其实数据分析中80%的时间都是在数据清理部分,loading, clearning, transforming, rearranging。而pandas非常适合用来执行这些任务。
7.1 Handling Missing Data
在pandas中,missing data呈现的方式有些缺点的,但对大部分用户能起到足够的效果。对于数值型数据,pandas用浮点值Nan(Not a Number)来表示缺失值。我们称之为识别符(sentinel value),这种值能被轻易检测到:
import pandas as pd
import numpy as np
In [10]: string_data = pd.Series(['aardvark', 'artichoke', np.nan, 'avocado'])
In [11]: string_data
Out[11]:
0 aardvark
1 artichoke
2 NaN
3 avocado
dtype: object
In [12]: string_data.isnull()
Out[12]:
0 False
1 False
2 True
3 False
dtype: bool
在pandas中,我们使用了R语言中的一些传统,把缺失值表示为NA(not available)。在统计应用里,NA数据别是要么是数据不存在,要么是存在但不能被检测到。做数据清理的时候,对缺失值做分析是很重要的,我们要确定是否是数据收集的问题,或者缺失值是否会带来潜在的偏见。
内建的Python None值也被当做NA:
In [13]: string_data[0] = None
In [14]: string_data.isnull()
Out[14]:
0 True
1 False
2 True
3 False
dtype: bool
pandas项目中还在不断优化内部细节以更好处理缺失数据,像用户API功能,例如pandas.isnull,去除了许多恼人的细节。表7-1列出了一些关于缺失数据处理的函数。

1 Filtering Out Missing Data(过滤缺失值)
有一些方法来过滤缺失值。可以使用pandas.isnull和boolean indexing, 配合使用dropna。对于series,只会返回non-null数据和index values:
In [15]: from numpy import nan as NA
In [16]: data = pd.Series([1, NA, 3.5, NA, 7])
In [17]: data.dropna()
Out[17]:
0 1.0
2 3.5
4 7.0
dtype: float64
这等价于:
In [18]: data[data.notnull()]
Out[18]:
0 1.0
2 3.5
4 7.0
dtype: float64
对于DataFrame,会复杂一些。你可能想要删除包含有NA的row和column。dropna默认会删除包含有缺失值的row:
In [19]: data = pd.DataFrame([[1., 6.5, 3.], [1., NA, NA],
....: [NA, NA, NA], [NA, 6.5, 3.]])
In [20]: cleaned = data.dropna()
In [21]: data
Out[21]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
In [22]: cleaned
Out[22]:
0 1 2
0 1.0 6.5 3.0
设定how=all只会删除那些全是NA的行:
In [23]: data.dropna(how='all')
Out[23]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
3 NaN 6.5 3.0
删除列也一样,设置axis=1:
In [24]: data[4] = NA
In [25]: data
Out[25]:
0 1 2 4
0 1.0 6.5 3.0 NaN
1 1.0 NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN 6.5 3.0 NaN
In [26]: data.dropna(axis=1, how='all')
Out[26]:
0 1 2
0 1.0 6.5 3.0
1 1.0 NaN NaN
2 NaN NaN NaN
3 NaN 6.5 3.0
一种删除DataFrame row的相关应用是是time series data。假设你想要保留有特定数字的观测结果,可以使用thresh参数:
In [38]: from numpy import nan as NA
In [39]: df = pd.DataFrame(np.random.randn(7, 3))
In [40]: df.iloc[:4, 1] = NA
In [41]: df.iloc[:2, 2] = NA
...: df
Out[41]:
0 1 2
0 -1.246074 NaN NaN
1 0.778845 NaN NaN
2 -1.898484 NaN 0.425853
3 1.077799 NaN -1.412578
4 -1.035750 -2.607838 0.192172
5 -0.112143 0.204284 1.039244
6 0.749974 -2.872124 -0.376451
In [42]: df.dropna(thresh=2) #留下的一行至少有两个数不是缺失值
Out[42]:
0 1 2
2 -1.898484 NaN 0.425853
3 1.077799 NaN -1.412578
4 -1.035750 -2.607838 0.192172
5 -0.112143 0.204284 1.039244
6 0.749974 -2.872124 -0.376451
In [43]: df.dropna(thresh=3)
Out[43]:
0 1 2
4 -1.035750 -2.607838 0.192172
5 -0.112143 0.204284 1.039244
6 0.749974 -2.872124 -0.376451
2 Filling In Missing Data(填补缺失值)
不是删除缺失值,而是用一些数字填补。对于大部分目的,fillna是可以用的。调用fillna的时候设置好一个常用用来替换缺失值:
In [33]: df.fillna(0)
Out[33]:
0 1 2
0 -0.204708 0.000000 0.000000
1 -0.555730 0.000000 0.000000
2 0.092908 0.000000 0.769023
3 1.246435 0.000000 -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
给fillna传入一个dict,可以给不同列替换不同的值:
In [34]: df.fillna({1: 0.5, 2: 0})
Out[34]:
0 1 2
0 -0.204708 0.500000 0.000000
1 -0.555730 0.500000 0.000000
2 0.092908 0.500000 0.769023
3 1.246435 0.500000 -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
fillna返回一个新对象,但你可以使用in-place来直接更改原有的数据:
In [35]: _ = df.fillna(0, inplace=True)
In [36]: df
Out[36]:
0 1 2
0 -0.204708 0.000000 0.000000
1 -0.555730 0.000000 0.000000
2 0.092908 0.000000 0.769023
3 1.246435 0.000000 -1.296221
4 0.274992 0.228913 1.352917
5 0.886429 -2.001637 -0.371843
6 1.669025 -0.438570 -0.539741
在使用fillna的时候,这种插入法同样能用于reindexing:
In [37]: df = pd.DataFrame(np.random.randn(6, 3))
In [38]: df.iloc[2:, 1] = NA
In [39]: df.iloc[4:, 2] = NA
In [40]: df
Out[40]:
0 1 2
0 0.476985 3.248944 -1.021228
1 -0.577087 0.124121 0.302614
2 0.523772 NaN 1.343810
3 -0.713544 NaN -2.370232
4 -1.860761 NaN NaN
5 -1.265934 NaN NaN
In [41]: df.fillna(method='ffill')
Out[41]:
0 1 2
0 0.476985 3.248944 -1.021228
1 -0.577087 0.124121 0.302614
2 0.523772 0.124121 1.343810
3 -0.713544 0.124121 -2.370232
4 -1.860761 0.124121 -2.370232
5 -1.265934 0.124121 -2.370232
In [42]: df.fillna(method='ffill', limit=2) #可以连续填充的最大量是2
Out[42]:
0 1 2
0 0.476985 3.248944 -1.021228
1 -0.577087 0.124121 0.302614
2 0.523772 0.124121 1.343810
3 -0.713544 0.124121 -2.370232
4 -1.860761 NaN -2.370232
5 -1.265934 NaN -2.370232
只要有些创新,你就可以利用fillna实现许多别的功能。比如说,你可以传入Series的平均值或中位数:
In [43]: data = pd.Series([1., NA, 3.5, NA, 7])
In [44]: data.fillna(data.mean())
Out[44]:
0 1.000000
1 3.833333
2 3.500000
3 3.833333
4 7.000000
dtype: float64

7.2 数据转换
本章到目前为止介绍的都是数据的重排。另一类重要操作则是过滤、清理以及其他的转换工作。
1 删除重复值
DataFrame中出现重复行有多种原因。下面就是一个例子:
In [45]: data = pd.DataFrame({'k1': ['one', 'two'] * 3 + ['two'],
....: 'k2': [1, 1, 2, 3, 3, 4, 4]})
In [46]: data
Out[46]:
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
6 two 4
DataFrame方法duplicated返回的是一个布尔 Series,表示一个row是否是重复的(根据前一行来判断):
In [47]: data.duplicated()
Out[47]:
0 False
1 False
2 False
3 False
4 False
5 False
6 True
dtype: bool
drop_duplicateds返回一个DataFrame,会删除重复的部分:
In [48]: data.drop_duplicates()
Out[48]:
k1 k2
0 one 1
1 two 1
2 one 2
3 two 3
4 one 3
5 two 4
上面两种方法都默认考虑所有列;另外,我们可以指定一部分来检测重复值。假设我们只想检测'k1'列的重复值:
In [49]: data['v1'] = range(7)
In [50]: data.drop_duplicates(['k1'])
Out[50]:
k1 k2 v1
0 one 1 0
1 two 1 1
duplicated和drop_duplicated默认保留第一次观测到的数值组合。设置keep='last'能返回最后一个:
In [51]: data.drop_duplicates(['k1', 'k2'], keep='last')
Out[51]:
k1 k2 v1
0 one 1 0
1 two 1 1
2 one 2 2
3 two 3 3
4 one 3 4
6 two 4 6
2 Transforming Data Using a Function or Mapping(用函数和映射来转换数据)
有时候我们可能希望做一些数据转换。比如下面一个例子,有不同种类的肉:
In [52]: data = pd.DataFrame({'food': ['bacon', 'pulled pork', 'bacon',
....: 'Pastrami', 'corned beef', 'Bacon',
....: 'pastrami', 'honey ham', 'nova lox'],
....: 'ounces': [4, 3, 12, 6, 7.5, 8, 3, 5, 6]})
In [53]: data
Out[53]:
food ounces
0 bacon 4.0
1 pulled pork 3.0
2 bacon 12.0
3 Pastrami 6.0
4 corned beef 7.5
5 Bacon 8.0
6 pastrami 3.0
7 honey ham 5.0
8 nova lox 6.0
假设你想加一列,表明每种肉来源的动物是什么。我们可以写一个映射:
meat_to_animal = {
'bacon': 'pig',
'pulled pork': 'pig',
'pastrami': 'cow',
'corned beef': 'cow',
'honey ham': 'pig',
'nova lox': 'salmon'
}
用于series的map方法接受一个函数,或是一个字典,包含着映射关系,但这里有一个小问题,有些肉是大写,有些是小写。因此,我们先用str.lower把所有的值变为小写:
In [55]: lowercased = data['food'].str.lower()
In [56]: lowercased
Out[56]:
0 bacon
1 pulled pork
2 bacon
3 pastrami
4 corned beef
5 bacon
6 pastrami
7 honey ham
8 nova lox
Name: food, dtype: object
In [57]: data['animal'] = lowercased.map(meat_to_animal)
In [58]: data
Out[58]:
food ounces animal
0 bacon 4.0 pig
1 pulled pork 3.0 pig
2 bacon 12.0 pig
3 Pastrami 6.0 cow
4 corned beef 7.5 cow
5 Bacon 8.0 pig
6 pastrami 3.0 cow
7 honey ham 5.0 pig
8 nova lox 6.0 salmon
我们也可以用一个函数解决上面的问题:
In [59]: data['food'].map(lambda x: meat_to_animal[x.lower()])
Out[59]:
0 pig
1 pig
2 pig
3 cow
4 cow
5 pig
6 cow
7 pig
8 salmon
Name: food, dtype: object
使用map是一个很简便的方法,用于element-wise转换和其他一些数据清洗操作。
3 Replacing Values(替换值)
其实fillna是一个特殊换的替换操作。map可以用于修改一个object里的部分值,但是replace能提供一个更简单和更灵活的方法做到这点。下面是一个series:
In [60]: data = pd.Series([1., -999., 2., -999., -1000., 3.])
In [61]: data
Out[61]:
0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
这里-999可能是用来表示缺失值的标识符。用NA来替代的话,用replace,会产生一个新series(除非使用inplace=True):
In [62]: data.replace(-999, np.nan)
Out[62]:
0 1.0
1 NaN
2 2.0
3 NaN
4 -1000.0
5 3.0
dtype: float64
如果想要一次替换多个值,直接用一个list即可:
In [63]: data.replace([-999, -1000], np.nan)
Out[63]:
0 1.0
1 NaN
2 2.0
3 NaN
4 NaN
5 3.0
dtype: float64
对于不同的值用不同的替换值,也是导入一个list:
In [64]: data.replace([-999, -1000], [np.nan, 0])
Out[64]:
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
参数也可以是一个dict:
In [65]: data.replace({-999: np.nan, -1000: 0})
Out[65]:
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
注意:data.replace方法和data.str.replace方法是不同的,后者会对string进行element-wise替换。
4 Renaming Axis Indexes(重命名Axis Indexes)
像是series里的value一样,axis label也能类似地是函数或映射来转换,产生一个新的object。当然也可以设置in-place不产生新的数据:
In [66]: data = pd.DataFrame(np.arange(12).reshape((3, 4)),
....: index=['Ohio', 'Colorado', 'New York'],
....: columns=['one', 'two', 'three', 'four'])
跟Series一样,轴索引也有一个map方法:
In [67]: transform = lambda x: x[:4].upper()
In [68]: data.index.map(transform)
Out[68]: Index(['OHIO', 'COLO', 'NEW '], dtype='object')
可以赋值给index,以in-place的方式修改DataFrame:
In [69]: data.index = data.index.map(transform)
In [70]: data
Out[70]:
one two three four
OHIO 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
如果你想要创建一个转换后的版本,而且不用修改原始的数据,可以用rename:
In [71]: data.rename(index=str.title, columns=str.upper)
Out[71]:
ONE TWO THREE FOUR
Ohio 0 1 2 3
Colo 4 5 6 7
New 8 9 10 11
注意,rename能用于dict一样的oject,
In [72]: data.rename(index={'OHIO': 'INDIANA'},
....: columns={'three': 'peekaboo'})
Out[72]:
one two pekaboo four
INDIANA 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
rename能让你避免陷入手动赋值给index和columns的杂务中。可以用inplace直接修改原始数据:
In [73]: data.rename(index={'OHIO': 'INDIANA'}, inplace=True)
In [74]: data
Out[74]:
one two three four
INDIANA 0 1 2 3
COLO 4 5 6 7
NEW 8 9 10 11
5 Discretization and Binning(离散化和装箱)
连续型数据经常被离散化或分散成bins(分箱)来分析。假设你有一组数据,你想把人分到不同的年龄组里:
In [75]: ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
接下来将这些数据划分为“18到25”、“26到35”、“35到60”以及“60以上”几个面元。要实现该功能,你需要使用pandas的cut函数:
In [76]: bins = [18, 25, 35, 60, 100]
In [77]: cats = pd.cut(ages, bins)
In [78]: cats
Out[78]:
[(18, 25], (18, 25], (18, 25], (25, 35], (18, 25], ..., (25, 35], (60, 100], (35,60], (35, 60], (25, 35]]
Length: 12
Categories (4, interval[int64]): [(18, 25] < (25, 35] < (35, 60] < (60, 100]]
返回的是一个特殊的Categorical object。我们看到的结果描述了pandas.cut如何得到bins。可以看作是一个string数组用来表示bin的名字,它内部包含了一个categories数组,用来记录不同类别的名字,并伴有表示ages的label(可以通过codes属性查看):
In [79]: cats.codes
Out[79]: array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8)
In [80]: cats.categories
Out[80]:
IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]]
closed='right',
dtype='interval[int64]')
In [81]: pd.value_counts(cats)
Out[81]:
(18, 25] 5
(35, 60] 3
(25, 35] 3
(60, 100] 1
dtype: int64
这里pd.value_counts(cats)是pandas.cut后bin的数量。
这里我们注意一下区间。括号表示不包含,方括号表示包含。你可以自己设定哪一边关闭(right=False):
Out[82]:
[[18, 26), [18, 26), [18, 26), [26, 36), [18, 26), ..., [26, 36), [61, 100), [36,
61), [36, 61), [26, 36)]
Length: 12
Categories (4, interval[int64]): [[18, 26) < [26, 36) < [36, 61) < [61, 100)]
你也可以用一个list或数组给labels选项来设定bin的名字:
In [83]: group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior']
In [84]: pd.cut(ages, bins, labels=group_names)
Out[84]:
[Youth, Youth, Youth, YoungAdult, Youth, ..., YoungAdult, Senior, MiddleAged, Mid
dleAged, YoungAdult]
Length: 12
Categories (4, object): [Youth < YoungAdult < MiddleAged < Senior]
如果你只是给一个bins的数量来cut,而不是自己设定每个bind的范围,cut会根据最大值和最小值来计算等长的bins。比如下面我们想要做一个均匀分布的四个bins:
In [85]: data = np.random.rand(20)
In [86]: pd.cut(data, 4, precision=2) #选项precision=2,限定小数只有两位
Out[86]:
[(0.34, 0.55], (0.34, 0.55], (0.76, 0.97], (0.76, 0.97], (0.34, 0.55], ..., (0.34
, 0.55], (0.34, 0.55], (0.55, 0.76], (0.34, 0.55], (0.12, 0.34]]
Length: 20
Categories (4, interval[float64]): [(0.12, 0.34] < (0.34, 0.55] < (0.55, 0.76] <
(0.76, 0.97]]
选项precision=2,限定小数只有两位。
一个近似的函数,qcut,会按照数据的分位数来分箱。取决于数据的分布,用cut通常不能保证每一个bin有一个相同数量的数据点。而qcut是按百分比来切的,所以可以得到等数量的bins:
In [87]: data = np.random.randn(1000) # Normally distributed
In [88]: cats = pd.qcut(data, 4) # Cut into quartiles
In [89]: cats
Out[89]:
[(-0.0265, 0.62], (0.62, 3.928], (-0.68, -0.0265], (0.62, 3.928], (-0.0265, 0.62]
, ..., (-0.68, -0.0265], (-0.68, -0.0265], (-2.95, -0.68], (0.62, 3.928], (-0.68,
-0.0265]]
Length: 1000
Categories (4, interval[float64]): [(-2.95, -0.68] < (-0.68, -0.0265] < (-0.0265,
0.62] <
(0.62, 3.928]]
In [90]: pd.value_counts(cats)
Out[90]:
(0.62, 3.928] 250
(-0.0265, 0.62] 250
(-0.68, -0.0265] 250
(-2.95, -0.68] 250
dtype: int64
类似的,在cut中我们可以自己指定百分比:
In [91]: pd.qcut(data, [0, 0.1, 0.5, 0.9, 1.])
Out[91]:
[(-0.0265, 1.286], (-0.0265, 1.286], (-1.187, -0.0265], (-0.0265, 1.286], (-0.026
5, 1.286], ..., (-1.187, -0.0265], (-1.187, -0.0265], (-2.95, -1.187], (-0.0265,
1.286], (-1.187, -0.0265]]
Length: 1000
Categories (4, interval[float64]): [(-2.95, -1.187] < (-1.187, -0.0265] < (-0.026
5, 1.286] <
(1.286, 3.928]]
在之后的章节我们还会用到cut和qcut,这些离散函数对于量化和群聚分析很有用。
6 Detecting and Filtering Outliers(检测和过滤异常值)
过滤或转换异常值是数组操作的一个重头戏。下面的DataFrame有正态分布的数据:
In [92]: data = pd.DataFrame(np.random.randn(1000, 4))
In [93]: data.describe()
Out[93]:
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.049091 0.026112 -0.002544 -0.051827
std 0.996947 1.007458 0.995232 0.998311
min -3.645860 -3.184377 -3.745356 -3.428254
25% -0.599807 -0.612162 -0.687373 -0.747478
50% 0.047101 -0.013609 -0.022158 -0.088274
75% 0.756646 0.695298 0.699046 0.623331
max 2.653656 3.525865 2.735527 3.366626
假设我们想要找一个列中,绝对值大于3的数字:
In [94]: col = data[2]
In [95]: col[np.abs(col) > 3]
Out[95]:
41 -3.399312
136 -3.745356
Name: 2, dtype: float64
选中所有绝对值大于3的行,可以用any方法在一个boolean DataFrame上:
In [96]: data[(np.abs(data) > 3).any(1)] # any中axis=1表示column
Out[96]:
0 1 2 3
41 0.457246 -0.025907 -3.399312 -0.974657
60 1.951312 3.260383 0.963301 1.201206
136 0.508391 -0.196713 -3.745356 -1.520113
235 -0.242459 -3.056990 1.918403 -0.578828
258 0.682841 0.326045 0.425384 -3.428254
322 1.179227 -3.184377 1.369891 -1.074833
544 -3.548824 1.553205 -2.186301 1.277104
635 -0.578093 0.193299 1.397822 3.366626
782 -0.207434 3.525865 0.283070 0.544635
803 -3.645860 0.255475 -0.549574 -1.907459
根据数据的值是正还是负,np.sign(data)可以生成1和-1:
In [99]: np.sign(data).head()
Out[99]:
0 1 2 3
0 -1.0 1.0 -1.0 1.0
1 1.0 -1.0 1.0 -1.0
2 1.0 1.0 1.0 -1.0
3 -1.0 -1.0 1.0 -1.0
4 -1.0 1.0 -1.0 -1.0
根据这些条件,就可以对值进行设置。下面的代码可以将值限制在区间-3到3以内:
In [97]: data[np.abs(data) > 3] = np.sign(data) * 3
In [98]: data.describe()
Out[98]:
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean 0.050286 0.025567 -0.001399 -0.051765
std 0.992920 1.004214 0.991414 0.995761
min -3.000000 -3.000000 -3.000000 -3.000000
25% -0.599807 -0.612162 -0.687373 -0.747478
50% 0.047101 -0.013609 -0.022158 -0.088274
75% 0.756646 0.695298 0.699046 0.623331
max 2.653656 3.000000 2.735527 3.000000
7 Permutation and Random Sampling(排列和随机采样)
排列(随机排序)一个series或DataFrame中的row,用numpy.random.permutation函数很容易就能做到。调用permutation的时候设定好你想要进行排列的axis,会产生一个整数数组表示新的顺序:
In [100]: df = pd.DataFrame(np.arange(5 * 4).reshape((5, 4)))
In [101]: sampler = np.random.permutation(5)
In [102]: sampler
Out[102]: array([3, 1, 4, 2, 0])
这个数组能被用在基于iloc上的indexing或take函数:
In [103]: df
Out[103]:
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
In [104]: df.take(sampler)
Out[104]:
0 1 2 3
3 12 13 14 15
1 4 5 6 7
4 16 17 18 19
2 8 9 10 11
0 0 1 2 3
为了选中一个随机的子集,而且没有代替功能(既不影响原来的值,返回一个新的series或DataFrame),可以用sample方法:
In [105]: df.sample(n=3)
Out[105]:
0 1 2 3
3 12 13 14 15
4 16 17 18 19
2 8 9 10 11
如果想要生成的样本带有替代功能(即允许重复),给sample中设定replace=True:
In [106]: choices = pd.Series([5, 7, -1, 6, 4])
In [107]: draws = choices.sample(n=10, replace=True)
In [108]: draws
Out[108]:
4 4
1 7
4 4
2 -1
0 5
3 6
1 7
4 4
0 5
4 4
dtype: int64
8 Computing Indicator/Dummy Variables(计算指示器/虚拟变量)
Dummy Variables:虚拟变量,又称虚设变量、名义变量或哑变量,用以反映质的属性的一个人工变量,是量化了的自变量,通常取值为0或1。
另一种在统计模型上的转换或机器学习应用是把一个categorical variable(类别变量)变为一个dummy or indicator matrix(虚拟或指示器矩阵)。如果DataFrame中的一列有k个不同的值,我们可以用一个矩阵或DataFrame用k列来表示,1或0。pandas有一个get_dummies函数实现这个工作,当然,你自己设计一个其实也不难。这里举个例子:
In [109]: df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],
.....: 'data1': range(6)})
In [110]: pd.get_dummies(df['key'])
Out[110]:
a b c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 0
在一些情况里,如果我们想要给column加一个prefix, 可以用data.get_dummies里的prefix参数来实现:
In [11]: dummies = pd.get_dummies(df['key'], prefix='key')
In [12]: dummies
Out[12]:
key_a key_b key_c
0 0 1 0
1 0 1 0
2 1 0 0
3 0 0 1
4 1 0 0
5 0 1 0
In [13]: df_with_dummy = df[['data1']].join(dummies)
...: df_with_dummy
Out[13]:
data1 key_a key_b key_c
0 0 0 1 0
1 1 0 1 0
2 2 1 0 0
3 3 0 0 1
4 4 1 0 0
5 5 0 1 0
如果DataFrame中的a row属于多个类别,事情会变得复杂一些。我们来看一下MoviesLens 1M 数据集:
In [114]: mnames = ['movie_id', 'title', 'genres']
In [115]: movies = pd.read_table('datasets/movielens/movies.dat', sep='::',
.....: header=None, names=mnames)
In [116]: movies[:10]
Out[116]:
movie_id title genres
0 1 Toy Story (1995) Animation|Children's|Comedy
1 2 Jumanji (1995) Adventure|Children's|Fantasy
2 3 Grumpier Old Men (1995) Comedy|Romance
3 4 Waiting to Exhale (1995) Comedy|Drama
4 5 Father of the Bride Part II (1995) Comedy
5 6 Heat (1995) Action|Crime|Thriller
6 7 Sabrina (1995) Comedy|Romance
7 8 Tom and Huck (1995) Adventure|Children's
8 9 Sudden Death (1995)
Action
9 10 GoldenEye (1995) Action|Adventure|Thriller
给每个genre添加一个指示变量比较麻烦。首先我们先取出所有不同的类别:
In [117]: all_genres = []
In [118]: for x in movies.genres:
.....: all_genres.extend(x.split('|')) #",|;"按,或;来分隔 ; "|"等同于"",空或空的意思
In [119]: genres = pd.unique(all_genres) #不重复的
In [120]: genres
Out[120]:
array(['Animation', "Children's", 'Comedy', 'Adventure', 'Fantasy',
'Romance', 'Drama', 'Action', 'Crime', 'Thriller','Horror',
'Sci-Fi', 'Documentary', 'War', 'Musical', 'Mystery', 'Film-Noir',
'Western'], dtype=object)
一种构建indicator dataframe的方法是先构建一个全是0的DataFrame:
In [121]: zero_matrix = np.zeros((len(movies), len(genres)))
In [122]: dummies = pd.DataFrame(zero_matrix, columns=genres)
In:dummies.head()
Out:
Animation Children's Comedy Adventure Fantasy Romance Drama Action Crime Thriller Horror Sci-Fi Documentary War Musical Mystery Film-Noir Western
0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
1 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
2 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
3 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
4 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
然后迭代每一部movie,并设置每一行中的dummies为1。使用dummies.columns来计算每一列的genre的指示器:
In [123]: gen = movies.genres[0]
In [124]: gen.split('|')
Out[124]: ['Animation', "Children's", 'Comedy']
In [125]: dummies.columns.get_indexer(gen.split('|'))
Out[125]: array([0, 1, 2])
然后,使用.iloc,根据索引来设定值:
In [126]: for i, gen in enumerate(movies.genres):
.....: indices = dummies.columns.get_indexer(gen.split('|'))
.....: dummies.iloc[i, indices] = 1
.....:
然后,和以前一样,再将其与movies合并起来:
In [127]: movies_windic = movies.join(dummies.add_prefix('Genre_'))
In [128]: movies_windic.iloc[0]
Out[128]:
movie_id 1
title Toy Story (1995)
genres Animation|Children's|Comedy
Genre_Animation 1
Genre_Children's 1
Genre_Comedy 1
Genre_Adventure 0
Genre_Fantasy 0
Genre_Romance 0
Genre_Drama 0
...
Genre_Crime 0
Genre_Thriller 0
Genre_Horror 0
Genre_Sci-Fi 0
Genre_Documentary 0
Genre_War 0
Genre_Musical 0
Genre_Mystery 0
Genre_Film-Noir 0
Genre_Western 0
Name: 0, Length: 21, dtype: object
对于一个很大的数据集,这种构建多个成员指示变量的方法并不会加快速度。写一个低层级的函数来直接写一个numpy array,并把写过整合到DataFrame会更快一些。
一个有用的recipe诀窍是把get_dummies和离散函数(比如cut)结合起来:
In [129]: np.random.seed(12345)
In [130]: values = np.random.rand(10)
In [131]: values
Out[131]:
array([ 0.9296, 0.3164, 0.1839, 0.2046, 0.5677, 0.5955, 0.9645,
0.6532, 0.7489, 0.6536])
In [132]: bins = [0, 0.2, 0.4, 0.6, 0.8, 1]
In [133]: pd.get_dummies(pd.cut(values, bins))
Out[133]:
(0.0, 0.2] (0.2, 0.4] (0.4, 0.6] (0.6, 0.8] (0.8, 1.0]
0 0 0 0 0 1
1 0 1 0 0 0
2 1 0 0 0 0
3 0 1 0 0 0
4 0 0 1 0 0
5 0 0 1 0 0
6 0 0 0 0 1
7 0 0 0 1 0
8 0 0 0 1 0
9 0 0 0 1 0
我们用numpy.random.seed,使这个例子具有确定性。本书后面会介绍pandas.get_dummies。
7.3 String Manipulation(字符串处理)
python很多内建方法很适合处理string。而且对于更复杂的模式,可以配合使用正则表达式。而pandas则混合了两种方式。
1 String Object Methods(字符串对象方法)
大部分string处理,使用内建的一些方法就足够了。比如,可以用split来分割用逗号区分的字符串:
In [134]: val = 'a,b, guido'
In [135]: val.split(',')
Out[135]: ['a', 'b', ' guido']
split常常与strip一起使用,以去除空白符(包括换行符):
In [136]: pieces = [x.strip() for x in val.split(',')]
In [137]: pieces
Out[137]: ['a', 'b', 'guido']
利用加法,可以将这些子字符串以双冒号分隔符的形式连接起来:
In [138]: first, second, third = pieces
In [139]: first + '::' + second + '::' + third
Out[139]: 'a::b::guido'
但这种方法并不python,更快的方法是直接用join方法:
In [140]: '::'.join(pieces)
Out[140]: 'a::b::guido'
其他一些方法适合锁定子字符串位置相关的。用in关键字是检测substring最好的方法,当然,index和find也能完成任务:
In [141]: 'guido' in val
Out[141]: True
In [142]: val.index(',')
Out[142]: 1
In [143]: val.find(':')
Out[143]: -1
注意index和find的区别。如果要找的string不存在的话,index会报错。而find会返回-1:
In [144]: val.index(':')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
in ()
----> 1 val.index(':')
ValueError: substring not found
count会返回一个substring出现的次数:
In [145]: val.count(',')
Out[145]: 2
replace会取代一种出现方式(pattern)。也通常用于删除pattern,传入一个空字符串即可:
In [146]: val.replace(',', '::')
Out[146]: 'a::b:: guido'
In [147]: val.replace(',', '')
Out[147]: 'ab guido'
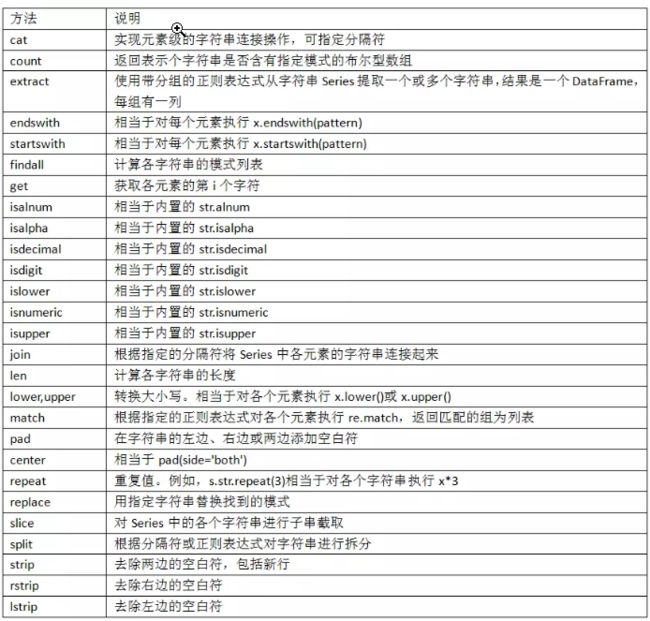
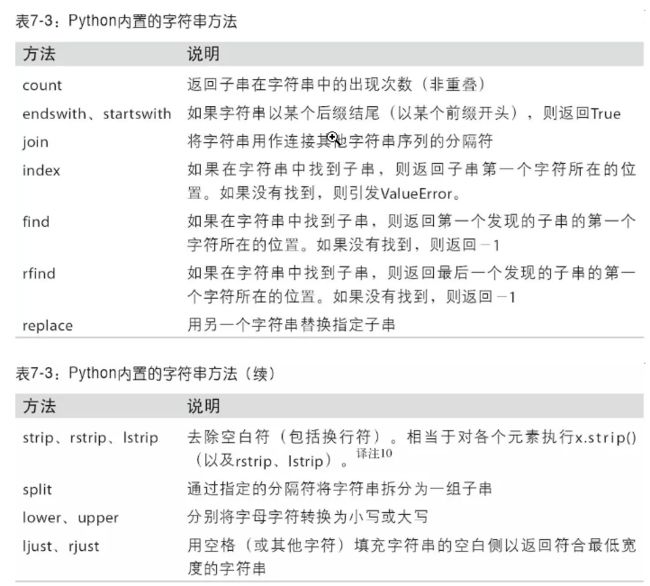
表7-3列出了Python内置的字符串方法。
这些运算大部分都能使用正则表达式实现(马上就会看到)。
2 Regular Expressions(正则表达式)
正则表达式提供了一种灵活的在文本中搜索或匹配(通常比前者复杂)字符串模式的方式。正则表达式能让我们寻找更复杂的pattern。通常称一个表达式为regex,由正则表达语言来代表一个字符串模式。可以使用python内建的re模块来使用。
关于正则表达式,有很多教学资源,可以自己找几篇来学一些,这里不会介绍太多。
re模块有以下三个类别:patther matching(模式匹配), substitution(替换), splitting(分割)。通常这三种都是相关的,一个regex用来描述一种pattern,这样会有很多种用法。这里举个例子,假设我们想要根据空格(tabs,spaces,newlines)来分割一个字符串。用于描述一个或多个空格的regex是\s+:
In [148]: import re
In [149]: text = "foo bar\t baz \tqux"
In [150]: re.split('\s+', text)
Out[150]: ['foo', 'bar', 'baz', 'qux']
如果想要得到符合regex的所有结果,以一个list结果返回,可以使用findall方法:
In [153]: regex.findall(text)
Out[153]: [' ', '\t ', ' \t']
为了防止\在正则表达式中的逃逸,推荐使用raw string literal,比如r'C:\x',而不是使用'C:\x
如果打算对许多字符串应用同一条正则表达式,强烈建议通过re.compile创建regex对象。这样将可以节省大量的CPU时间。
match和search,与findall关系紧密。不过findall会返回所有匹配的结果,而search只会返回第一次匹配的结果。更严格地说,match只匹配string开始的部分。这里举个例子说明,我们想要找到所有的邮件地址:
text = """Dave [email protected]
Steve [email protected]
Rob [email protected]
Ryan [email protected]
"""
pattern = r'[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,4}'
#具有正则表达式的电子邮件[A-Z0-9 ._%+ - ] + @ [A-Z0-9 .-] {3,65} \。[AZ] {2,4}
# re.IGNORECASE makes the regex case-insensitive
regex = re.compile(pattern, flags=re.IGNORECASE)
对text使用findall将得到一组电子邮件地址:
In [155]: regex.findall(text)
Out[155]:
['[email protected]',
'[email protected]',
'[email protected]',
'[email protected]']
search返回text中的第一个匹配结果。match object能告诉我们找到的结果在text中开始和结束的位置:
In [156]: m = regex.search(text)
In [157]: m
Out[157]: <_sre.SRE_Match object; span=(5, 20), match='[email protected]'>
In [158]: text[m.start():m.end()]
Out[158]: '[email protected]'
regex.match返回None,因为它只会在pattern存在于stirng开头的情况下才会返回匹配结果:
In [159]: print(regex.match(text))
None
而sub返回一个新的string,把pattern出现的地方替换为我们指定的string:
In [160]: print(regex.sub('REDACTED', text))
Dave REDACTED
Steve REDACTED
Rob REDACTED
Ryan REDACTED
假设你想要找到邮件地址,同时,想要把邮件地址分为三个部分,username, domain name, and domain suffix.(用户名,域名,域名后缀)。需要给每一个pattern加一个括号:
In [161]: pattern = r'([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\.([A-Z]{2,4})'
In [162]: regex = re.compile(pattern, flags=re.IGNORECASE)
由这种修改过的正则表达式所产生的匹配项对象,可以通过其groups方法返回一个由模式各段组成的元组:
In [163]: m = regex.match('[email protected]')
In [164]: m.groups()
Out[164]: ('wesm', 'bright', 'net')
对于带有分组功能的模式,findall会返回一个元组列表:
In [165]: regex.findall(text)
Out[165]:
[('dave', 'google', 'com'),
('steve', 'gmail', 'com'),
('rob', 'gmail', 'com'),
('ryan', 'yahoo', 'com')]
sub还能通过诸如\1、\2之类的特殊符号访问各匹配项中的分组。符号\1对应第一个匹配的组,\2对应第二个匹配的组,以此类推:
In [166]: print(regex.sub(r'Username: \1, Domain: \2, Suffix: \3', text))
Dave Username: dave, Domain: google, Suffix: com
Steve Username: steve, Domain: gmail, Suffix: com
Rob Username: rob, Domain: gmail, Suffix: com
Ryan Username: ryan, Domain: yahoo, Suffix: com

3 Vectorized String Functions in pandas(pandas中的字符串向量化函数)
一些复杂的数据清理中,string会有缺失值:
import numpy as np
import pandas as pd
In [167]: data = {'Dave': '[email protected]', 'Steve': '[email protected]',
.....: 'Rob': '[email protected]', 'Wes': np.nan}
In [168]: data = pd.Series(data)
In [169]: data
Out[169]:
Dave [email protected]
Rob [email protected]
Steve [email protected]
Wes NaN
dtype: object
In [170]: data.isnull()
Out[170]:
Dave False
Rob False
Steve False
Wes True
dtype: bool
可以把一些字符串方法和正则表达式(用lambda或其他函数)用于每一个value上,通过data.map,但是这样会得到NA(null)值。为了解决这个问题,series有一些数组导向的方法可以用于字符串操作,来跳过NA值。这些方法可以通过series的str属性;比如,我们想检查每个电子邮箱地址是否有'gmail' with str.contains:
In [171]: data.str.contains('gmail')
Out[171]:
Dave False
Rob True
Steve True
Wes NaN
dtype: object
正则表达式也可以用,配合任意的re选项,比如IGNORECASE:
In [172]: pattern
Out[172]: '([A-Z0-9._%+-]+)@([A-Z0-9.-]+)\\.([A-Z]{2,4})'
In [173]: data.str.findall(pattern, flags=re.IGNORECASE)
Out[173]:
Dave [(dave, google, com)]
Rob [(rob, gmail, com)]
Steve [(steve, gmail, com)]
Wes NaN
dtype: object
有很多方法用于向量化。比如str.get或index索引到str属性:
In [176]: matches.str.get(1) #数字代表括号里第几个,get第几个字符
Out[176]:
Dave NaN
Rob NaN
Steve NaN
Wes NaN
dtype: float64
In [177]: matches.str[0]
Out[177]:
Dave NaN
Rob NaN
Steve NaN
Wes NaN
dtype: float64
你可以利用这种方法对字符串进行截取:
In [178]: data.str[:5]
Out[178]:
Dave dave@
Rob rob@g
Steve steve
Wes NaN
dtype: object