【菜菜的CV进阶之路-神经网络的深入理解-十三】反向传播背后的四个基本等式
目录
简介
| 第一章-使用神经网络识别手写数字 第一节-感知机 第二节-sigmoid神经元 第三节-神经网络的结构 第四节-用简单的神经网络识别手写数字 第五节-通过梯度下降法学习参数 第六节-实现我们的手写体数字分类神经网络 第七节-向深度学习进发! |
| 第二章-反向传播算法工作原理 第一节-热身:一个基于矩阵的快速计算神 经网络输出的方法 第二节-关于代价函数的两个假设 第三节-Hadamard积--s⊙t 第四节-反向传播背后的四个基本等式 第五节-四个基本方程的证明(自选章节) 第六节-反向传播算法 第七节-反向传播算法代码 第八节-为什么说反向传播算法很高效? 第九节-反向传播:整体描述 |
注:
哈工大原版翻译地址:https://hit-scir.gitbooks.io/neural-networks-and-deep-learning-zh_cn/content/
文章原版地址:《Neural Networks and Deep Learning》http://neuralnetworksanddeeplearning.com/
反向传播(backpropagation)能够帮助解释网络的权重和偏置的改变是如何改变代价函数的。归根结底,它的意思是指计算偏导数 ![]() 和
和![]() 。但是为了计算这些偏导数,我们首先介绍一个中间量,
。但是为了计算这些偏导数,我们首先介绍一个中间量,![]() ,我们管它叫做
,我们管它叫做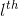 层的
层的![]() 神经元的错误量(error)。反向传播会提供给我们一个用于计算错误量的流程,能够把
神经元的错误量(error)。反向传播会提供给我们一个用于计算错误量的流程,能够把![]() 和
和![]() 、
、![]() 关联起来。
关联起来。
为了理解错误量是如何定义的,想象一下在我们的神经网络中有一个恶魔:
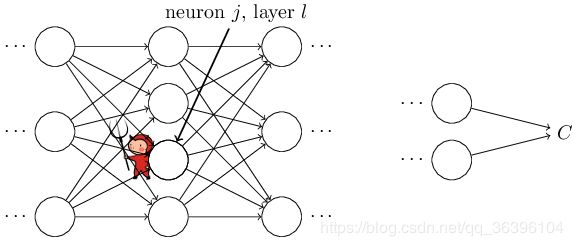
这个恶魔位于层的![]() 神经元。当神经元的输入进入时,这个恶魔扰乱神经元的操作。它给神经元的加权输入添加了一点改变
神经元。当神经元的输入进入时,这个恶魔扰乱神经元的操作。它给神经元的加权输入添加了一点改变![]() ,这就导致了神经元的输出变成了
,这就导致了神经元的输出变成了![]() ,而不是之前的
,而不是之前的![]() 。这个改变在后续的网络层中传播,最终使全部代价改变了
。这个改变在后续的网络层中传播,最终使全部代价改变了![]() 。
。
而今,这个恶魔变成了一个善良的恶魔,它试图帮助你改善代价,比如,它试图找到一个![]() 能够让代价变小。假设
能够让代价变小。假设![]() 是一个很大的值(或者为正或者为负)。然后这个善良的恶魔可以通过选择一个和
是一个很大的值(或者为正或者为负)。然后这个善良的恶魔可以通过选择一个和![]() 符号相反的
符号相反的![]() 使得代价降低。相比之下,如果
使得代价降低。相比之下,如果![]() 接近于0,那么这个恶魔几乎不能通过扰乱加权输入
接近于0,那么这个恶魔几乎不能通过扰乱加权输入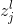 改善多少代价。在一定范围内这个善良的恶魔就可以分辨出,这个神经元已经接近于最佳状态。至此,有了一种启发式的感觉:
改善多少代价。在一定范围内这个善良的恶魔就可以分辨出,这个神经元已经接近于最佳状态。至此,有了一种启发式的感觉:![]() 可以用来衡量神经元里的错误量。
可以用来衡量神经元里的错误量。
当然,这只是针对很小的![]() 来说的。我们会做出假设来限制恶魔只能做出很小的变化。
来说的。我们会做出假设来限制恶魔只能做出很小的变化。
受到这个故事的促动,我们定义l层第j个神经元的错误量![]() 为:
为:

按照通常的习惯,我们使用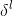 来表示与l层相关联的错误量的向量。反向传播将会带给我们一个计算每一层的方法,然后把这些错误量联系到我们真正感兴趣的量:
来表示与l层相关联的错误量的向量。反向传播将会带给我们一个计算每一层的方法,然后把这些错误量联系到我们真正感兴趣的量:![]() 和
和![]() 。你可能想知道为什么恶魔一直在更改加权输入。的确,更加自然的想法是,这个恶魔更改的是输出激活量
。你可能想知道为什么恶魔一直在更改加权输入。的确,更加自然的想法是,这个恶魔更改的是输出激活量![]() ,然后我们就可以使用
,然后我们就可以使用![]() 来衡量错误。事实上如果你这么做,就会得到和之后的讨论十分相似的结果,但结果会使反向传播的代数形式变得复杂。所以我们会继续使用
来衡量错误。事实上如果你这么做,就会得到和之后的讨论十分相似的结果,但结果会使反向传播的代数形式变得复杂。所以我们会继续使用![]() 用于衡量错误。
用于衡量错误。
在例如MNIST的分类问题中,术语"错误量(error)"通常用于表示分类的错误率(failure rate)。例如,如果神经网络的数字分类准确率是96.0%,那么错误率就是4.0%。显然,它和我们的δ向量在概念上有一些不同。实际上,在上下文环境中你可以分辨出使用的是哪个意思。
进攻计划:反向传播基于四个基本等式。这些等式带给我们一个计算错误量![]() 以及代价函数的梯度的方法。下面我会说明这四个等式。尽管如此,我在这里要告诫各位一下:不要期望立刻吸收理解这四个等式。你的这种期望会带失望的。事实上,反向传播的这几个等式内容很多,理解它们需要一定的时间和耐心,随着你会逐渐深入的探索才会真正理解。所以本部分的讨论也只是一个开端,旨在帮助你在未来的道路上彻底理解这些等式。
以及代价函数的梯度的方法。下面我会说明这四个等式。尽管如此,我在这里要告诫各位一下:不要期望立刻吸收理解这四个等式。你的这种期望会带失望的。事实上,反向传播的这几个等式内容很多,理解它们需要一定的时间和耐心,随着你会逐渐深入的探索才会真正理解。所以本部分的讨论也只是一个开端,旨在帮助你在未来的道路上彻底理解这些等式。
我们将在本章的后续内容更加深入地探索这些等式,现在先预览一下这些方法:我将给出这些等式的简短证明,帮助解释为什么它们是正确的;我们将要以伪代码的算法形式重新阐述一下这些等式,然后再看一下这些伪代码是如何通过Python代码实现的;在本章的最后一部分,我们将会开发一个直观的图片用来解释反向传播的这些等式是什么意思、一个人如何从零开始发现这些等式。在这些过程中,我们会重复提到四个基本等式,这样你也会加深对这些等式的理解,它们会变得舒服,甚至有可能变得漂亮而且自然。
输出层中关于错误量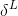 的等式,:的构成为
的等式,:的构成为

这是一种非常自然的表达。右侧的第一项![]() ,就是用于测量
,就是用于测量![]() 输出激活代价改变有多快的函数。举个例子,如果C并不太依赖于某个特别的输出神经元j,那么就会很小,这是我们所期望的。右侧的第二项
输出激活代价改变有多快的函数。举个例子,如果C并不太依赖于某个特别的输出神经元j,那么就会很小,这是我们所期望的。右侧的第二项![]() ,用于测量
,用于测量![]() 处的激活函数σ改变有多快。
处的激活函数σ改变有多快。
你应该注意到(BP1)中的每一项都是容易计算的。特别的,当计算神经网络的行为时就计算了![]() ,而计算
,而计算![]() 也仅仅是一小部分额外的开销。当然了,
也仅仅是一小部分额外的开销。当然了,![]() 的确切形式依赖于代价函数的形式。然而,如果提供了代价函数,大家也应该知道计算
的确切形式依赖于代价函数的形式。然而,如果提供了代价函数,大家也应该知道计算![]() 也不会有什么困难。举个例子,如果我们使用平方代价函数,即
也不会有什么困难。举个例子,如果我们使用平方代价函数,即![]() ,那么
,那么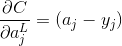 ,这显然很容易计算。
,这显然很容易计算。
等式(BP1)是的分量形式。它是一个完美的表达式,但并不是我们想要的基于矩阵的形式,那种矩阵形式可以很好的用于反向传播。然而,我们可以很容易把等式重写成基于矩阵的形式,就像:
![]()
其中,![]() 是一个向量,它是由
是一个向量,它是由![]() 组成的。你可以把
组成的。你可以把![]() 看做现对于输出激活的C的改变速率。很容易看出来等式(BP1)和(BP1a)是等价的,基于这个原因我们从现在开始将使用(BP1)交替地指代两个等式。举个例子,在使用平方代价函数的情况下我们有
看做现对于输出激活的C的改变速率。很容易看出来等式(BP1)和(BP1a)是等价的,基于这个原因我们从现在开始将使用(BP1)交替地指代两个等式。举个例子,在使用平方代价函数的情况下我们有![]() ,所以完整的基于矩阵的(BP1)的形式变为:
,所以完整的基于矩阵的(BP1)的形式变为:
![]()
就像你所看到的,表达式里的每一项都拥有一个漂亮的向量形式,并且很容易使用一个库来计算,比如Numpy。
依据下一层错误量![]() 获取错误量的等式:
获取错误量的等式:
![]()
其中,![]() 是
是![]() 层的权重矩阵
层的权重矩阵![]() 的转置。这个等式看着有些复杂,但是每一项都有很好的解释。假设我们知道
的转置。这个等式看着有些复杂,但是每一项都有很好的解释。假设我们知道![]() 层的错误量
层的错误量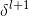 。当我们使用转置权值矩阵
。当我们使用转置权值矩阵![]() 的时候,我们可以凭借直觉认为将错误反向(backward)移动穿过网络,带给我们某种测量层输出的错误量方法。然后我们使用Hadamard乘积
的时候,我们可以凭借直觉认为将错误反向(backward)移动穿过网络,带给我们某种测量层输出的错误量方法。然后我们使用Hadamard乘积![]() 。这就是将错误量反向移动穿过l层的激活函数,产生了l层的加权输入的错误量
。这就是将错误量反向移动穿过l层的激活函数,产生了l层的加权输入的错误量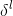 。
。
通过结合(BP2)和(BP1)我们可以计算网络中任意一层的错误量。我们开始使用(BP1)来计算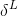 ,然后应用等式(BP2)来计算
,然后应用等式(BP2)来计算![]() ,然后再次应用等式(BP2)来计算
,然后再次应用等式(BP2)来计算![]() ,以此类推,反向通过网络中的所有路径。
,以此类推,反向通过网络中的所有路径。
网络的代价函数相对于偏置的改变速率的等式:

也就是说,错误量![]() 完全等于改变速率
完全等于改变速率![]() 。这是一个很好的消息,因为(BP1)和(BP2)已经告诉我们如何计算
。这是一个很好的消息,因为(BP1)和(BP2)已经告诉我们如何计算![]() 。我们把(BP3)重写成如下的简略形式:
。我们把(BP3)重写成如下的简略形式:

这可以理解成δ可以和偏置b在相同的神经元中被估计。
网络的代价函数相对于权重的改变速率的等式:

这个等式告诉我们如何依据和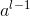 来计算偏导
来计算偏导![]() ,而这两个量我们已经知道如何计算了。这个等式可以重写成如下含有少量下标的形式:
,而这两个量我们已经知道如何计算了。这个等式可以重写成如下含有少量下标的形式:

可以这么理解,![]() 是神经元的激活量,输入到权重w中,
是神经元的激活量,输入到权重w中,![]() 是神经元的错误量,从权重w输出。观察这个权重w,两个神经元通过这个权重连接起来,我们可以这样描画出来:
是神经元的错误量,从权重w输出。观察这个权重w,两个神经元通过这个权重连接起来,我们可以这样描画出来:
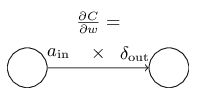
等式(32)的一个很好的结论是当激活量![]() 很小的时候,
很小的时候,![]() ≈0,梯度项
≈0,梯度项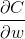 也将会趋近于很小。在这种情况下,我们说权重学习得很慢,也就是说在梯度下降的时候并没有改变很多。换而言之,等式(BP4)的一个结果就是从低激活量神经元里输出的权重会学习缓慢。
也将会趋近于很小。在这种情况下,我们说权重学习得很慢,也就是说在梯度下降的时候并没有改变很多。换而言之,等式(BP4)的一个结果就是从低激活量神经元里输出的权重会学习缓慢。
按照这样的思路,我们可以从(BP1)-(BP4)中获得另外一些见解。让我们从输出层开始看起。考虑(BP1)中的项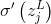 。回想一下上一章sigmoid函数的图像,当
。回想一下上一章sigmoid函数的图像,当![]() 的值大约是0或1的时候σ函数的图像非常平缓。这时,我们将有≈0。这告诉我们的是,如果输出神经元是低激活量(≈0)或高激活量(≈1)的时候,最后一层的权重将会学习缓慢。在这种情况下,我们通常说输出神经元已经饱和(saturated),结果就是权重停止了学习(或者说是学习缓慢)。输出层中的偏置也有类似的结论。
的值大约是0或1的时候σ函数的图像非常平缓。这时,我们将有≈0。这告诉我们的是,如果输出神经元是低激活量(≈0)或高激活量(≈1)的时候,最后一层的权重将会学习缓慢。在这种情况下,我们通常说输出神经元已经饱和(saturated),结果就是权重停止了学习(或者说是学习缓慢)。输出层中的偏置也有类似的结论。
我们可以在早期的层中获得类似的见解。特别的,关注一下(BP2)中的![]() 项。如果神经元接近饱和
项。如果神经元接近饱和![]() 也可能变小。相应地,意味着任何一个输入到饱和神经元的权重都会学习缓慢。
也可能变小。相应地,意味着任何一个输入到饱和神经元的权重都会学习缓慢。
这个结论不一定成立,因为当![]() 的值非常大时,可以弥补比较小的
的值非常大时,可以弥补比较小的![]() 。我只是表达了一种笼统的趋势。
。我只是表达了一种笼统的趋势。
总结一下,我们获得的结论是:如果输入神经元是低激活量的,或者输出神经元已经饱和(高激活量或低激活量),那么权重就会学习得缓慢。
这些观察结果并不会令我们过于惊讶。并且它们仍然有助于我们理解在神经网络学习的过程中发生了什么。此外,我们可以把这样的推理应用在其它相关的地方。这四个基本的等式在使用任何激活函数的情况下都是成立的,不仅仅是标准的sigmoid函数(这是因为,就像我们待会看到的,证明的过程并没有使用sigma特别的属性)。所以我们可以利用这些等式来设计激活函数,使这些函数具有特殊目的的学习特性。给你举个例子吧,假设我们将要选择一个激活函数(非sigmoid)σ,使得σ′总为正,并且始终不接近0。这就阻止了学习缓慢,而这是在原始sigmoid神经元饱和时会发生的。在本书的后面我们将看到一些例子,在这些例子中我们将会对激活函数做出这一类修改。把(BP1)-(BP4)记在心里,这将有助于解释会什么要尝试这样的修改,以及这会造成什么影响。

问题
- 反向传播等式的另一种表示方法:我使用了Hadamard积给出了反向传播等式(BP1)和(BP2)。如果你不熟悉Hadamard积,这样的表示可能会让你感到不习惯。我们可以使用基于传统矩阵乘法的方法来替代这种记法,有些读者可能更喜欢这种记法。(1)将(BP1)重写为
![]()
其中![]() 是一个方阵,它的对角元素的值依次是
是一个方阵,它的对角元素的值依次是![]() ,非对角元素都是0。注意到我们使用了传统的矩阵乘法将这个矩阵和
,非对角元素都是0。注意到我们使用了传统的矩阵乘法将这个矩阵和![]() 相乘。(2)将(BP2)重写为
相乘。(2)将(BP2)重写为
![]()
(3)将(1)和(2)组合起来,得到
![]()
对于习惯矩阵乘法的读者来说,这个等式可能比(BP1)和(BP2)更容易理解。我坚持使用(BP1)和(BP2)的原因是那样的记法在数值上能够更快地被实现。