基于哈夫曼编码用java实现文件的压缩与解码
**
基于哈夫曼编码用java实现文件的压缩与解码
**
该程序是基于哈夫曼算法实现文件的无损压缩和解压,有压缩和解压两个功能。
一,压缩的实现
首先我们来了解一下什么是哈夫曼算法以及哈夫曼编码。
哈夫曼树是一种树形的数据结构,又叫最优二叉树,用哈夫曼树的方法的得到的编码就是哈夫曼编码。此树的特点是引出的路径最短。路径:从树的根节点到一个节点之间的分支构成协和两个节点之间的路径。路径长度:路径上分支的树目。
如何实现压缩?现在比如在一个文件中存储有abaabc;那么计算机中存储的应该是01100001(a) 01100010 (b)01100001(a)01100001(a)01100010 (b)01100011 (c),一共占6个字节;
我们用文件中某个字出现的次数作为权值来构造哈夫曼树,上面的字符串中a出现了三次,那么把3作为a的权值,b出现了两次,那么把2作为b的权值,同理把1作为c的权值,那么我们得到的哈夫曼树如下图:
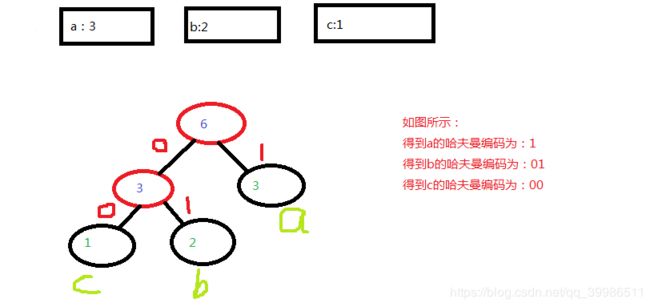
abaabc 变成了 11 01 110100 那么原来的6个字节现在变成了2个字节,我们现在只需要把这个新的01字符串转换成十进制数,就可以实现了文件的压缩
具体实现的思路:
①首先是哈夫曼树的实现
新建了一个哈夫曼树的节点类,Node.。我们需要在这个节点存储两个值,一个是某个字符的的byte,另一个是该byte的权重(也就是在文件中出现的次数)。我们将要通过比较节点的权重值来给节点排序得到哈夫曼树。排序好以后,取出权重值最小的两个节点构造一个子树,并把他们的权重值相加作为他们的父节点的权重值,之后把该父节点和剩下的节点排序,再去除权重值最下的两个节点构造子树,如此循环下去,最终得到该哈夫曼树得根节点。自此哈夫曼树也就构建成功。
②遍历哈夫曼树得到哈夫曼编码。
从哈夫曼树的根节点开始遍历,如果某个节点有一个左节点,编码加‘0’,如果有一个右节点,那么编码加‘1’,当然你也可以左边是1右边还是0。最后你遍历到左节点和右节点都为空的时候,也就是叶子节点的时候就可以得到该叶子节点的byte的编码。如上图得到a的哈夫曼编码是1,b是01,c是00。
现在我们已经可以构造哈夫曼树并能得到哈夫曼编码了后我们就可以开始压缩文件了。
③压缩文件
压缩文件的时候我们首先要判断我们要压缩的是一个文件夹还是一个文件。如果是文件,可以直接压缩,但是文件夹则需要遍历这个文件夹找到文件后压缩。在压缩文件时,我们首先需读一次文件来统计字符出现的次数,并把该字符的int值和出现次数作为一个Node节点。得到节点后构造哈夫曼树得到哈夫曼编码。这里为了后面的写入文件的效率,构造一hashMap
好了现在的到了真正的哈夫曼编码后,就可以压缩文件了。现在只需要从文件中读取一个byte得到对应得哈夫曼编码,取哈夫曼编码得前8位转换成为相应得byte写入另一个文件中,依次读读完整个文件就实现文件得压缩了。
但是我们还要实现解压。那我们就需要存入文件得一些信息。作为我个人来讲我依次存入如图:
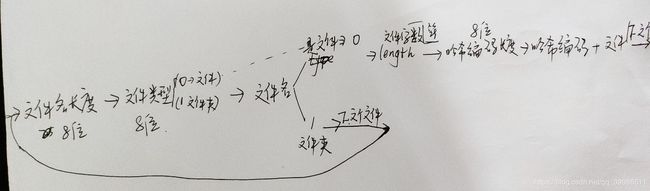
到时候解压依次读取写入的内容就可以实现文件得解压。
二.解压功能。
因为我们在压缩过程中写入了很多东西,解压的话只需要读我们的压缩文件就可以实现解压功能了。首先读出文件名长度(不管是文件还文件夹)再读出文件类型,如果读出来的是1那么是文件夹,如果是0那么是文件。再读出和文件名长度相等的字符作为文件名,如果是文件那么就要新建一个文件,之后重复上面流程。如果是文件的话,则是把读出的文件名作为我们的输出流路径。下一部分是读出文件内容的长度32位length。之后是读出hashMap。后面就是依照hashMap来读出和length相等的字符。关闭输出流。再循环上述过程。
三, 性能测试结果分析
经过测试我发现该压缩程序的压缩效率并不是很高,特别是在文件较小的时候,说不定压缩得到的文件比原文件还要大。经过分析发现时因为我们在压缩文件的时候还把文件名长度哈希表等写入了文件。着导致了压缩得到的文件比源文件要大。另外该程序对图片的压缩效率不高。我压缩一个1252kb的图片得到的压缩文件也是1253kb
但是该程序对大文件和txt等纯文本文件有较好的压缩效率。如对一个613m的csv文件压缩效率达到37%,但是还远不及压缩软件的效率,要是一个txt文件压缩效率还更高。在压缩时间上,也是文件越小单位时间压缩的字节越小。我压缩这个423mb的文件雅俗时间为16589ms。
四, 遇到的问题与解决方法
首先时压缩时间的问题,开始压缩时间很漫长,发现问题是每从文件中读取一个byte就要遍历一次哈夫曼树,这大大加大了时间,后来改成了hashMap,这样读取一个byte可以很快的得到它对应的哈夫曼编码,大大的提高了效率。
另外的一个问题是fileinputstream和bufferedinputstream之间的选择。开始是前者,但压缩时间和解压的时间都很不可理喻。压缩一个5,6兆的文件需要一分钟以上,但是自从改了bufferedinputstram和bufferedoutstream后,速度有着质的提升。我充分的认识到了bufferedinputstraeam的力量。
另外解压的速度很慢,要是哪位仁兄有好的想法,还请不吝赐教。
这是我第一次写博客,有错误的地方还请指正。最后附上源码以供参考。
1,Node类,实现哈夫曼的节点,用来存储字符编码和出现的次数。
public class Node {
public Node rightNode;
public Node leftNode;
public int weight;
public int character;
public Node(int weight){
this.weight = weight;
}
public Node(int weight,int character){
this.weight=weight;
this.character =character;
}
public Node (int weight,Node leftNode,Node rightNode){
this.weight= weight;
this.leftNode= leftNode;
this.rightNode= rightNode;
}
public void setRightNode(Node rightNode){
this.rightNode = rightNode;
}
public void setLeftNode(Node leftNode){
this.leftNode= leftNode;
}
public void setWeight(int weight){
this.weight =weight;
}
public void setCharacter(char character){
this.character= character;
}
public Node getRightNode(){
return this.rightNode;
}
public Node getLeftNode(){
return this.leftNode;
}
public int getCharacter(){
return this.character;
}
public int getWeight(){
return this.weight ;
}
public int compareTo(Node N){
if(this.weight>N.weight)return 1;
else if(this.weight2,构造哈夫曼树,生成哈夫曼编码:
import java.util.*;
public class huffmanTree {
public Node root;
public huffmanTree(List nodes){
nodes =new ArrayList<>(nodes);
sortList(nodes);
while (nodes.size()>1){
creatAndReplace(nodes);
}
if(nodes.size()==0)
root=null;
else
root = nodes.get(0);
}
private static void creatAndReplace(List nodes) {
Node left = nodes.get(0);
Node right = nodes.get(1);
Node parent = new Node(left.weight + right.weight,-1);
parent.setLeftNode(left);
parent.setRightNode(right);
nodes.remove(0);
nodes.remove(0);
nodes.add(parent);
sortList(nodes);
}
public static Comparator comparator = (o1, o2) -> {
if(o1.weight>o2.weight) {
return 1;
}else
if(o1.weight==o2.weight){
return 0;
}else {
return -1;
}
};
private static void sortList(List nodes) {
Collections.sort(nodes, comparator );
}
public void print(Node root, String string,HashMap map){
if(root!=null) {
if (root.getRightNode() == null & root.getLeftNode() == null) {
// System.out.println(root.character + " 对应的编码 " + string);
map.put(root.character, string);
}
if (root.getLeftNode() != null) {
print(root.getLeftNode(), string + "0", map);
}
if (root.getRightNode() != null) {
print(root.getRightNode(), string + "1", map);
}
}
}
}
3,实现压缩:
import javafx.scene.Scene;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
public class compress {
static int count = 7;
static int buffer = 0;
static int length=0;
ArrayList nodes = new ArrayList<>();
private File compressFile;
public compress(String path) throws IOException {
String out;
compressFile = new File(path);
//此处因该只能有一个流
if(compressFile.isDirectory()){
out=path+".zip";
}else {
String prefix = path.substring(0, path.lastIndexOf("."));//
out= prefix+".zip";
}
BufferedOutputStream outputStream= new BufferedOutputStream(new FileOutputStream(out));
compressFile(compressFile,outputStream);
outputStream.close();
}
public void compressFile(File ptah,BufferedOutputStream bufferedOutputStream) throws IOException {
if(ptah.isDirectory()){
String directoryName = ptah.getPath();
bufferedOutputStream.write(directoryName.length());
int type=1;
bufferedOutputStream.write(type);
for(int a=0;a map= new HashMap<>();
huffmanTree huffmanTree =new huffmanTree(nodes);
huffmanTree.print(huffmanTree.root,"", map);//create the hashMap
writeFile(file,bufferedOutputStream,map);//compress the file
nodes.clear();
map.clear();
}
public static void writeFile(File path, BufferedOutputStream bufferedOutputStream, HashMap map) throws IOException {
BufferedInputStream fis = new BufferedInputStream(new FileInputStream(path));
BufferedOutputStream out = bufferedOutputStream;
String theCodeOfLength="";
for(int i=0x80000000;i!=0;i>>>=1){
theCodeOfLength+=(length&i)==0?'0':'1';
}//转换成32位二进制
for (int j = 0; j<32 ; j++){
char ch = theCodeOfLength.charAt(j);
writeBit(ch-'0',out);
}
//System.out.println(length+" 32位编码 "+ yy);
length=0;
//write the length of byte into the compressed file
for(int i =0;i<=255;i++){
if(map.containsKey(i)){
String character= map.get(i);
int a = character.length();
out.write((byte)a);
}else {
out.write((byte)0);
}
}
//写入哈夫曼编码长度
for(int i= 0;i<=255;i++){
if(map.containsKey(i)){
String character = map.get(i);
for (int j = 0; j< character.length(); j++) {
char ch = character.charAt(j);
writeBit(ch-'0',out);
}
}
}//写入哈夫曼编码
//System.out.println(buffer+" the last code "+count);
int value= fis.read();
while(value!=-1){
String str= map.get(value);
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i);
writeBit(ch-'0',out);
}
value = fis.read();
}
System.out.println(buffer);
if(buffer!=0)
out.write(buffer);//写入文件的末尾
buffer=0;
count=7;
fis.close();
}
private static void writeBit(int ch,BufferedOutputStream outputStream) throws IOException {
int a= ch< 4,实现解压文件:
import jdk.dynalink.beans.StaticClass;
import java.io.*;
import java.util.ArrayList;
import java.util.HashMap;
public class decode {//it should be decompress ,but i used decode .
static HashMap hashMap= new HashMap<>();//the hashMap is used store the characters and its huffmanCode
static int readCount=7;
static ArrayList code= new ArrayList<>();
public decode(String path) throws IOException {
BufferedInputStream inputStream= new BufferedInputStream(new FileInputStream(path));
File file= new File(path);
decodeFile(inputStream);
inputStream.close();
}
private void decodeFile(BufferedInputStream inputStream) throws IOException {
int lengthOfFileName = inputStream.read();
int fileType= inputStream.read();
String name="" ;
while(name.length()> readCount;
readCount--;
if(readCount==-1)
readCount=7;
y= y&1;
code.add(y);
}
}
// public static void main(String[] args) throws IOException {
// long start = System.currentTimeMillis();
// decode decode= new decode("file/qq.zip");
// long end = System.currentTimeMillis();
// System.out.println("execute time:"+(end - start)+"ms");
//
// }
}
本来还有一个gui界面的,但是自己的界面做的丑就不写在这里了。
希望对你有所帮助,点个赞吧!