Classifying Relations by Ranking with Convolutional Neural Networks实现(pytorch)
Classifying Relations by Ranking with Convolutional Neural Networks实现(pytorch)
- 1. 问题描述
- 2. 网络结构
- 效果:
- 3. 数据预处理
- 4. 模型实现
- 5. 踩过的坑
- 5.1 自定义Loss
- 5.2 F值计算
- 5.3 Loss 值溢出
- 6. 实验结果分析
1. 问题描述
这是关系抽取的一篇经典文章Classifying Relations by Ranking with Convolutional Neural Networks。使用的是SemEval2010 Task 8 数据集,共有9种二元关系,每种关系对实体的前后排列敏感,加上other分类一共19个小分类。
2. 网络结构
论文的主要是在Zeng 2014的CNN基础上做的改进,最大的变化是损失函数,不再使用softmax+cross-entropy的方式,而是margin based的ranking-loss。还有一个对于other分类的特殊处理。
先看网络结构,不考虑loss的改变,实际上的网络结构没有什么变化,同样是一层CNN加上一层全连接:

- 输入层:word embedding+position embedding
- 卷积层:长度固定为3的卷积核(实际实现的代码是多个卷积核)
- Pooling: max pooling
- 全连接层:线性相乘得到对应每个类别的score
全连接层之后没有使用常用的softmax+cross entropy,而是自定义了一个基于margin的ranking loss:
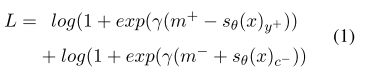
在这里有两个分数, s θ ( x ) y + s_{\theta}(x)_{y^{+}} sθ(x)y+指的是句子x正确分类对应的score,而 s θ ( x ) c − s_{\theta}(x)_{c^{-}} sθ(x)c−指的是从全连接层得到的分数向量中除去 s θ ( x ) y + s_{\theta}(x)_{y^{+}} sθ(x)y+之外最大的分量,也就是分数最大的错误得分。这样做在训练的过程中会使得 s θ ( x ) y + s_{\theta}(x)_{y^{+}} sθ(x)y+不断变大而 s θ ( x ) c − s_{\theta}(x)_{c^{-}} sθ(x)c−不断变小。其中 m + m^{+} m+与 m − m^{-} m−表示正确与错误的margin。
Other类别的特殊处理:因为Other类别比较杂,因此对其特殊处理。在计算loss的时候如果样本的label是Other,那么就将其Loss的第一项归零。而计算最终结果时只有当Other外类别的score都小于0时才归为Other类,否则选择其它score中最大一项对应的分类。
效果:
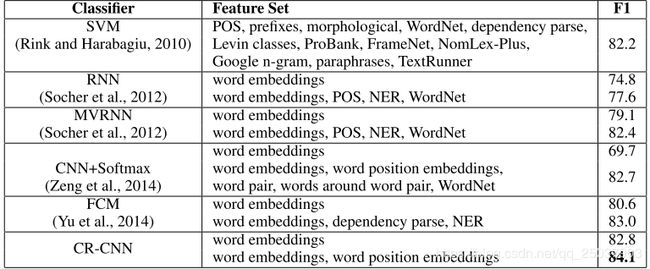
可以看出使用了这两个改进之后性能有明显的提升。
3. 数据预处理
明确我们需要的输入为每个句子的word embedding以及每个词与目标的两个实体之间的positional embedding。
举个例子:

每一个数据有三行,第一行是文本,第二行是关系label,第三行是注释。word embedding就是将每个词都转换成对应的词向量,这里可以用开源的glove等。而positional embedding是指每个词距离两个entity之间的距离映射而成的embedding。比如上图第二句中的wrapped,距离前一个实体child距离为3,距离后一个实体距离为-5,而positional embedding是用这两个数字映射得到的embedding。假如每个词的词向量维度是 d w d_{w} dw,每个距离对应的向量维度是 d p d_{p} dp,那么整合之后每个词语对应的embedding维度为 d w + 2 ∗ d p d_{w}+2*d_{p} dw+2∗dp。其中positional embedding的初始化为随机初始化。
文本为英文,使用spacy库中的分词工具来处理英文分词(主要是标点和缩写等等)。然后计算出每个词到两个实体的距离,分别存为CSV格式的训练集验证集与测试集。具体的代码在github的data_util.py文件中。
这样每个CSV中文件的格式如下:

有三列,代表label,原始句子,句子中每个词对应的位置向量。
之后需要把每个输入变成sent_len * ( d w + 2 ∗ d p d_{w}+2*d_{p} dw+2∗dp)维度的矩阵,sent_len表示的是句子的长度。这里由于每个句子的长度不同,因此统一句子的长度为90个词。不足的部分用’ < p a d > <pad> <pad>'替代,长的部分舍去。因此词到实体的距离的取值就在[-89,89]之间。
其中位置的表示已经用数字表示出来了,只需要在模型中加一个embedding层进行lookup即可。而句子需要分词后建立词表,然后将每个词对应成词典中的序号。这里使用了torchtext库直接完成,这部分代码如下:
def tokenizer(text): # create a tokenizer function
# 返回 a list of
return [tok.text for tok in nlp.tokenizer(text)]
def emb_tokenizer(l):
r = [y for x in eval(l) for y in x]
return r
TEXT = data.Field(sequential=True, tokenize=tokenizer,fix_length=args.sent_len)
LABEL = data.Field(sequential=False, unk_token=None)
POS_EMB = data.Field(sequential=True,unk_token=0,tokenize=emb_tokenizer,use_vocab=False,pad_token=0,fix_length=2*args.sent_len)
print('loading data...')
train,valid,test = data.TabularDataset.splits(path='../data/SemEval2010_task8_all_data',
train='SemEval2010_task8_training/TRAIN_FILE_SUB.CSV',
validation='SemEval2010_task8_training/VALID_FILE.CSV',
test='SemEval2010_task8_testing_keys/TEST_FILE_FULL.CSV',
format='csv',
skip_header=True,csv_reader_params={'delimiter':'\t'},
fields=[('relation',LABEL),('sentence',TEXT),('pos_embed',POS_EMB)])
TEXT.build_vocab(train,vectors='glove.6B.300d')
LABEL.build_vocab(train)
train_iter, val_iter, test_iter = data.Iterator.splits((train,valid,test),
batch_sizes=(args.batch_size,len(valid),len(test)),
device=args.device,
sort_key=lambda x: len(x.sentence),
# sort_within_batch=False,
repeat=False)
torchtext库的使用可以参考官方文档以及这个博客还有知乎文章。总的来说这个库能够完成分词、去停用词、建立词表映射、设定预训练的词向量等诸多操作,而且最后能够以iterator的形式给出处理完的结果,很是方便。
4. 模型实现
其实也没得说的,具体还是要看代码。
可以先实现成正常的cnn+softmax+cross entropy的形式,然后在这个基础上进行修改。主要的修改是加入了positional embedding,需要与原本的word embedding合并以后再进行卷积的操作。正常的cnn实现可以参考前一篇文章pytorch 实现textCNN。也可以直接看我的github。
实际上改进的部分在于Loss的计算,因此在cnn结构的部分基本没有变化,主要的变化是Loss的设计,这里遇到了不少坑,还是直接看代码吧。
还有一个是对于Other类别的特殊处理。在Loss的计算里已经加上了,不过在判断结果的时候也会有一个特殊处理。在train.py的getResult函数里。
除此之外还有个要注意的点就是虽然实际上有19个(9*2+1)分类,但实际上在计算F值的时候不计算Other类,同时将剩下的18类当做实体前后不敏感的9类计算。如下图所示,cnn模型计算score时当做18类,而计算accuracy和F值时候当做9类。

5. 踩过的坑
5.1 自定义Loss
才疏学浅,还以为将Loss表示出来pytorch就能完成自动求导。我毕竟还是too young。可以参考知乎问题pytorch如何自定义loss?首先就是继承自nn.Module,然后是必须让计算图能够连起来,不然没法计算梯度。
写完loss之后可以自行测试一下,看看计算的梯度是否与理论相符:
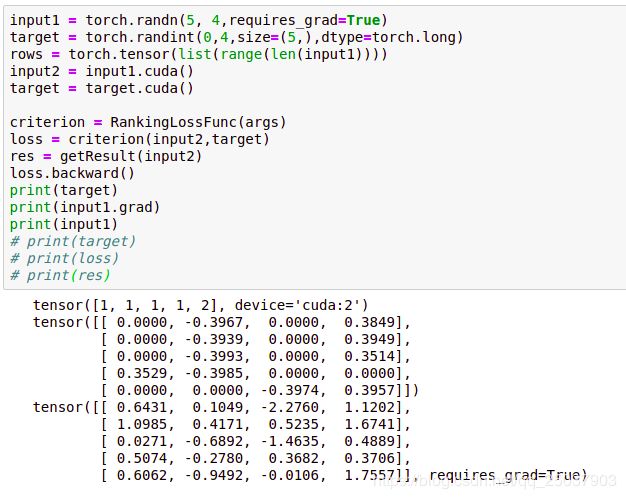
比如这个基于margin的ranking loss,与每个样本score向量中的一个或两个分量有关系(与最大的score对应的label是否是other有关),可以观察对应的梯度是否相符。
5.2 F值计算
就是不计算other以及把18类归为9类计算的事情。不好好看论文的结果。
5.3 Loss 值溢出
再看一眼loss的定义:

随着训练过程的持续,正确分类的score不断变大,错误分类的score不断变小。经过exponential操作以后就会导致溢出。
报的错误是cuda runtime error (59) : device-side assert triggered at /pytorch/aten/src/THC/generic/THCTensorCopy.c:70类似的,而且根本定位不了。
搜来搜去都说大致是因为可能是数组下标越界,然而找了一两天才发现并不是,而是因为溢出。
我的解决方法是修改它的loss:
原来的loss为: L = l o g ( 1 + e x p ( γ ( m + − s θ ( x ) y + ) ) + l o g ( 1 + e x p ( γ ( m − − s θ ( x ) c − ) ) L=log(1+exp(\gamma(m^{+}-s_{\theta}(x)_{y^{+}}))+log(1+exp(\gamma(m^{-}-s_{\theta}(x)_{c^{-}})) L=log(1+exp(γ(m+−sθ(x)y+))+log(1+exp(γ(m−−sθ(x)c−)),我修改后的Loss为
L = l o g ( 1 + e x p ( γ ( m + − s θ ( x ) y + ) ) + l o g ( 1 + e x p ( γ ( − 100 + s θ ( x ) y + ) ) + l o g ( 1 + e x p ( γ ( m − − s θ ( x ) c − ) ) + l o g ( 1 + e x p ( γ ( − 100 − s θ ( x ) c − ) ) L=log(1+exp(\gamma(m^{+}-s_{\theta}(x)_{y^{+}}))+log(1+exp(\gamma(-100+s_{\theta}(x)_{y^{+}}))+log(1+exp(\gamma(m^{-}-s_{\theta}(x)_{c^{-}}))+log(1+exp(\gamma(-100-s_{\theta}(x)_{c^{-}})) L=log(1+exp(γ(m+−sθ(x)y+))+log(1+exp(γ(−100+sθ(x)y+))+log(1+exp(γ(m−−sθ(x)c−))+log(1+exp(γ(−100−sθ(x)c−))
这个Loss大致能够保证正确label的score不超过100,错误label的score不超过-100。不过我比较想知道不修改loss的话应该怎么避免这个溢出的问题。
6. 实验结果分析
拼了老命调参最后的结果F值只有77左右,距离文中的84还相去甚远,感觉可能不全是调参的问题,暂时先这样吧。
训练集上非other类别的准确率已经接近100%了,所以应该不是模型表现力不够的问题,那就是过拟合了。不过L2系数加了一点之后就开始学不到东西了。dropout已经加到0.7,再加结果也会变得更差。在embedding层后面以及卷积层后面都加了dropout了。
分析一下可能导致效果不好的原因:
- 可能是修改后的loss导致的,暂时没招。
- 可能是句子的处理时统一截断长度为90以及对于padding的符号没有计算相应的到实体的距离的问题。对于padding的符号,到实体的距离都padding为一个固定的值了。但我感觉这样做应该问题不大吧毕竟已经是padding而不是有意义的词了。而且原文也没提到怎么处理这部分。
- 词向量问题。文中参数先是词向量维度是400,大概是自己训练的吧因为glove里也没发现有400维的数据。但这个概率也不大,因为之前的文章里有cnn+cross entropy的使用的是50维的词向量也比77的效果更好。
- 还是调参问题。已经尽力了。。。
- 未知问题。尽力了。
最后感谢github某老哥的tensorflow版本的实现。