深度学习模型评估指标:mAP计方法与voc_eval.py源码解读
mAP计算方法与voc_eval.py源码解读
- 1.mAP基本计算原理
- 2.源码分析
- voc_eval函数
- parse_rec函数
- voc_ap函数
- 3.precision-recall图分析
我们在上一篇文章《YOLOv3计算自己数据集训练模型的mAP》中介绍了使用valid计算出来验证集的检测结果结果,存于results文件,然后voc_eval函数计算mAP的操作方法。但是voc_eval函数的计算原理是什么?作者是如何通过代码实现的呢?本文尝试进行一个分析介绍。
1.mAP基本计算原理
mAP是mean Average Precision的缩写,Average Precision是每个类型的结果中,每个检测结果的precision(精确度或查准率)在recall(召回率或查全率)上的平均,简称AP;mean是针对每个类型检测结果的平均,就是对AP的平均。
voc_eval函数计算的是每个类型的AP,计算的时候,通过计算precision在recall上的积分,然后再除以recall的域,recall的域为(0,1)。在实际计算的时候,0和1这两种状态是不存在的,所以要对其进行补齐,这时候,对应的precision都为0.
所以,求解mAP的核心工作就是计算precision和recall,关于precision和recall我们将在后面的文章单独介绍,这里简单说说precision和recall的含义。precision就是某种类型的一堆目标检测结果的正确率。换句话说,我们这一堆检测结果中有真的,有假的,我们通过precision计算真值在这些检测出来的结果中的比率。recall就是某种类型的一堆目标中正确检测出来的目标的比例,考察这些目标有没有能够真正检测出来多少。
2.源码分析
源码中计算步骤分为五步:
①第一步:获取所有的GT标签信息,存入字典recs中或文件annots.pkl中,便于使用。这里用“或”表示如果第一次从recs中存入annots.pkl中,那么下次使用,就直接从annots.pkl中读取到recs中即可。GT标签信息在数据集中是存储在Annotations文件夹的成百上千的xml文件中的,每次都读取一遍实在没有必要,于是就在第一次读取的时候将name(类型名),bbox(位置尺寸信息)存入annots.pkl二进制文件。
②第二步:从字典recs中提取当前类型的GT标签信息,存入字典class_recs中,key为图片名imagename。注意,这个key并不是唯一的,有时候一张图片可能有多个相同目标,这时候就要通过计算IOU匹配正确的GT。
③第三步:从当前class的result文件中读取结果,并将结果按照confidence从大到小排序,排序后的结果存在BB和image_ids变量中,BB用于存储位置尺寸信息,image_ids就是图像名,用于和存GT的class_recs中的内容进行匹配。
④第四步:对比GT参数和result,计算出IOU,在fp和tp相应位置标记1。这里在计算的原理如下:
首先,对每一条结果根据confidence进行从大到小排序,第一次遇到且IOU高于阈值,就认为是正目标正确检测,即TP += 1;IOU低于阈值FP+=1。
这个过程中肯定存在计算IOU时,一个图像中有两个GT的,就需要选择一个大的,确定是这个目标。
接着,当相同的图片中又出现一次结果的时候,看看这次检测到的是什么目标:
第一种情况,图中正好有另一个GT,又检测到了,这时候jmax是另一个,TP += 1。
第二种情况,图中正好有另一个GT,但是检测的还是之前那个,相当于一个目标命中两次也计算为 FP+=1。
一般情况下,尺度差别较大的目标不会同时被两种尺度模式同时检测出结果,因为尺度相差比较大,基本不可能是统一个目标。但是如果目标介于两个anchor之间,也很容易预测错误,即两个尺度模式都预测到。本人自制数据集为0-9,a-z,A-Z的验证码数据集,由于所有的目标都是一样尺寸,两个尺度模式都能够预测出来,出现第二种情况FP的概率比较高,因此这种验证码尺寸都一样的就不能使用多尺度。
这里还应注意的是降低阈值可以提高mAP,但是降低到一定成都就不行了,因为虚警率也提升了。
⑤第五步:计算ap,rec,prec。这里使用了voc_ap函数进行计算。
这里需要注意的是计算tp和fp的时候使用了numpy.cumsum(a, axis=None, dtype=None, out=None)函数,这个函数计算结果是第i个位置为a[0]到a[i]的累加,用于积分计算。
下面是本人整理的voc_eval中这五步的详细源码及注释:
voc_eval函数
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.25,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: Path to detections
detpath.format(classname) should produce the detection results file.
annopath: Path to annotations
annopath.format(imagename) should be the xml annotations file.
imagesetfile: Text file containing the list of images, one image per line.
classname: Category name (duh)
cachedir: Directory for caching the annotations
[ovthresh]: Overlap threshold (default = 0.5)
[use_07_metric]: Whether to use VOC07's 11 point AP computation
(default False)
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name
# cachedir caches the annotations in a pickle file
#################################################################################################
##### 第一步:获取所有的GT标签信息,存入字典recs中或文件annots.pkl中,便于使用 #####################
#################################################################################################
# 标签信息都是GT的信息
# 提取annotations标签文件缓存路径
# 如果没有缓存文件,就读取信息并创建一个二进制缓存文件annots.pkl
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
cachefile = os.path.join(cachedir, 'annots.pkl')
# 从图像名称文件中读取图像名称,存入imagenames列表中
with open(imagesetfile, 'r') as f:
lines = f.readlines()
imagenames = [x.strip() for x in lines]
# 根据imagenames列表存储或读取标签信息
if not os.path.isfile(cachefile):
# 载入标签文件,recs这个字典中,存储了验证集所有的GT信息
recs = {}
for i, imagename in enumerate(imagenames):
#解析标签xml文件,annopath为/{}.xml文件,加format表示为{}中赋值
#imagename来源于从imagesetfile中提取,循环采集所有的的信息
recs[imagename] = parse_rec(annopath.format(imagename))
#解析标签文件图像进度条
if i % 100 == 0:
print('Reading annotation for {:d}/{:d}'.format(
i + 1, len(imagenames)))
# 将读取标签内容存入缓存文件annots.pkl,这是个数据流二进制文件
print('Saving cached annotations to {:s}'.format(cachefile))
with open(cachefile, 'wb') as f:
pickle.dump(recs, f)#使用了pickle.dump,存入后保存成二进制文件
else:
# 有标签缓存文件,直接读取,recs中存的是GT标签信息
with open(cachefile, 'rb') as f:
recs = pickle.load(f)
#################################################################################################
##### 第二步:从字典recs中提取当前类型的GT标签信息,存入字典class_recs中,key为图片名imagename #####
#################################################################################################
# 针对某个class名称的result文件提取对应的每个图片文件中GT的信息,存入R
# bbox中保存该类型GT所有的box信息,difficult、det、npos等都从R中提取
# 提取完毕针对每个图片生成一个字典,存入class_recs
# 这里相当于根据class对图片中新不同类型目标进行归纳,每个类型计算一个AP
class_recs = {}
npos = 0
# 上篇文章中说了当result文件名前面含有comp4_det_test_时的2种方法,这里还有个更简单的,即将classname后加上[15:]
# 表示读取第15位开始到结束的内容,这是第3种方法
for imagename in imagenames:
#R中为所有图片中,类型匹配上的GT信息
R = [obj for obj in recs[imagename] if obj['name'] == classname[15:]]
#bbox中存储了该文件中该类型的所有box信息
bbox = np.array([x['bbox'] for x in R])
#difficult转化成bool型变量
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
#该图片中,没有匹配到当前类型det=[],匹配到1个,det=[False],匹配到多个det=[False, ...]
#det将是和difficult不同的地方,当不是difficult的时候,det也是false,这是一个区别
det = [False] * len(R)
#利用difficult进行计数,这里所有的值都是difficult,如果有就不计入
npos = npos + sum(~difficult)
#class_recs是一个字典,第一层key为文件名,一个文件名对应的子字典中,存储了key对应的图片文件中所有的该类型的box、difficult、det信息
#这些box、difficult、det信息可以包含多个GT的内容
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
#################################################################################################
##### 第三步:从当前class的result文件中读取结果,并将结果按照confidence从大到小排序 ################
##### 排序后的结果存在BB和image_ids中 ################
#################################################################################################
# 读取当前class的result文件内容,这里要去result文件以class命名
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
# 删除result文件中的'',对于非voc数据集,有的就没有这些内容
splitlines = [x.strip().split(' ') for x in lines]
# 将每个结果条目中第一个数据,就是图像id,这个image_ids是文件名
image_ids = [x[0] for x in splitlines]
# 提取每个结果的置信度,存入confidence
confidence = np.array([float(x[1]) for x in splitlines])
# 提取每个结果的结果,存入BB
BB = np.array([[float(z) for z in x[2:]] for x in splitlines])
# 对confidence从大到小排序,获取id
sorted_ind = np.argsort(-confidence)
# 获得排序值,这个值后来没有再用过
sorted_scores = np.sort(-confidence)
# 按confidence排序对BB进行排序
BB = BB[sorted_ind, :]
# 对相应的图像的id进行排序,其实每个图像对应一个id,即对应一个目标,当一个图中识别两个相同的GT,是可以重复的
# 这样image_ids中,不同位置就会有重复的内容
image_ids = [image_ids[x] for x in sorted_ind]
#################################################################################################
##### 第四步:对比GT参数和result,计算出IOU,在fp和tp相应位置标记1 #################################
#################################################################################################
# go down dets and mark TPs and FPs
nd = len(image_ids)#图像id的长度
tp = np.zeros(nd)#设置TP初始值
fp = np.zeros(nd)#设置FP初始值
#对一个result文件中所有目标进行遍历,每个图片都进行循环,有可能下次还会遇到这个图片,如果
for d in range(nd):
#提取排序好的GT参数值,里面可以有多个目标,当image_ids[d1]和image_ids[d2]相同时,两个R内容相同,且都可能存了多个目标信息
R = class_recs[image_ids[d]]
#将BB中confidence第d大的BB内容提取到bb中,这是result中的信息,只可能包含一个目标
bb = BB[d, :].astype(float)
ovmax = -np.inf
#BBGT就是当前confidence从大到小排序条件下,第d个GT中bbox中的信息
BBGT = R['bbox'].astype(float)
#当BBGT中有信息,就是没有虚警目标,计算IOU
#当一个图片里有多个相同目标,选择其中最大IOU,GT和检测结果不重合的IOU=0
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
#大于0就输出正常值,小于等于0就输出0
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni#计算交并比,就是IOU
ovmax = np.max(overlaps)#选出最大交并比,当有
jmax = np.argmax(overlaps)#求出两个最大交并比的值的序号
#当高于阈值,对应图像fp = 1
#ovmax > ovthresh的情况肯定不存在虚警,ovmax原始值为-inf,则没有目标肯定不可能进入if下面的任务
if ovmax > ovthresh:
#如果不存在difficult,初始状态,difficult和det都是False
#找到jamx后,第一任务是确定一个tp,第二任务就是将R['det'][jmax]翻转,下次再遇到就认为是fp
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.#一个目标被检测两次
else:
fp[d] = 1.
#################################################################################################
##### 第五步:计算ap,rec,prec ###################################################################
#################################################################################################
##difficult用于标记真值个数,prec是precision,rec是recall
# compute precision recall
fp = np.cumsum(fp)#采用cumsum计算结果是一种积分形式的累加序列
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)#maximum这一大串表示防止分母为0
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap
parse_rec函数
parse_rec函数用于标签文件解析。‘pose’、‘truncated’没有用到,不解释。需要注意的是‘difficult’统统由0转化为False,作为标记用于计算recall的时候对GT总数量。查阅http://host.robots.ox.ac.uk/pascal/VOC/voc2012/htmldoc/index.html,解释如下:
difficult': an object marked asdifficult’ indicates that the object is considered difficult to recognize, for example an object which is clearly visible but unidentifiable without substantial use of context. Objects marked as difficult are currently ignored in the evaluation of the challenge.
如果标记为1,则在估计的时候不考虑,这里全为0,表示目标都可以直接识别,所以可以用来计数。
下面是的源码注释:
#标签文件解析,一般使用name、xmin、ymin、xmax、ymax几个标签元素
#每个目标的数据保存成一个字典,再存入列表返回
def parse_rec(filename):
""" Parse a PASCAL VOC xml file """
tree = ET.parse(filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text#name节点存的是class,图像类型名称
obj_struct['pose'] = obj.find('pose').text#默认为Unspecified
obj_struct['truncated'] = int(obj.find('truncated').text)#默认为0
obj_struct['difficult'] = int(obj.find('difficult').text)#默认为0
bbox = obj.find('bndbox')#获取尺寸位置信息
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
voc_ap函数
voc_ap用于计算AP。
其中代码:
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
i = np.where(mrec[1:] != mrec[:-1])[0]
是考虑在计算precision和recall的时候是增加的,不可避免随着检测出来的目标数增加存在fp,会导致recall增量停滞不前,导致precision夹杂fp后得到一个伪值从而下降,所以要对fp对应的值进行剔除。
下面是代码及注释:
def voc_ap(rec, prec, use_07_metric=False):
""" ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
# 将recall和precision补全,主要用于积分计算,保证recall的域为[0,1]
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# 滤除fp增加条件下导致的pre减小的无效值
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
# 滤除总检测样本数增加导致计算的recall的未增加的量
i = np.where(mrec[1:] != mrec[:-1])[0]
# 通过积分计算precision对recall的平均数
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
3.precision-recall图分析
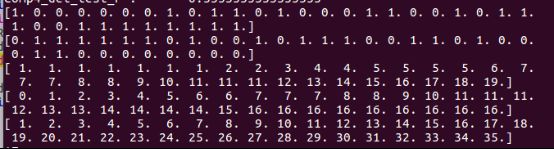
以对字母F识别为例,给一个计算结果。下面两个图为计算结果。先计算fp,后计算tp,顺序有点颠倒,Ubuntu处理截图不方便,大家凑合看:
第1图第1个array存的是cumsum之前的fp,0表示对应的检测目标为真目标,1表示检测目标为伪目标;
第1图第2个array存的是cumsum之前的tp,1表示对应的检测目标为真目标,0表示检测目标为伪目标;
第1图第3个array存的是cumsum之后的fp,肉眼可见为累加计算;
第1图第4个array存的是cumsum之后的tp,也是累加计算;
第1图第5个array存的是tp+fp。
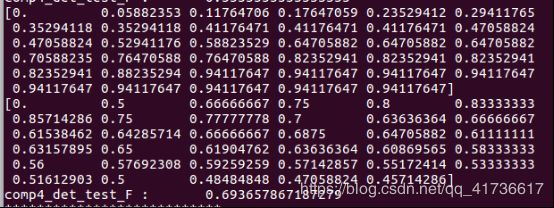
第2图第1个array存的是recall,第2个图存的是precision。
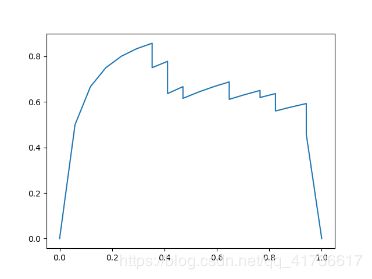
下图是对字母F识别的precision-recall图。横轴为recall,纵轴为precision,里面陡降的位置就是累加时候出现了fp。
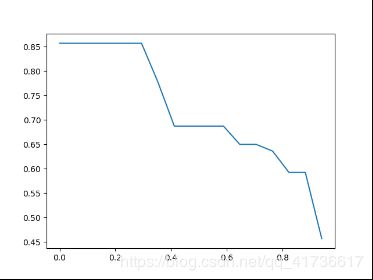
下图是剔除fp之后的precision-recall图,AP就是求的积分。
以上就是计算mAP的voc_eval.py源码解读,有什么问题共同探讨哦!