【深度神经网络】五、GoogLeNet网络详解
概要
本篇文章的重点就是主要介绍GoogLeNet的网络架构,这个网络架构于2014年由Google团队提出。
GoogLeNet的论文为:Going deeper with convolutions。
同时GoogLeNet也在经历了从v1、v2、v3、v4几个版本的改进过程。由于内容较多,因此将我也将在之后几篇博客中进行详细叙述。在本篇博客中主要将介绍GoogLeNet v1的网络架构。
一、背景与动机
在2012年,AlexNet在ImageNet图像分类竞赛中获得了冠军,这也使得深度学习与卷积神经网络开始了快速发展。在2014年的ImageNet图像分类竞赛中,GoogLeNet取得了第一名的成绩,其模型参数参数但只有AlexNet的 1 12 \frac{1}{12} 121。GoogLeNet的成功主要得益于Inception模块,整个GoogLeNet的主体架构可以看成多个Inception模块堆叠而成。
在GoogLeNet之前的卷积神经网络基本都是由多个卷积层与池化层堆积而成,然后接入一个或者多个
全连接层来预测输出。在卷积神经网络的在全连接层之前的卷积层和池化层的目的提取各种图像特征,这些图像特征为了适应全连接层的输入都会拉成一维向量,通常这就导致了网络模型参数主要集中在全连接层,因此为了避免过拟合,在全连接层通常会使用dropout来降低过拟合的风险。
同时,池化层主要分类平均池化层和最大池化层两种。平均池化层主要保留图像的背景信息,最大池化层最要保留纹理信息没,池化层的主要目的是减少特征和网络参数,在目前GoogLeNet之前通常使用的最大池化层。但是最大池化层可能会导致空间信息的损失,降低模型的表达能力。因此为了解决这个问题,Lin等人在2013年提出了Inception——“Network in Network”。Inception模块主要在CNN中添加一个额外的1X1卷积层,使用Relu作为激活函数,其主要作用是在不牺牲网络模型性能的前提下,即实现网络特征的降维、减少大量计算量,这有利用训练更深更广的网络。
二、GoogLeNet详解
提高深度网络模型性能的常用方法就是提高网络模型大小,网络模型大小包括网络深度与网络宽度。在有足够的有标签数据的前提下,这是简单和保险的训练高性能模型的方法,但这会加大网络模型参数,加大了模型过拟合的风险。同时这也大大降低的训练周期,带来了大量的计算开销,尤其是在全连接层。解决上述两个问题的可行方式就是利用稀疏连接来代替全连接层。
在《Provable bounds for learning some deep representations》这篇论文中提到对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。所以,为了既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能,这篇论文提出了Inception的结构,这也是GoogLeNet的基础模块。
因此在这里有必要对原始的Inception结构进行详细叙述。Inception 结构的主要思路是用密集成分来近似最优的局部稀疏结构。原始Inception 结构如下图所示。
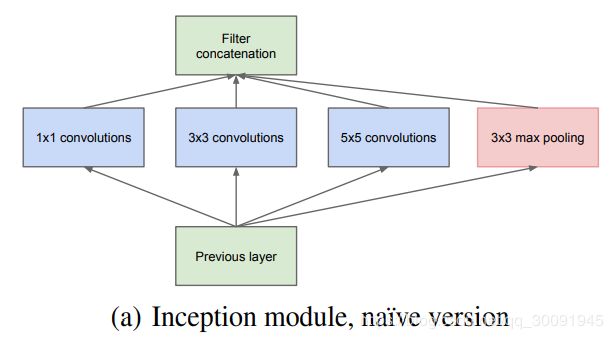
显然从上图中可以看出,原始Inception 结构采用 1 × 1 1\times1 1×1、 3 × 3 3\times3 3×3和 5 × 5 5\times5 5×5三种卷积核的卷积层进行并行提取特征,这可以加大网络模型的宽度,不同大小的卷积核也就意味着原始Inception 结构可以获取到不同大小的感受野,上图中的最后拼接就是将不同尺度特征进行深度融合。
同时在原始Inception 结构之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接深度融合了。
最后文章说很多地方都表明pooling挺有效,所以原始Inception结构里面也加入了最大池化层来降低网络模型参数。特别重要的是网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,GoogLeNet中3x3和5x5卷积的比例也要增加。
但是原始Inception结构中 5 × 5 5\times5 5×5卷积核仍然会带来巨大的计算量。降低 5 × 5 5\times5 5×5卷积核带来的计算量,GoogLeNet中借鉴了NIN(Network in Network)的思想使用 1 × 1 1\times1 1×1卷积层与 5 × 5 5\times5 5×5卷积层相结合来实现参数降维。
对于 1 × 1 1\times1 1×1卷积层与 5 × 5 5\times5 5×5卷积层实现参数降维,在这里也举一个简单的例子进行说明。假如上一层的输出为 100 × 100 × 128 100\times100\times128 100×100×128,经过具有 256 256 256个输出的 5 × 5 5\times5 5×5卷积层之后(stride=1,pad=2),输出数据为 100 × 100 × 256 100\times100\times256 100×100×256。其中,那么卷积层的参数为 128 × 5 × 5 × 256 128\times5\times5\times256 128×5×5×256。此时如果上一层输出先经过具有 32 32 32个输出的 1 × 1 1\times1 1×1卷积层,再经过具有 256 256 256个输出的 5 × 5 5\times5 5×5卷积层,那么最终的输出数据仍为为 100 × 100 × 256 100\times100\times256 100×100×256,但卷积参数量已经减少为 128 × 1 × 1 × 32 + 32 × 5 × 5 × 256 128\times1\times1\times32 + 32\times5\times5\times256 128×1×1×32+32×5×5×256,相比之下参数大约减少了4倍。
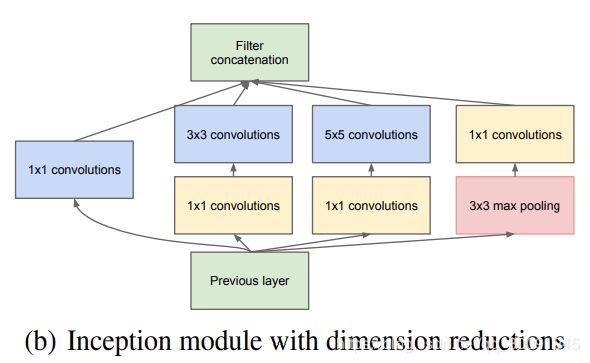
因此在 3 × 3 3\times3 3×3和 5 × 5 5\times5 5×5卷积层之前加入合适的 1 × 1 1\times1 1×1卷积层可以在一定程度上减少模型参数,那么在GoogLeNet中基础Inception结构也就做出了相应的改进,改进后的Inception结构如下图所示。
那么GoogLeNet的整体网络架构如下:
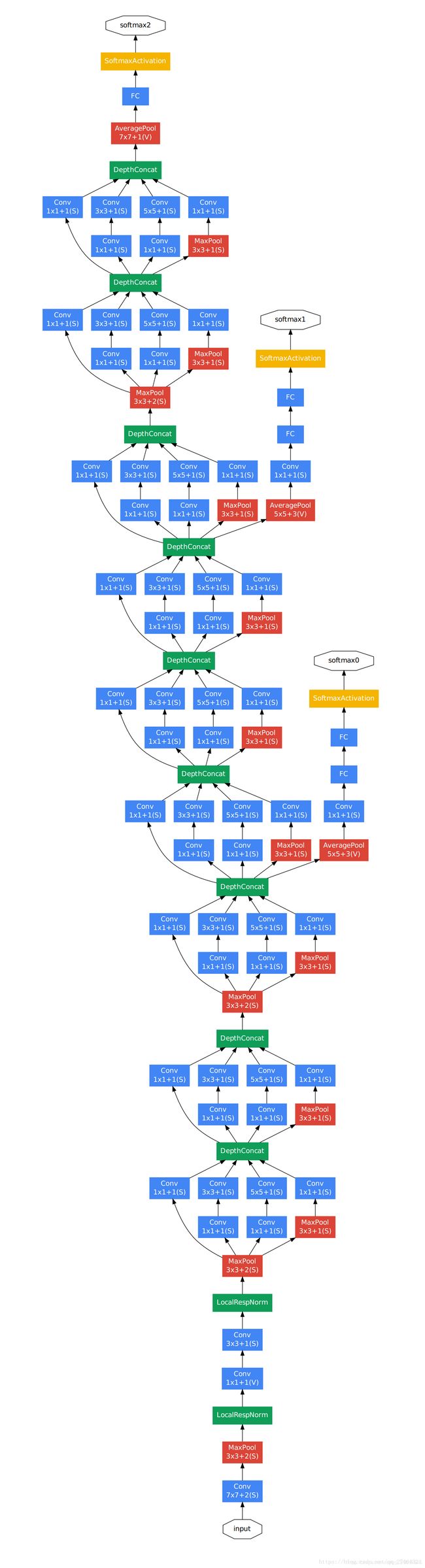 显然从上图可以看出,GoogLeNet主体架构是利用改进之后的Inception结构堆积而成22层层卷积神经网络。同时GoogLeNet在全连接层之前采用了平均池化层来降低特征,该想法来自也NIN事实证明可以将TOP1 accuracy提高0.6%。从上图也可以看出GoogLeNet网络架构较深,如果梯度从最后一层传递到第一层,可能会出现梯度消失的情况。因此为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。
显然从上图可以看出,GoogLeNet主体架构是利用改进之后的Inception结构堆积而成22层层卷积神经网络。同时GoogLeNet在全连接层之前采用了平均池化层来降低特征,该想法来自也NIN事实证明可以将TOP1 accuracy提高0.6%。从上图也可以看出GoogLeNet网络架构较深,如果梯度从最后一层传递到第一层,可能会出现梯度消失的情况。因此为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。
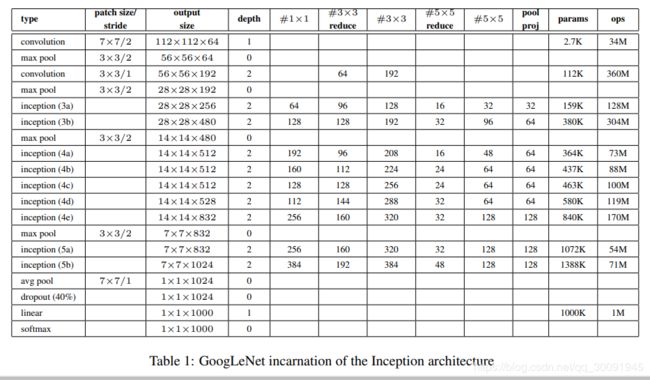
下面是GoogLeNet的各个模块的参数示意表。从下图也可看出,相比于AlexNet,GoogLeNet的网络参数大幅度下降,只有AlexNet的 1 12 \frac{1}{12} 121。
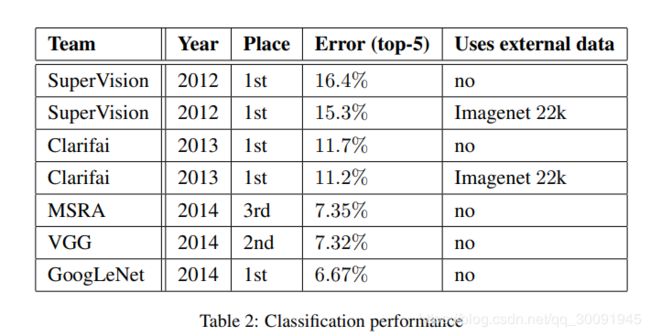
下面是GoogLeNet在ImageNet分类竞赛相关指标的对比结果。可以看出,GoogLeNet在2014年ImageNet分类竞赛获得了6.67%的Top5的错误率,比VGG网络的性能好一点。
**
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=t0cl3g0ye684
**