Flink HA高可用集群搭建(Standalone Cluster)
Flink HA高可用集群搭建(Standalone Cluster)
1.根据集群中hadoop的版本和scala的版本对应下载Flink,该文章下载的是Flink1.7.2版本。
下载地址 https://flink.apache.org/downloads.html
2.安装解压Flink到/home/kfs目录下(Master举例)
tar -zxvf flink-1.7.2-bin-hadoop27-scala_2.12.tgz -C /home/kfs/

3.来到flink的conf目录下
cd
ls
cd flink-1.7.2/conf/
ls

4.修改masters文件(masters文件对应着主节点,其中为了ha高可用性,使用两台机器做主备因为安装了spark,如果端口为8081可以能会有冲突,所以改为8082)
vi masters
![]()
Master:8082
Slave1:8082
![]()
5.修改slaves文件(slaves文件对应着从节点)
vi slaves
![]()
Slave1
Slave2
Slave3
Slave4
Slave5
6.修改flink-conf.yaml文件(使用的是zookeeper方式管理集群,并配置zookeeper地址,设置集群的名称,和保存的位点)
vi flink-conf.yaml
![]()
high-availability: zookeeper
high-availability.zookeeper.quorum: Slave1:2181,Slave2:2181,Slave3:2181,Slave4:2181,Slave5:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /default_one
high-availability.zookeeper.storageDir: hdfs:///flink/recovery

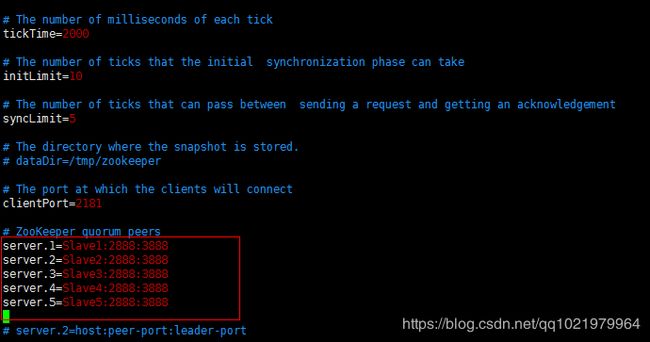
7.修改zoo.cfg文件(对应zookeeper中的ip和地址)
vi zoo.cfg
![]()
server.1=Slave1:2888:3888
server.2=Slave2:2888:3888
server.3=Slave3:2888:3888
server.4=Slave4:2888:3888
server.5=Slave5:2888:3888
8.来到root用户修改环境变量
su root
vi /etc/profile
![]()
export FLINK_HOME=/home/kfs/flink-1.7.2
:$FLINK_HOME/bin
![]()
source /etc/profile
![]()
9.回到kfs用户将flink拷贝到其它的节点
exit
cd

scp -r flink-1.7.2/ slave1:/home/kfs/flink-1.7.2/
scp -r flink-1.7.2/ slave2:/home/kfs/flink-1.7.2/
scp -r flink-1.7.2/ slave3:/home/kfs/flink-1.7.2/
scp -r flink-1.7.2/ slave4:/home/kfs/flink-1.7.2/
scp -r flink-1.7.2/ slave5:/home/kfs/flink-1.7.2/
![]()
![]()
![]()
![]()
![]()
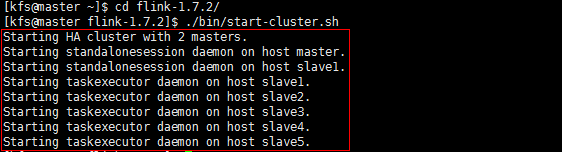
10.启动flink集群
cd flink-1.7.2/
./bin/start-cluster.sh
11.访问网页查看
master:8082
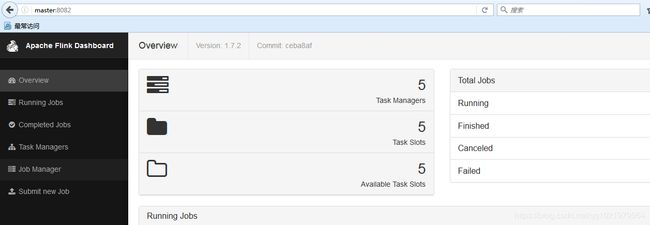
Flink高可用集群就搭建好了