java爬虫demo
java爬虫demo
- 网络爬虫的基本概念
- 网络爬虫的分类
- 网页内容获取工具 jsoup
- jsoup 解析 URL 加载的 Document
- jsoup 使用中的遍历
- jsoup 选择器的使用
- 网页内容获取工具 HttpClient
- HttpClient 相关 Jar 的下载
- HttpClient 的使用
- 举一个栗子
- 代码:
网络爬虫的基本概念
网络爬虫(Web Crawler),又称为网络蜘蛛(Web Spider)或 Web 信息采集器,是一种按照一定规则,自动抓取或下载网络信息的计算机程序或自动化脚本,是目前搜索引擎的重要组成部分。
狭义上理解:利用标准的 HTTP 协议,根据网络超链接(如https://www.baidu.com/)和 Web 文档检索的方法(如深度优先)遍历万维网信 息空间的软件程序。
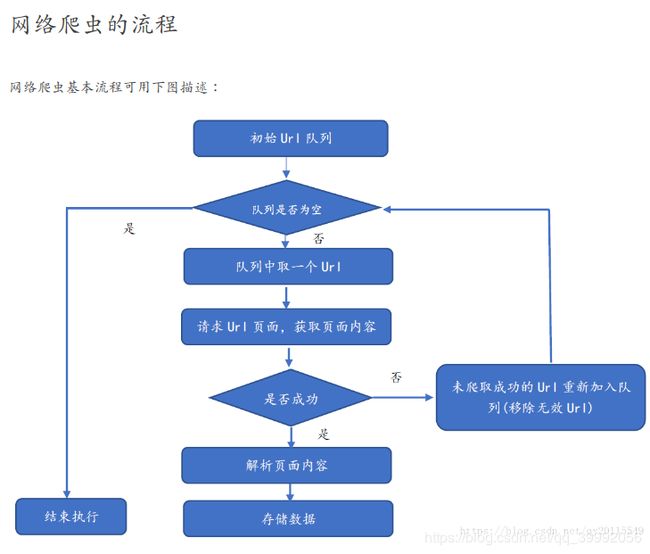
功能上理解:确定待爬的 URL 队列,获取每个 URL 对应的网页内容(如 HTML/JSON),解析网页内容,并存储对应的数据。
网络爬虫的分类
网络爬虫按照系统架构和实现技术,大致可以分为以下几种类型:通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。实际的网络爬虫系统通常是几种爬虫技术相结合实现的。
通用网络爬虫:爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。
通用网络爬虫的爬取范围和数量巨大,对于爬行速度和存储空间要求较高,对于爬行页面的顺序要求较低,通常采用并行工作方式,有较强的应用价值。
聚焦网络爬虫,又称为主题网络爬虫:是指选择性地爬行那些与预先定义好的主题相关的页面。
和通用爬虫相比,聚焦爬虫只需要爬行与主题相关的页面,极大地节省了硬件和网络资源,保存的页面也由于数量少而更新快,可以很好地满足一些特定人群对特定领域信息的需求。
以当当网来举一个例子:当当网
关于网络爬虫的一个流程:
网页内容获取工具 jsoup
jsoup下载
<dependency>
<groupId>org.jsoupgroupId>
<artifactId>jsoupartifactId>
<version>1.10.3version>
dependency>
jsoup 提供的 connect(String url) 方法创建一个新的 Connection,并通过 get() 获取网页对应的 HTML 文件,具体如下:
Document doc = Jsoup.connect("http://www.w3school.com.cn/b.asp").get();
System.out.println(doc);
jsoup 也可以使用 Post() 方法请求网页内容,使用如下:
//可以看到该网址通过两种方法都能请求到内容
Document doc = Jsoup.connect("http://www.w3school.com.cn/b.asp").post();
System.out.println(doc);
jsoup 解析 URL 加载的 Document
//获取URL对应的HTML内容
Document doc = Jsoup.connect("http://www.w3school.com.cn/b.asp").timeout(5000).get();
//select选择器解析内容
Element element = doc.select("div#w3school").get(0); //获取Element,这里相当于div[id=w3school]
String text1 = element.select("h1").text(); //从Element提取内容(抽取一个Node对应的信息)
String text2 = element.select("p").text(); //从Element提取内容(抽取一个Node对应的信息)
System.out.println("输出解析的元素内容为:");
System.out.println(element);
System.out.println("抽取的文本信息为:");
System.out.println(text1 + "\t" + text2);
jsoup 使用中的遍历
<div id="course">
<ul>
<li>
<a href="/js/index.asp" title="JavaScript 教程">JavaScripta>li>
<li>
<a href="/htmldom/index.asp" title="HTML DOM 教程">HTML DOMa>li>
<li>
<a href="/jquery/index.asp" title="jQuery 教程">jQuerya>li>
<li>
<a href="/ajax/index.asp" title="AJAX 教程">AJAXa>li>
<li>
<a href="/json/index.asp" title="JSON 教程">JSONa>li>
<li>
<a href="/dhtml/index.asp" title="DHTML 教程">DHTMLa>li>
<li>
<a href="/e4x/index.asp" title="E4X 教程">E4Xa>li>
<li>
<a href="/wmlscript/index.asp" title="WMLScript 教程">WMLScripta>li>
ul>
div>
//获取URL对应的HTML内容
Document doc = Jsoup.connect("http://www.w3school.com.cn/b.asp").timeout(5000).get();
//层层定位到要解析的内容,可以发现包含多个li标签
Elements elements = doc.select("div[id=course]").select("li");
//遍历每一个li节点
for (Element ele : elements) {
String title = ele.select("a").text(); //.text()为解析标签中的文本内容
String course_url = ele.select("a").attr("href"); //.attr(String)表示获取标签内某一属性的内容
System.out.println("课程的标题为:" + title + "\t对应的URL为" + course_url);
}
jsoup 选择器的使用
基本语法
Element.select(String selector);
Elements.select(String selector);
//获取URL对应的HTML内容
Document doc = Jsoup.connect("http://www.w3school.com.cn/b.asp").timeout(5000).get();
//[attr=value]: 利用属性值来查找元素,例如[id=course]; 通过tagname: 通过标签查找元素,比如:a
System.out.println(doc.select("[id=course]").select("a").get(0).text());
//fb[[attr=value]:利用标签属性联合查找
System.out.println(doc.select("div[id=course]").select("a").get(0).text());
//#id: 通过ID查找元素,例如,#course
System.out.println(doc.select("#course").select("a").get(0).text());
//通过属性属性查找元素,比如:[href]
System.out.println(doc.select("#course").select("[href]").get(0).text());
//.class通过class名称查找元素
System.out.println(doc.select(".browserscripting").text());
//[attr^=value], [attr$=value], [attr*=value]利用匹配属性值开头、结尾或包含属性值来查找元素(很常用的方法)
System.out.println(doc.select("#course").select("[href$=index.asp]").text());
//[attr~=regex]: 利用属性值匹配正则表达式来查找元素,*指匹配所有元素
System.out.println(doc.select("#course").select("[href~=/*]").text());
网页内容获取工具 HttpClient
HttpClient 相关 Jar 的下载
<dependency>
<groupId>org.apache.httpcomponentsgroupId>
<artifactId>httpcoreartifactId>
<version>4.4.9version>
dependency>
HttpClient 的使用
get() 方法的使用
HttpClient client = new DefaultHttpClient(); //初始化httpclient
String personalUrl = "http://www.w3school.com.cn/b.asp"; //请求的地址URL
HttpGet getMethod = new HttpGet(personalUrl); // get方法请求
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1,
HttpStatus.SC_OK, "OK"); //初始化HTTP响应
response = client.execute(getMethod); //执行响应
String status = response.getStatusLine().toString(); //响应状态
int StatusCode = response.getStatusLine().getStatusCode(); //获取响应状态码
ProtocolVersion protocolVersion = response.getProtocolVersion(); //协议的版本号
String phrase = response.getStatusLine().getReasonPhrase(); //是否ok
if(StatusCode == 200){ //状态码200表示响应成功
//获取实体内容,这里为HTML内容
String entity = EntityUtils.toString (response.getEntity(),"gbk");
//输出实体内容
System.out.println(entity);
EntityUtils.consume(response.getEntity()); //消耗实体
}else {
//关闭HttpEntity的流实体
EntityUtils.consume(response.getEntity()); //消耗实体
}
post() 方法的使用
List<NameValuePair> nvps= new ArrayList<NameValuePair>();
nvps.add(new BasicNameValuePair("param1", "value1"));
nvps.add(new BasicNameValuePair("param2", "value2"));
UrlEncodedFormEntity entity = new UrlEncodedFormEntity(nvps, Consts.UTF_8);
HttpPost httppost = new HttpPost("http://localhost/handler.do");
httppost.setEntity(entity);
举一个栗子
以爬取当当网的一个书为例:
JdongMain是程序的入口、JdongBook对应京东上出售的书籍、URLHandle是对URL和client的处理,通过它返回经过加工的数据、HTTPUtils发送真正的HTTP请求,并返回响应报文、jdParse是对响应报文的实体内容进行解析。
代码:
需要下载的jar:
<dependencies>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.9</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-logging/commons-logging -->
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
public class JdongBook {
private String bookId;
private String bookName;
private String bookPrice;
public JdongBook() {
}
public String getBookId() {
return bookId;
}
public void setBookId(String bookId) {
this.bookId = bookId;
}
public String getBookName() {
return bookName;
}
public void setBookName(String bookName) {
this.bookName = bookName;
}
public String getBookPrice() {
return bookPrice;
}
public void setBookPrice(String bookPrice) {
this.bookPrice = bookPrice;
}
@Override
public String toString() {
return "Book [bookId=" + bookId + ", bookName=" + bookName + ", bookPrice=" + bookPrice + "]";
}
}
import org.apache.http.HttpResponse;
import org.apache.http.ParseException;
import org.apache.http.client.HttpClient;
import org.apache.http.util.EntityUtils;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class URLHandle {
/**
* @param client 客户端
* @param url 请求地址
* @return 请求数据 :List
* @throws ParseException
* @throws IOException
*/
public static List<JdongBook> urlParser(HttpClient client, String url) throws ParseException, IOException {
System.out.println(client+" client "+url+" url ");
List<JdongBook> data = new ArrayList<JdongBook>();
//获取响应资源
HttpResponse response = HTTPUtils.getHtml(client, url);
//获取响应的状态码
int sattusCode = response.getStatusLine().getStatusCode();
System.err.println(sattusCode+" 2000 ");
if(sattusCode == 200) {//200表示成功
//获取响应实体内容,并且将其转换为utf-8形式的字符串编码
String entity = EntityUtils.toString(response.getEntity(), "utf-8");
System.out.println(" 121"+entity);
data = JdParse.getData(entity);
System.out.println("________________________________");
System.out.println(data);
} else {
EntityUtils.consume(response.getEntity());//释放资源实体
}
return data;
}
}
import org.jsoup.Jsoup;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import java.util.ArrayList;
import java.util.List;
public class JdParse {
/**
* 根据实体获取程序所需数据
* @param entity HTTP响应实体内容
* @return
*/
public static List<JdongBook> getData(String entity) {
System.out.println("================================getDatagetDatagetDatagetDatagetDatagetDatagetDatagetData===================================");
List<JdongBook> data =new ArrayList<JdongBook>();
System.out.println("1111"+data);
//采用jsoup解析,关于jsoup的使用,见下文总结
Document doc = Jsoup.parse(entity);
// System.err.println(doc+"1");
//根据页面内容分析出需要的元素
Elements elements = doc.select("#price_notice_box").select(".price_notice_alert").select(".price_remind_notice");
System.err.println(elements+"3");
for(Element element : elements) {
JdongBook book = new JdongBook();
book.setBookId(element.select(".top_title").attr(".top_title"));
book.setBookName(element.select("div[class=remind_info]").select("span").text());
book.setBookPrice(element.select("div[class=now_price]").select("span").text());
System.out.println("=====================================");
System.out.println(book);
data.add(book);
System.out.println("-------------------");
System.err.println(data);
}
return data;
}
}
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.client.HttpClient;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
public class JdongMain {
public static void main(String[] args) {
//生成一个客户端,通过客户端可url向服务器发送请求,并接收响应
HttpClient client = new DefaultHttpClient();
String url="http://product.dangdang.com/26445445.html";
List<JdongBook> bookList =null;
try {
bookList = URLHandle.urlParser(client, url);
System.err.println("bookList: "+bookList);
for(JdongBook book : bookList) {
System.out.println(" # "+book);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.HttpVersion;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.message.BasicHttpResponse;
import java.io.IOException;
public class HTTPUtils {
public static HttpResponse getHtml(HttpClient client, String url) {
System.out.println("HttpResponse"+client+" client "+url+" url ");
//获取响应文件,即HTML,采用get方法获取响应数据
HttpGet getMethod = new HttpGet(url);
// HttpPost getMethod=new HttpPost(url);
System.out.println("getHttpGet "+getMethod);
HttpResponse response =new BasicHttpResponse(HttpVersion.HTTP_1_1, HttpStatus.SC_OK,"OK");
System.err.println(response+" HttpResponse ");
try {
//通过client执行get方法
response = client.execute(getMethod);
System.out.println(response+" respone ");
} catch (IOException e) {
e.printStackTrace();
} finally {
//getMethod.abort();
}
return response;
}
}
结果展示
