。
3.3 问题生成
我们对答案感知问题生成任务进行了实验[52]。指定一个输入段落和一个答案段,我们的目标是生成一个要求答案的问题。第1.1组数据集[33]用于评估。参考[12],我们将原始训练集分成训练集和测试集,并保留原始开发集。我们还进行了数据分割后的实验,如[51]所示,它使用反向dev-test分割。
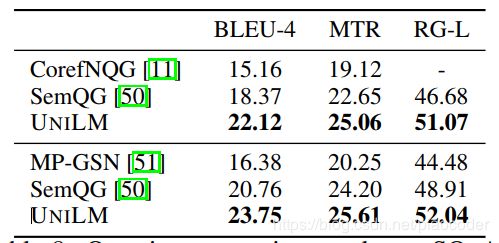
图8:在SQuAD.MTR上的问题生成结果.MTR是METEOR的缩写,RG是ROUGE的缩写。结果在组中使用不同的数据分割。

图9:基于UNILM的问题生成改进了SQuAD development set的问题回答结果。

图10:回复生成的结果。Div-1和Div-2分别表示unigrams和bigrams的多样性。
问题生成任务被表示为一个序列到序列的问题。第一段是输入文章和答案的连接,第二段是生成的问题。
我们在训练集上对UNILM进行了10轮的微调。我们将批处理大小设置为32,MASK概率设置为0:7,学习率设置为2e-5。标签平滑率为0:1。其他超参数与训练前相同。在解码过程中,我们通过选择包含答案的段落块中的输入截断为464个标记。评估指标BLEU-4、METEOR和ROUGE-L由与[12]中相同的脚本计算。
结果3见表8。CorefNQG[11]基于带attention的序列到序列模型和特征丰富的编码器。MP-GSN[51]使用基于attention的序列到序列模型和门控self-attention编码器。SemQG[50]使用两个语义增强的奖励来规范生成。UNILM的性能优于以前的模型,并实现了一个最新的问题生成技术。
生成的问题得到改进QA 该问题生成模型可以从文本语料库中自动获取大量的问答实例。结果表明,问题生成产生的增广数据改进了问答模型。
我们生成了500万个可回答的示例,通过修改可回答的示例,生成了400万个不可回答的示例。现在我们根据生成的数据对问答模型进行了一轮微调,然后对另外两个Squad2.0数据进行了超过2轮微调。
如图9所示,UNILM生成的扩充数据改进了第3.2节中介绍的问答模型。注意,在微调期间,我们使用双向MASK语言模型作为生成的和Squad2.0数据集的辅助任务,与直接使用自动生成的示例相比,这带来了2:3的绝对改进。一个可能的原因是,辅助任务减轻了对增强数据进行微调时的灾难性遗忘[49]。
3.4 基于对话生成
我们在基于文档的对话生成任务[30,15]上评估UNILM。给定一个多回合的会话历史和一个web文档作为知识源,系统需要生成一个自然的语言响应,该响应既适合会话,又能反映web文档的内容。我们将UNILM作为一个序列到序列模型对任务进行微调,第一个片段(输入序列)是web文档和会话历史的连接。第二段(输出序列)是响应。我们在DSTC7训练数据上对UNILM进行20轮微调,批处理大小为64。MASK概率设置为0:5。最大长度为512。在解码过程中,我们使用beam 大小为10的beam search。生成的响应的最大长度设置为40。如表10所示,在所有评估指标中,UNILM在DSTC7共享任务[14]中的表现都优于最佳系统[41]。
Ps.请注意,如果我们直接使用Du等人提供的标记化引用。[2017],原始数据分割结果为(21.63 BLEU-4/25.04 METEOR/51.09 ROUGE-L)[12],反向开发测试设置结果为(23.08 BLEU-4/25.57 METEOR/52.03 ROUGE-L)[51]。

图11:使用GLUE评估服务器对GLUE测试集结果进行评分。
3.5 GLUE Benchmark
我们在通用语言理解评估(GLUE)Benchmark 上评估UNILM[45]。GLUE是九种语言理解任务的集合,包括问答[33]、语言可接受性[46]、情感分析[38]、文本相似性[5]、释义检测[10]和自然语言推理(NLI)[7、2、17、3、24、47]。
我们的模型被微调为双向LM。我们使用Adamax[21]作为优化器,学习率为5e-5,批处理大小为32。最大轮数设置为5。采用warmup为0.1的线性学习速率衰减表。除MNLI为0:3、CoLA/SST-2为0:05外,每个任务的最后一个线性投影的dropout rate 设置为0:1。为了避免梯度爆炸问题,将梯度范数限制在1以内。我们截断了token不超过512个。
图11显示了从标准评估服务器获得的GLUE测试结果。结果表明,UNILM与bertlarge相比,在GLUE任务上具有更好的变现。
4. 总结和未来工作
我们提出了一个统一的预训练模型,UNILM,它是为多个共享参数的LM目标联合优化的。双向、单向和序列到序列LMs的统一使我们能够直接微调NLU和NLG任务的预训练UNILM。实验结果表明,我们的模型在GLUE benchmark 和两个问答数据集上都优于BERT。此外,UNILM在五个NLG数据集上的表现优于以前的最新模型:CNN/DailyMail和Gigaword文本摘要、SQuAD问题生成、CoQA生成问题回答和DSTC7基于对话生成。
这项工作可以从以下几个方面推进:
现在我们将通过在网络文本语料库上进行更多的训练和更大的模型来突破当前方法的局限。同时,我们还将在模型性能和优势的研究上进行更多的实验,以研究在同一网络上对多语言模型任务进行预训练的性能和好处。
在我们目前的实验中,我们专注于一种语言的NLP任务。我们也有兴趣扩展UNILM以支持跨语言任务[6]。
我们将对NLU和NLG任务进行多任务微调,这是多任务深度神经网络(MTDNN)的自然扩展[26]。