最详细的YOLOv3论文笔记
个人博客:http://www.chenjianqu.com/
原文链接:http://www.chenjianqu.com/show-117.html
论文:YOLOv3: An Incremental Improvement.Joseph Redmon,Ali Farhadi.from 华盛顿大学
摘要
本文对YOLO做了一些小改进,还提出了新的backbone:Darknet-53。比YOLOv2体量更大但是更加精确,而且仍然足够快。使用320x320分辨率,YOLOv3每帧处理时间为22ms,达到28.2mAP,这跟SSD一样精确但是速度是它的3倍。使用旧的0.5 IoU mAP检测指标时,YOLOv3非常好。在Titan X上可以51ms达到57.9 AP50,与之相比,RetinaNet以198ms达到57.5 AP50,比YOLOv3慢3.8倍以上。
代码开源:https://pjreddie.com/yolo/
The Deal
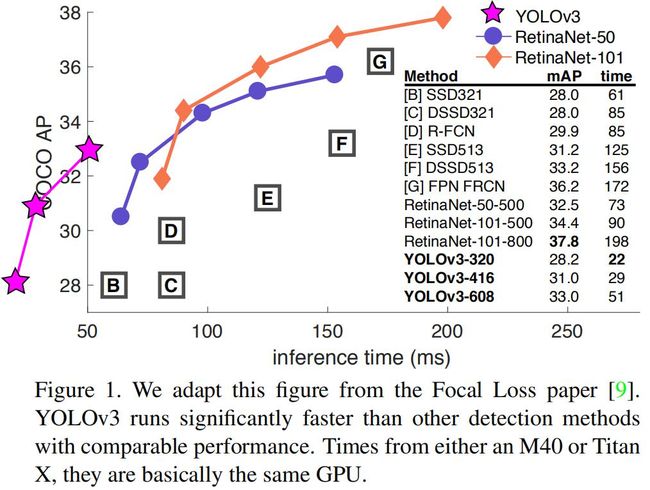
YOLOv3与其它模型的比较:
Bounding Box Prediction
与YOLO9000一样,YOLOv3使用dimension cluster设置先验框(anchor boxes)。网络对每个先验框预测4个坐标偏置值:tx,ty,tw,th。如果该先验框的左上角坐标为(cx,cy),该先验框的宽高是pw,ph,则预测的包围框的左上角坐标和长宽为:
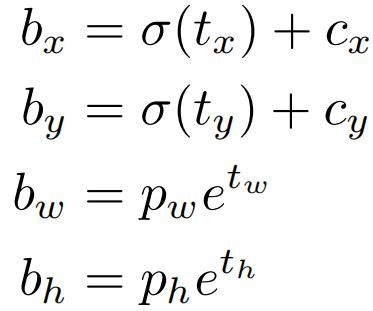
图示如下:
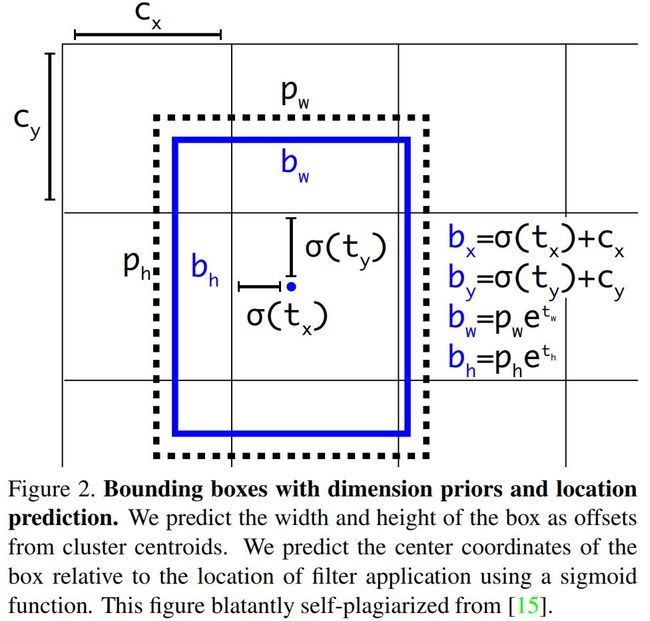
训练时,使用误差平方和损失。若预测的坐标是t*,gt(由gt包围框转换而来)是t^*,则梯度为t^*-t*。YOLOv3使用logistic回归预测每个包围框的置信度。如果当前预测的包围框比之前其他的任何包围框更好的与gt对象重合,那它的置信度就是 1。如果当前预测的包围框不是最好的,但它和 gt 对象重合了一定的阈值以上,神经网络会忽略这个预测。这里使用的阈值是 0.5。只为每个gt对象分配一个包围框。如果当前的包围框未分配给相应的gt目标,那它仅仅是检测错了目标,不会对坐标或分类预测造成影响。
分类预测
每个包围框使用多标签分类预测包含的目标类别。这里没有使用softmax,而是简单的使用独立的logistic分类器。训练时使用的损失函数是二元交叉熵损失。
使用这个方法有助于将YOLO应用到更复杂领域,比如Open Image Dataset。在这个数据集中,可能有很多重叠的标签,比如女人和人。Softmax会会强加一个假设,使得每个框只包含一个类别。而多标签方法能更好的建模这种数据。
跨尺度预测
YOLOv3在3个不同尺度预测包围框。与FPN类似,这里从不同的尺度抽取特征并进行预测。每个尺度的特征图的每个位置预测3个包围框,输出张量的维度是N*N*[3*(4+1+80)],即4个包围框坐标值,包围框置信度和80个分类预测。具体的网络结构请看后面给出的结构图。
和YOLOv2一样,使用 k-means 聚类来确定先验框的。这里设置3 个尺度 ,共9 个聚类,分别是:(10×13)、(16×30)、(33×23)、(30×61)、(62×45)、(59×119)、(116×90)、(156×198)、(373×326) 。

特征提取器
这里提出一个新的backbone网络,基于Darknet-19和残差网络,使用连续的3x3和1x1卷积和短路连接实现。该网络有53层,故称为Darknet-53。其网络详细情况如下:
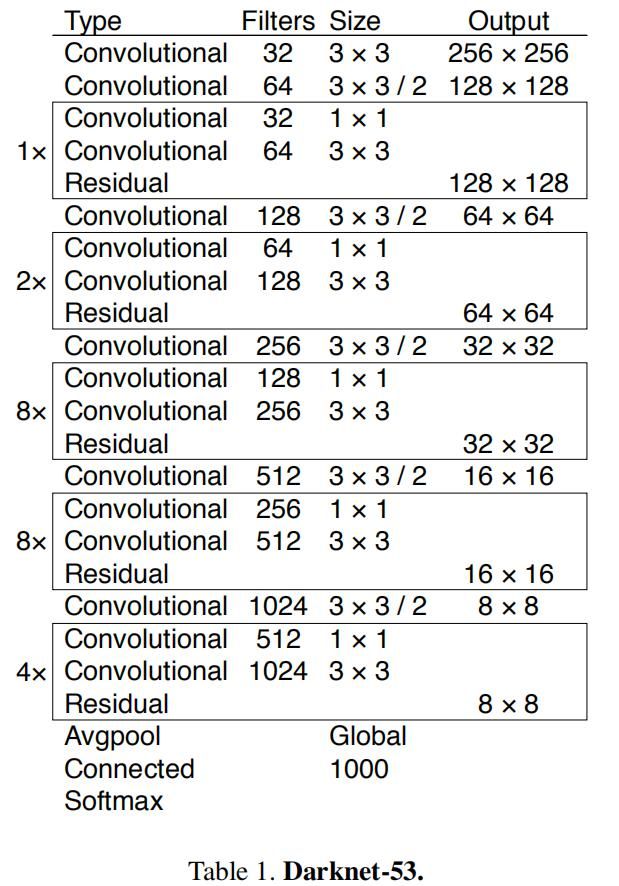
整个backbone里没有池化层和全连接层,前向传播过程中,张量的尺寸变换是通过改变卷积核的步长来实现。 Darknet-53比Darknet-19更精确,比ResNet更加快,下面是各个Backbone网络的比较结果:
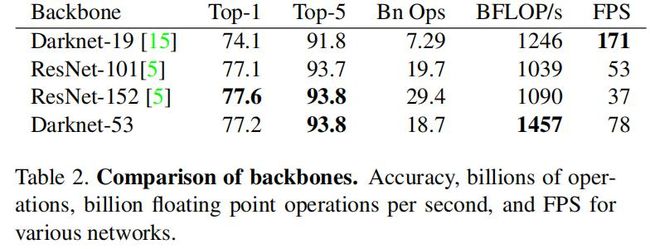
上表中各网络使用相同的配置训练,测试分辨率为256x256,单个模型的精度。测试时间使用256x256在Titan X上运行。从表中可以看到,Darknet-53是最精确的分类模型之一,但是它仅需很少的计算量。Darknet-53在BFLOP/s (floating point operations per second)中的评分最高,这表明它最能充分利用GPU。这主要是因为ResNet有太多的层,效率不高。
YOLOv3的网络结构
[图源]
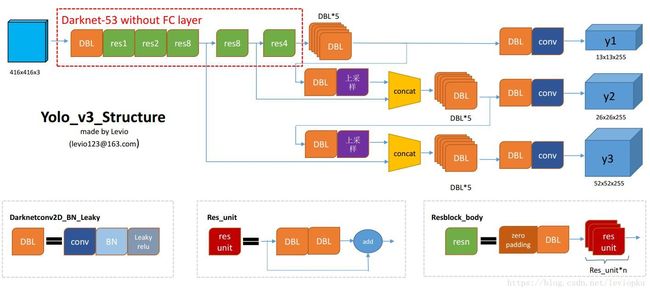
 转存失败重新上传取消
转存失败重新上传取消
最后输出3个张量,这就是前面的提到的跨尺度预测,输出三个尺度的预测结果。每个位置的预测的维度是255,这里像YOLOv2一样,每个位置预测3个包围框,每个包围框预测5个值(tx,ty,tw,th,to),to是该包围框的置信度,而且这里预测80个类别,因此255=3*(5+80)。
How We Do
下表是YOLO与当前SOTA目标检测模型的比较:
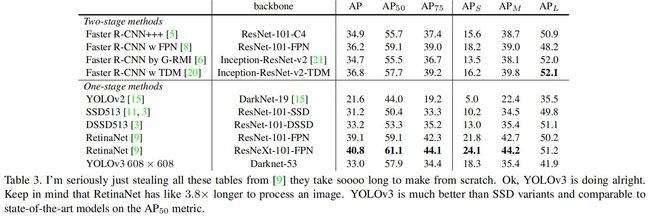
从AP指标,可以看到YOLOv3的精度比得上SSD和DSSD,但是比他们都快3x,但是落后于RetinaNet等最顶级的模型。
但是看AP50可知,YOLOv3几乎达到了SOTA。这表明YOLOv3更擅长检测decent目标,而难以将包围框与目标进行对齐。
从表中还可以看到,YOLOv3检测小目标的能力相对于YOLOv2大幅提升,而且优于SSD和DSSD。
Things We Tried That Didn’t Work
作者曾经尝试过一些stuff,但是没work。
Anchor box x, y offset predictions. 尝试使用先验框+预测偏置的方式,发现它降低了模型的稳定性,并且效果不好。
Linear x, y predictions instead of logistic. 尝试使用线性激活来直接预测x、y偏置,而不使用logistic激活。但这导致下降了几点mAP。
Focal loss. 尝试使用Focal loss,但它使得mAP下降了2个百分点。YOLOv3可能已经对focal loss试图解决的问题很健壮了,因为它有单独的对象预测和条件类预测。
Dual IOU thresholds and truth assignment.Faster R-CNN在训练时使用两个IoU阈值,若预测的包围框与gt的IoU大于0.7,则作为正例;若IoU在[0.3-0.7]则忽视这个IoU;若IoU<0.3则作为负例。这里尝试了这个策略,但没有什么效果。
What This All Means
YOLOv3使用AP50时,接近SOTA:
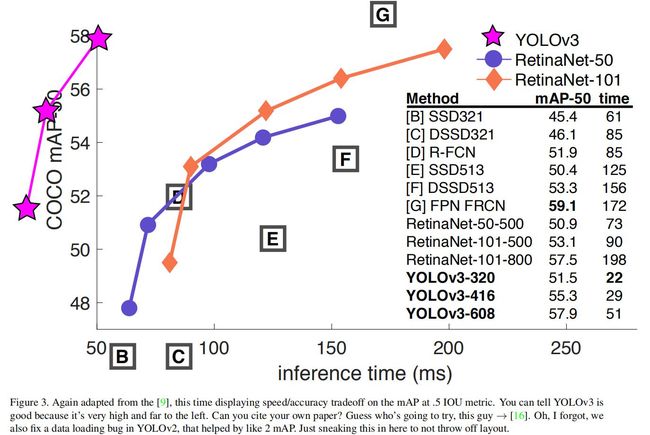
接着作者表达了对计算机视觉的应用的担心(比如获取个人信息,帮助军方等),所以他2020年退出CV界了。个人不太喜欢Joseph Redmon,太白左了。