【深度学习NLP论文笔记】《Greedy Attack and Gumbel Attack: Generating Adversarial Example for Discrete Data》

这篇文章的数学定义推导和算法说明部分大都没有看懂,所以笔记写得极烂,因为文中很多数学定义相当模糊,写得也很绕。在ICLR2019评审中一位盲审直接给出“poorly written”的意见。ICLR2019 OpenReview 但这篇大概率还是会中,原作者也更新了一版论文,待评审结果出来我会试着重新更新该笔记,先占个坑。
Abstract
我们提出一种【对离散数据进行对抗攻击】的概率框架(probabilistic framework)。基于这个框架,可以得到两种方法:
-
基于扰动的方法(perturbation-based method):贪婪攻击(Greedy Attack)
-
基于可扩展学习的方法(scalable learning-based method):Gumbel Attack
我们使用单词级CNN(word-based CNN),字符级CNN(character-based CNN)和LSTM进行试验。
通过贪婪攻击只修改5个字符,使基于字符的CNN的分类准确率下降到随机选择的水平。
1、Introduction
相关有价值的工作:
-
《Visualizing and understanding neural models in nlp》Li et al.提出通过寻找词嵌入的最大梯度(the largest gradient magnitude of embedding),找到最顶层的特征(top features)。
-
《Crafting adversarial input sequences for recurrent neural networks.》 Papernot et al.提出通过改变梯度的符号来对每个特征进行扰动,再以此随机改变选择的输入特征(selected features of an input)
-
《Black-box generation of adversarial text sequences to evade deep learning classifiers》 Gao et al.开发了一个适用于序列数据(sequence data)的评分系统(scoring functions),并提出修改由评分系统选择的字符级特征(characters of the features)
-
《Adversarial examples for evaluating reading comprehension systems》 Jia and Liang提出在样本中插入注意力分散语句(distraction sentences)来欺骗阅读理解系统(reading comprehension system)
-
《Towards crafting text adversarial samples》 Samanta and Mehta在做单词替换时加入了语言学约束(linguistic constraints)
我们提出了二级概率框架(two-stage probabilistic framework)来针对离散输入生成对抗样本。要被扰动的关键特征(key features)在第一阶段(first stage)被识别出;然后这些关键特征在第二阶段被加入扰动,通过选择预先生成的词典(a pre-fixed dictionary)中的值,来加入扰动。基于所提出的框架,我们导出了两种方法——Greedy Attack和Gumbel Attack。
-
Greedy Attack分两个阶段评估具有单特征扰动输入(single-feature pertubed inputs)的模型。而Gumbel Attack学习扰动的参数采样分布(parametric sampling distribution)。
-
Greedy Attack获得更高的成功率,而Gumbel Attack则需要较少的模型评估,从而提高实时或大规模攻击的效率

Table1比较了这两种方法和其他方法。
2、Framework
-
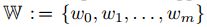 是一个离散空间,例如词典或者字符空间
是一个离散空间,例如词典或者字符空间 -
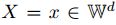 :输入随机变量。它是一个d维向量,其中的每个分量都属于
:输入随机变量。它是一个d维向量,其中的每个分量都属于
-
在此输入下,给定一个集合
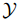 ,使集合中产生的输出Y满足条件分布
,使集合中产生的输出Y满足条件分布
-
假设存在
 ,可以作为对分类没有贡献的一个参考点,比如w0可以是文本分类中的补零点(zero padding)
,可以作为对分类没有贡献的一个参考点,比如w0可以是文本分类中的补零点(zero padding) -
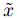 :扰动样本
:扰动样本 -
定义变量
 ,
,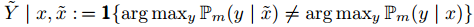 为攻击是否成功地指示变量(indicator variable)。攻击的目标是将给定样本x通过加扰变为
为攻击是否成功地指示变量(indicator variable)。攻击的目标是将给定样本x通过加扰变为 ,从而使
,从而使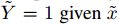 。
。
我们将扰动限制在x的k个特征上,通过两个阶段实现攻击。
-
第一个阶段找到对于x而言最重要的k个特征。
-
第二个阶段找到值来替换k个选择的特征。
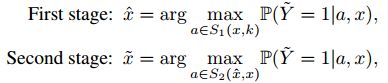
其中:
-
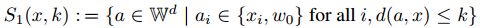 是包含与x最多k个位置不同的所有元素的集合,其中不同的特征总是取值w0。
是包含与x最多k个位置不同的所有元素的集合,其中不同的特征总是取值w0。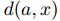 表示a和x不同的特征数。
表示a和x不同的特征数。【理解】:a是从x改动过来的,二者都是d维向量。改动的时候a的分量要么取x的对应分量(即
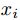 ),要么取
),要么取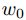 。a中改取
。a中改取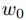 的个数不能超过k。
的个数不能超过k。first stage中
 的定义应该为
的定义应该为 。所以first stage的任务就是找a(然后记为
。所以first stage的任务就是找a(然后记为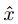 ),使得a和x被分成不同类的概率最大。
),使得a和x被分成不同类的概率最大。 -

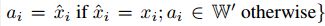 。
。 是由攻击者选出的一个子集。
是由攻击者选出的一个子集。【理解】:此时的a是由
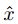 改动过来的,如果
改动过来的,如果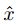 的第i个分量同x的第i个分量,则将其作为a的第i个分量。否则从
的第i个分量同x的第i个分量,则将其作为a的第i个分量。否则从 中挑选分量。将使分类改变概率最大的a记为
中挑选分量。将使分类改变概率最大的a记为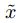
【整体理解】:first stage找特征,上文说了![]() 可以取补零点(大概就是0?),即相当于抹掉x中的不超过k个特征,使得分类改变概率最大。second stage在
可以取补零点(大概就是0?),即相当于抹掉x中的不超过k个特征,使得分类改变概率最大。second stage在![]() 中找新的特征,换到
中找新的特征,换到![]() 的位置,由此构建对抗样本。
的位置,由此构建对抗样本。
但是以上方法难以计算,所以提出了另一种表示形式:

-
 表示d维0-1矢量(其中1的个数为k)的空间(the space of d-dimensional zero-one vectors with k ones)。
表示d维0-1矢量(其中1的个数为k)的空间(the space of d-dimensional zero-one vectors with k ones)。【理解】:D空间中都是d维向量,向量的d个分量中有k个为1,剩下的d-k个分量为0.
-
G 是
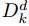 中的随机变量(也就是一个d维向量)
中的随机变量(也就是一个d维向量) -
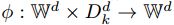 是一个函数,若
是一个函数,若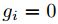 则
则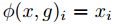 ;否则
;否则
在first stage中,令![]() ,其中G由以X为条件的分布生成。
,其中G由以X为条件的分布生成。
【理解】:按照上面的定义,X 是d维输入向量,G是d维0-1向量(其中k个1)。现在要用函数![]() 构造d维向量
构造d维向量![]() ,构造规则是:如果 G 中第i个分量为0,则
,构造规则是:如果 G 中第i个分量为0,则![]() 的第i个分量等于 X 的第i个分量;若 G 中第i个分量为1,则
的第i个分量等于 X 的第i个分量;若 G 中第i个分量为1,则![]() 的第i个分量为
的第i个分量为 ![]() 。
。
为了对![]() 增加一个约束,我们定义k个独立同分布的d维随机独热变量
增加一个约束,我们定义k个独立同分布的d维随机独热变量![]() 。令
。令![]() ,其中
,其中![]() 分别是
分别是![]() 的第i个变量。
的第i个变量。
【理解】:这里说的是G的生成。先根据X的分布生成k个d维独热变量,![]() 应该是其中一个。这个k个独热变量刚好有(?)k个位置为1.则将G的这k个位置也置1,其它位置置0.
应该是其中一个。这个k个独热变量刚好有(?)k个位置为1.则将G的这k个位置也置1,其它位置置0.
我们想要最大化![]() ,整个攻击方法是
,整个攻击方法是
![]()
通过类别分布(categorical distribution)![]() 可得到x的d个特征的等级(rank)。定义
可得到x的d个特征的等级(rank)。定义![]()
![]() 为定性函数(deterministic function),以此找出基于rank:
为定性函数(deterministic function),以此找出基于rank:![]() 的top k个特征
的top k个特征
【理解】:
-
目标函数:最大化
 被分为不同类的概率。
被分为不同类的概率。 -
约束条件:
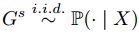 :
: 是基于X的独立同分布
是基于X的独立同分布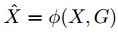 :
: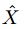 是通过
是通过 函数产生的
函数产生的
在second stage中
-
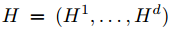 是一个d维随机变量,其中
是一个d维随机变量,其中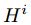 是集合
是集合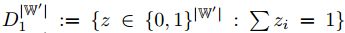 中一个随机的独热变量(
中一个随机的独热变量(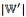 维)。
维)。 -
 为大小为k的[d]子集的集合
为大小为k的[d]子集的集合 -
 是一个函数,记为
是一个函数,记为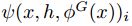 。若
。若 (
(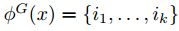 ),则函数值为
),则函数值为 ;否则为
;否则为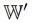 中与独热向量
中与独热向量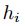 有关的值。
有关的值。 -
 为扰动输入,其中H由X的分布产生。我们对
为扰动输入,其中H由X的分布产生。我们对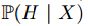 进行约束,要求
进行约束,要求 独立于X。我们要最大化
独立于X。我们要最大化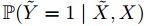 ,整体攻击方法是:
,整体攻击方法是:
![]()
通过类别分布![]() 可以得出为每个特征i从
可以得出为每个特征i从![]() 中选出的值的rank。x的扰动是基于
中选出的值的rank。x的扰动是基于![]() 的rank选出top k个特征
的rank选出top k个特征![]() 。每个选择的特征
。每个选择的特征![]() 都是依据
都是依据![]() 从
从![]() 中选出的。
中选出的。
3 Methods
3.1 Greedy Attack
![]() 是一个d维独热向量,其中第i个分量为1,为了解决公式3,我们将目标分解为:
是一个d维独热向量,其中第i个分量为1,为了解决公式3,我们将目标分解为:
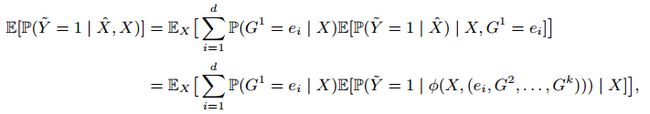
第二个等式是由独立假设推导出的。
然而![]() 很难计算,所以使用
很难计算,所以使用![]() 进行掩蔽,得到仅有第i个特征的输出(与
进行掩蔽,得到仅有第i个特征的输出(与![]() 相关),由此近似:
相关),由此近似:
![]()
其中![]() 用
用![]() 取代x的第i个特征。我们观察到若:
取代x的第i个特征。我们观察到若:
![]()
则近似目标(approximated objective)是最大化的。
同样的,我们分解公式4:
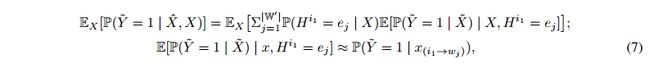
其中![]() 表示用
表示用![]() 取代x的第i个特征,来进行扰动,但是保持剩下的特征同
取代x的第i个特征,来进行扰动,但是保持剩下的特征同![]() 一样。当:
一样。当:
![]()
时,近似目标是最大化的。
Greedy Attack由公式6和公式8构成。详见Algorithm 1:

3.2 Gumbel Attack
Algorithm 1对每个样本花费![]() 时间进行分析,若数据集很大,Greedy Attack的时间开销也会很大。对公式(3)和公式(4)的另一种方法是,在对抗性攻击之前,将
时间进行分析,若数据集很大,Greedy Attack的时间开销也会很大。对公式(3)和公式(4)的另一种方法是,在对抗性攻击之前,将![]() 参数化,并直接在相同分布的训练数据集中优化参数族上的目标。这种方法用Algorithm 2描述:
参数化,并直接在相同分布的训练数据集中优化参数族上的目标。这种方法用Algorithm 2描述:

公式3和公式4中包含k个类别的随机变量,直接模型评估需要分别考虑![]() 项和
项和![]() 项。一个简单的近似方法是公式5和公式7,其中其中我们假设隐藏节点G和H的分布用贪婪算法很好地逼近。但是,这对于每个训练样本需要花费
项。一个简单的近似方法是公式5和公式7,其中其中我们假设隐藏节点G和H的分布用贪婪算法很好地逼近。但是,这对于每个训练样本需要花费![]() 次模型评估。有一些近似方法:
次模型评估。有一些近似方法:
-
取X的确定性函数参数化的特征的加权和,类似于soft-attention mechanism

-
REINFORCE-type 算法

我们提出的方法基于“Gumbel trick”![]() ,并与Greedy Attack中提出的目标函数近似相结合。这种方法有较小的方差和更好的效果。
,并与Greedy Attack中提出的目标函数近似相结合。这种方法有较小的方差和更好的效果。
4 Experiments
对三个数据集分别用了WordCNN、CharCNN和LSTM的网络:

我们将Greedy attack和Gumbel attack和以下方法进行比较:
-
Delete-1 Score:用零填充掩盖每个特征,用预测概率的下降作为特征的得分,用未知掩盖top-k特征。

-
DeepWordBag:对于每个特性,计算两个分数的线性组合,第一个分数根据前面的特性评估特性,第二个分数根据后面的特性评估特性。权重由用户选择。
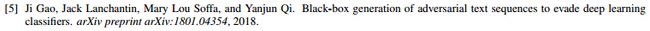
-
Projected FGSM:选择w'替换原单词w,使得
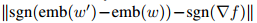 最小,其中emb(w)是w的词嵌入向量,
最小,其中emb(w)是w的词嵌入向量, 是相对于原始词嵌入的预测概率的梯度。
是相对于原始词嵌入的预测概率的梯度。
-
Saliency:根据梯度选择top k个特征,求特征嵌入向量的梯度的l1范数,并将其置为unknown


-
Saliency-FGSM:根据Saliency map选择k个特征,将其用projected FGSM替换
4.1 Word-based models
对IMDB数据集用word-based CNN,对Yahoo! Answers数据集用word-based LSTM。对每种方法,替换词词典![]() 均为频数最高的500个单词。
均为频数最高的500个单词。
TODO
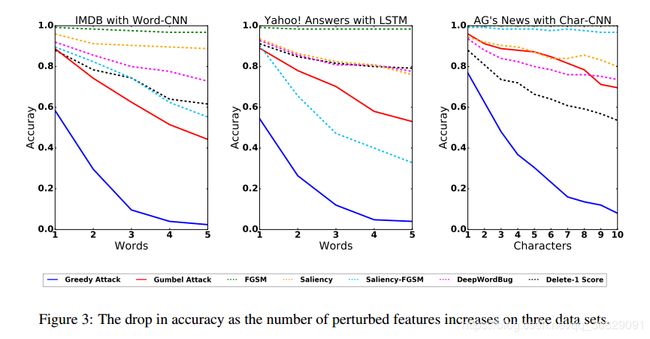
测试样本的准确率由Figure 3给出。可以看到Greedy Attack是效果最好的。
成功的攻击案例由Table 3和Table 4给出:


4.2 Character-based models
对每种方法,替换词![]() 的词典选择了整个字母表(alphabet).Gumbel Attack的架构同Figure 2.
的词典选择了整个字母表(alphabet).Gumbel Attack的架构同Figure 2.
TODO
Table 5展示了成功的攻击案例

4.3 Efficiency,transferabiliey and human evaluation
-
Efficiency:我们测试了各种方法的用时,实验基于NVidia Tesla k80 GPU,编码在TensorFlow上。Figure 4显示了各种方法的平均用时:

Gumbel 方法是所有方法中最有效的。随着被攻击数据规模的增大,Gumbel攻击训练占总时间的比例越来越小
-
Transferability:为了显示攻击方法的可迁移性,我们在IMDB上训练了两个新模型,分别是CNN2(比先前的CNN多了一些全连接层dense layer)和LSTM(与Yahoo!的一样);在Yahoo!上训练了两个新模型,分别是LSTM2(单向,256个memory unit,使用GloVe)和CNN(与IMDB的一样)。实验结果如Figure 5:

Greedy Attack在Yahoo!数据集中迁移性较好,但在IMDB中表现不佳。Gumbel Attack在两个数据集中都保持着很高的成功率。
-
Human evaluation:Amazon Mechanical Turk上的三名员工被要求对每一篇文章进行分类。我们报告的准确性是大多数选票与事实的一致性。如果不存在多数投票,我们将结果解释为不一致。对于每个数据集,使用两种方法成功攻击的200个样本。结果Figure 5所示。