算法!司南。
《目录》
难题的定义
- NP困难
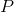
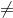
猜想
- NP 完全问题
- 旅行商问题的外卖解法
- 最近邻居法
- 小谈 · 图灵停机问题
基础算法模版
- 迭代加深搜索(可代替BFS)
- DFS(一条路走到黑)
- BFS(一石激起千层浪)
- 随机数据生成器
- 高精度
- 竞赛测试提交模板
- 程序计时/卡点测试
- 自制调试器
- 分治算法
基础算法设计
- 1. 原型设计
- 2. 参数设计
- 3. 边界设计
- 4. 性能设计
- 5. 出错设计
- 6. 算法技巧设计
- 7. 设计思想小百科
- 8. 如何设计算法/解题
基础算法分析
- 0. 数学归纳法
- 1. 对数
- 2. 主定理
- 3. 渐近记号
- 4. 高等分析
- 5. 分治策略
- 6. 组合计数
- 7. 排序算法
- 8. 摊还分析
- 9. 概率论与多项式
- 10. 锻炼分析能力的逻辑谜题
- 11. 趣味算法小集
难题的定义
高考的难题对出卷人不算难题;那些不知道答案觉得难,知道就不难的题也不是难题;现在没人会解的题也不一定是难题,那么难题是什么?
难题在计算机科学中就是 NP问题,如著名的旅行商问题。
旅行商问题大致原意,送餐,外卖小哥带着外卖 从任意一个外卖点(下图的红点)出发 送到所有外卖点 再回到出发的外卖点。
p.s. 生活中外卖小哥只能从餐馆出发,但 NP 问题不是,餐馆和外卖目的地只是外卖点,都是下图的某个红点。

NP困难
为什么说 NP问题 是难题 ?
因为对于 NP问题 并没有好的算法解决。
理论上证明,这个问题它就几乎不可能存在什么好的解法,几乎就是只能把所有外卖点的所有排列组合都计算一遍,看看其中哪个最短,时间复杂度是O(n!)。
说 "几乎" 是因为这里面涉及到一个数学猜想,叫 " ![]() ",也就是说也许还有存在简单算法的一线希望。
",也就是说也许还有存在简单算法的一线希望。
猜想
假设有一个规模为 n 的问题,如果我们能在多项式时间内找到问题的正确的解,称为 P 问题。
是能在多项式时间内解出的问题,P 的阶数 ![]() ,意思是:计算时间在 n 的常数次方内 O(
,意思是:计算时间在 n 的常数次方内 O( 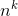 )。
)。
P 问题,四字概括:高 效 正 解。
与 P 问题对应的是 NP 问题,旅行商问题也是其中之一。
NP 问题的解往往是近似解,所以 NP 问题是值当得到一些近似解时,能否高效的找出其中某个近似解是问题的正确的解。
举个例子,刘强西要去洗衣服,他洗 1 件衣服的时间为 2 分钟,洗 5 件衣服的时间为 10 分钟,洗 10 件衣服的时间为 20 分钟,这就是 P 问题。
现在我们假设刘强西洗 1 件这种衣服的时间为 2 分钟,但洗 5 件的时间变为 32 分钟,洗 10 件的时间变为 1024 分钟,这就是 NP 完全问题。
已经证明了所有 P 问题都是 NP 问题,但 NP 问题是不是 P 问题还没有答案。
若 所有 NP 问题都是 P 问题, ![]() 猜想成立; 若 NP 问题中有问题不是 P 问题 ,
猜想成立; 若 NP 问题中有问题不是 P 问题 , ![]() 猜想成立。
猜想成立。
大部分计算机科学家深信后者。
![]() 猜想 :即使能够高效的判定问题的解,也不一定能高效的找出问题的解。
猜想 :即使能够高效的判定问题的解,也不一定能高效的找出问题的解。
NP 完全问题
有一部分 NP 问题被称为 NP 完全问题,一般而言,是 NP 问题中最难的问题。
只要证明任意一个 NP 完全问题是 P 问题,也就能证明 ![]() 。
。
所以,得先找到 NP 完全问题 才能证明,也因此,第一个找到 NP 完全问题 的斯蒂芬·库克 获得了图灵奖。
如果想摆弄一下,可以读一读《数学聊斋》。
旅行商问题的外卖解法
假设您手下,有 3 个外卖小哥,小a,小b,小c,分别根据他们的思维套路做出了不同的决定。
启发式方法,可以理解为 “思维快捷方式”,就是思维的套路。
比如,借刀杀人、过河拆桥、顺手牵羊 这些都是基本的套路,您看电视、小说啊,基本都会用到的。
但不论如何,没有启发式是不行的,您不可能面对什么事情都从头推演。
作为社会栋梁,您得多掌握一些高级的启发式。
使用启发式解决难题,得有个条件:
- 视角
所谓视角,是您怎么看这个东西,相当于建立一个坐标系。
那么启发式,则是有了坐标系之后,您怎么在这个坐标系里 “走”。
启发式的定义:在某个视角里,使用这个规则能够得到一个解 —— 您受此启发,也许可以把这个规则用在别的问题上,得到别的解。
最近邻居法
小a,十分憨厚的、务实。ta 认为没必要追求 "最短路线",找一条差不多的路线就可以了。
用计算机的话来讲,这是 "启发式算法" 的核心思想,对于这个外卖问题有一个 "最近邻居法"。
从任何一个外卖点出发,每次访问的下一个外卖点是距离当前外卖点且未被访问的最近的外卖点。
最近邻居法,计算速度十分短但模拟绝大部分情况得到的平均结果,对比最短路线的期望长了 25%。
小b,很机灵。ta认为为了弄到每月的奖金,肯定得比 小a 快,他们是竞争关系啊~
小b 很是认真的分析了"最近邻居法",发现当大量外卖点是一条直线或近似直线时,最近邻居法 效果十分差劲。

无论选择什么外卖点做出发点,最近邻居法总会在某一个点集上失效。
总是挑选最近的外卖点,实在是比较死板呀。
小b 认为应该把 每次访问的下一个外卖点是距离当前外卖点且未被访问的最近的外卖点 改成 最接近的端点。
端点:当前外卖点与其相连的外卖点不超过 1 的顶点。
每个外卖点(端点)形成自己的射线,最后合并如图示,出发点就选择只有一条射线的端点一般是最边的端点。
小c,是一个拥有完美思想的家伙。
只想着还能更好,但目前还没想出来。
后来,只能退求其次。去改进 "启发式算法" 。
ta提出了一个十分数学化的算法,能保证任何情况下此算法给出的路线最多比真实的最短路线长 50%。
后来,还是觉得不完美继续改进。
于是,长 50% 缩短为 49.999999999999999999999999999999999999999999999999999% ...... (p.s. 小数点后 49 个 9)
采自真实案例,不是瞎掰。走到 小c 程度的分别是 伦敦帝国学院的教授 和 斯坦福大学和麦吉尔大学的一个联合团队。
小谈 · 图灵停机问题
有时,会在不经意间写出死循环的代码。
运行后,大脑也深深的受到影响,哎呀,快死机了。
于是,就有人想可不可以写一个函数判断自己写的程序是否会产生死循环 ?
That's a good idea,为了让更多人加入我们,不得已把其命名为 图灵停机问题。
大致长这样。
这个测试函数叫 Test( ) 吧,有 content 、in 俩个参数 ,Test(content, in)。
content : 要测试的程序代码。
in : 要测试程序的输入。
当 content 运行时输入 in ,Test() 返回 -1 表示出现死循环,返回 0 表示正常,自定义。
写一个完整的程序:
int main(){
if( Test(code, str) ){
为真,死循环
}else{
正常
}
return (0);
}运用反证法。
反证法:假设要证明的命题不成立,从而推导出矛盾的证明方法。
如果把上面的代码放进新程序的 Test(content, in),这时候上面的代码简称为 M。
这时, 因为新程序的 in = M,Test 的 content = M ,in = M。
因为一段代码,即可以是程序,又可以是输入的字符串。
int main(){
if( Test(M, M) ){
为真,死循环
}else{
正常
}
return (0);
}按照之前的设计,若 Test(M, M) 返回值为真时是死循环,以 M 作为输入,如果是死循环,那么其实我们得不到返回值;反之,也会矛盾。
因此,这是一个 不可计算问题。
不可计算问题 好像 有些事情,不能事先知道结果只能等待其发生,抑或是,有些事情看着发生却不能解释为什么发生......
其实我感觉没写明白,安利《程序员的数学》第 8 章。
总之,反证法特别重要需要掌握,再看看如何证明 ![]() 是无理数。
是无理数。
使用反证法。
① 假设是有理数,因为那时候人们认知的数系都是由有理数组成。
② 存在整数 a, b,使
(a ≠0)
③ 将等式左右俩边同时开方。那时候刚有乘法,就有了平方(自己乘自己),于是就诞生了平方的逆运算 --- 开方。
④ 去分母得 2a² = b²
⑤ 等式左边有 2n+1(奇数个) 质因数 2。
⑥ 等式右边有 2n(偶数个) 质因数 2。
⑦ 根据质因数分解唯一定理,等式左右俩边每个质因数的个数相同,而 2n+1 = 2n 矛盾了。
⑧ 因此,
基础算法模版
-
迭代加深搜索(可代替BFS)
特点:
限定下界的深度优先搜索,允许深度优先搜索搜索 k 层搜索树,若没有发现可行解,再将 k+1 代入后再进行一次以上步骤,直到搜索到可行解。这个 “模仿广度优先搜索” 搜索法比起广搜是牺牲了时间,但节约了空间。
多用于空间不足,时间充裕时,采用 ta 代替 BFS。
void search(int depth) // depth表示深度
{
if ( finished /* 得到了合适的解 */ ){
// 已经得到了合适的解,接下来输出或解的数量加1
return;
}
if (depth == 0) return; // 无解
// 扩展结点,尝试每一种可能
for (int i=0; i-
DFS(一条路走到黑)
特点:不易立即结束,递归实现易栈溢出,多用于回溯类搜索。
图示:
 深度优先搜索:一条路走到黑
深度优先搜索:一条路走到黑
/* 递归版 */
void DFS(int depth, ...) {
if ( finished /* depth==n */ ){ // 判断边界
// 深度超过范围,说明找到了一个解。
// 找到了一个解,对这个解进行处理,如:输出、解的数量加1、更新目前搜索到的最优值等
return; // 返回上一步
}
// 扩展结点,尝试每一种可能,
for (int i=0; i s; // 存储状态
void DFS(int v, ...){
s.push(v); // 初始状态入栈
while (!s.empty()) {
int x = s.top(); s.pop();
// 处理结点
if ( finished /* x达到某种条件 */ ) {
// 获取状态
// 输出、解的数量加1、更新目前搜索到的最优值等 ...
return;
}
// 寻找下一状态。当然,不是所有的搜索都要这样寻找状态。
// 注意,这里寻找状态的顺序要与递归版本的顺序相反,即逆序入栈
for (i = n-1; i>=0; i--) {
s.push(... /* i对应的状态 */);
}
}
cout<<"No Solution."; // 如果运行到这里,说明无解
} -
BFS(一石激起千层浪)
特点:易立即结束,占用空间大,访问图时,需要判重,多用于 最小步数、深度最小。
图示:
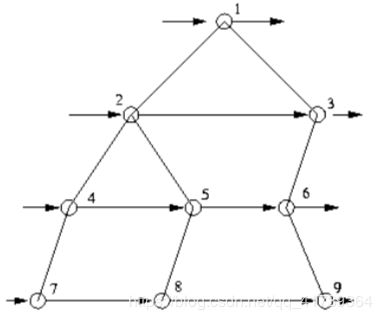 广度优先搜索:水波扩散
广度优先搜索:水波扩散
queue q; // 存储状态
bool try_to_insert(int state); // 结点入队前判断状态是否重复,以免重复搜索
void init_lookup_table(); // 使用散列表可以提高查找的效率
void BFS(){
// init_lookup_table(); // 判重之前的初始化
q.push(…); // 初始状态入队
while ( !q.empty() ){
int s = q.front(); q.pop(); // 获取状态
// 处理结点
if ( finished /* s == 某种条件 */ ){
// 输出,或做些什么...
return;
}
// 扩展状态,尝试每一种可能
for(i=0; i -
随机数据生成器
#include
#include
#include
#include
#include
using namespace std;
char num[3];
/***
第一步: 把 main() 函数以外的代码(结构、类、函数、...的声明和定义)拷贝进来!没有就不用。
***/
void chgnum(int n){
num[0] = num[1] = num[2] = '\0';
if( n<10 )
num[0] = n+'0'; // +48
else
num[0] = n/10+'0', num[1] = n%10+'0';
}
void ans(char *in_file,char *out_file){
freopen(in_file,"r",stdin);
freopen(out_file,"w",stdout);
/***
第二步: 把 main() 中的代码删掉“return 0;”之后拷贝进来!cin/cout改为scanf/printf!
***/
return ;
}
void gen(char *file, unsigned int rand_plus){
freopen(file,"w",stdout);
srand( clock()+rand_plus );
/***
第三步: 数据生成器, 使用scanf/printf!
e.g. A+B Problem 生成器:
int a, b; a = rand()%5000, b = rand()%5000;
printf("%d, %d\n", a, b);
***/
return ;
}
int main(){
int N;
printf("输入制作的数据组数(100以内): ");
scanf("%d",&N);
puts("-----------------------------数据制作开始----------------------------");
srand( (unsigned)time(NULL) );
int P = rand()%100;
char Fname1[512],Fname2[512];
unsigned START = clock();
for(int i=1; i<=N; i++ ){
freopen("CON","w",stdout);
printf("制作第 %d 组数据中...\n",i);
strcpy(Fname1,"***"); // 第四步!把***改为你想要的文件名!
strcpy(Fname2,"***");
chgnum(i);
strcat(Fname1,num);
strcat(Fname2,num);
strcat(Fname1,".in ");
strcat(Fname2,".out ");
gen(Fname1,P);
ans(Fname1,Fname2);
}
freopen("CON","w",stdout);
printf("制作完成!用时 %d 毫秒\n",clock()-START);
return 0;
}
-
高精度
#include
using namespace std;
const int MAX = 100;
struct hp
{
int num[MAX];
hp & operator =(const char *);
hp & operator =(int);
hp();
hp(int);
/* 负数运算不支持 */
bool operator > (const hp &) const;
bool operator < (const hp &) const;
bool operator <= (const hp &) const;
bool operator >= (const hp &) const;
bool operator != (const hp &) const;
bool operator ==(const hp &) const;
hp operator +(const hp &) const;
hp operator -(const hp &) const;
hp operator *(const hp &) const;
hp operator /(const hp &) const;
hp operator %(const hp &) const;
hp & operator +=(const hp &);
hp & operator -=(const hp &);
hp & operator *=(const hp &);
hp & operator /=(const hp &);
hp & operator %=(const hp &);
};
// num[0]用来保存数字位数。另外,利用10000进制可以节省空间和时间。
hp & hp::operator =(const char *c)
{
memset(num, 0, sizeof(num));
int n = strlen(c), j = 1, k = 1;
for (int i = 1; i <= n; i++)
{
if (k == 10000) // 10000进制,4个数字才算1位。
j++, k = 1;
num[j] += k * (c[n - i] - '0');
k *= 10;
}
num[0] = j;
return *this;
}
hp & hp::operator =(int a)
{
char s[MAX];
sprintf(s, "%d", a);
return *this = s;
}
hp::hp()
{
memset(num, 0, sizeof(num));
num[0] = 1;
}
hp::hp(int n)
{
*this = n;
}
// 如果位数不等,大小是可以明显看出来的。如果位数相等,就需要逐位比较。
bool hp::operator >(const hp & b) const
{
if (num[0] != b.num[0])
return num[0] > b.num[0];
for (int i = num[0]; i >= 1; i--)
if (num[i] != b.num[i])
return (num[i] > b.num[i]);
return false;
}
bool hp::operator <(const hp & b) const
{
return b > *this;
}
bool hp::operator <=(const hp & b) const
{
return !(*this > b);
}
bool hp::operator >=(const hp & b) const
{
return !(b > *this);
}
bool hp::operator !=(const hp & b) const
{
return (b > *this) || (*this > b);
}
bool hp::operator ==(const hp & b) const
{
return !(b > *this) && !(*this > b);
}
// 注意:最高位的位置和位数要匹配。
hp hp::operator +(const hp & b) const
{
hp c;
c.num[0] = max(num[0], b.num[0]);
for (int i = 1; i <= c.num[0]; i++)
{
c.num[i] += num[i] + b.num[i];
if (c.num[i] >= 10000) // 进位
{
c.num[i] -= 10000;
c.num[i + 1]++;
}
}
if (c.num[c.num[0] + 1] > 0)
c.num[0]++; // 9999+1,计算完成后多了一位
return c;
}
// 只支持大数减小数~
hp hp::operator -(const hp & b) const
{
hp c;
c.num[0] = num[0];
for (int i = 1; i <= c.num[0]; i++)
{
c.num[i] += num[i] - b.num[i];
if (c.num[i] < 0) // 退位
{
c.num[i] += 10000;
c.num[i + 1]--;
}
}
while (c.num[c.num[0]] == 0 && c.num[0] > 1)
c.num[0]--; // 100000000-99999999
return c;
}
hp & hp::operator +=(const hp & b)
{
return *this = *this + b;
}
hp & hp::operator -=(const hp & b)
{
return *this = *this - b;
}
hp hp::operator *(const hp & b) const
{
hp c;
c.num[0] = num[0] + b.num[0] + 1;
for (int i = 1; i <= num[0]; i++)
{
for (int j = 1; j <= b.num[0]; j++)
{
c.num[i + j - 1] += num[i] * b.num[j]; // 和小学竖式的算法一模一样
c.num[i + j] += c.num[i + j - 1] / 10000; // 进位
c.num[i + j - 1] %= 10000;
}
}
while (c.num[c.num[0]] == 0 && c.num[0] > 1)
c.num[0]--; // 99999999*0
return c;
}
hp & hp::operator *=(const hp & b)
{
return *this = *this * b;
}
hp hp::operator /(const hp & b) const
{
hp c, d;
c.num[0] = num[0] + b.num[0] + 1;
d.num[0] = 0;
for (int i = num[0]; i >= 1; i--)
{
// 以下三行的含义是:d=d*10000+num[i];
memmove(d.num + 2, d.num + 1, sizeof(d.num) - sizeof(int) * 2);
d.num[0]++;
d.num[1] = num[i];
// 以下循环的含义是:c.num[i]=d/b; d%=b;
while (d >= b)
{
d -= b;
c.num[i]++;
}
}
while (c.num[c.num[0]] == 0 && c.num[0] > 1)
c.num[0]--; // 99999999/99999999
return c;
}
hp hp::operator %(const hp & b) const
{
hp c, d;
c.num[0] = num[0] + b.num[0] + 1;
d.num[0] = 0;
for (int i = num[0]; i >= 1; i--)
{
// 以下三行的含义是:d=d*10000+num[i];
memmove(d.num + 2, d.num + 1, sizeof(d.num) - sizeof(int) * 2);
d.num[0]++;
d.num[1] = num[i];
// 以下循环的含义是:c.num[i]=d/b; d%=b;
while (d >= b)
{
d -= b;
c.num[i]++;
}
}
while (c.num[c.num[0]] == 0 && c.num[0] > 1)
c.num[0]--; // 99999999/99999999
return d;
}
hp & hp::operator /=(const hp & b)
{
return *this = *this / b;
}
hp & hp::operator %=(const hp & b)
{
return *this = *this % b;
}
/* ------------------------------------------------------------------------------------------------- */
// 重载输入输出
ostream & operator <<(ostream & o, hp & n)
{
o << n.num[n.num[0]];
for (int i = n.num[0] - 1; i >= 1; i--)
{
o.width(4);
o.fill('0');
o << n.num[i];
}
return o;
}
istream & operator >>(istream & in, hp & n)
{
char s[MAX];
in >> s;
n = s;
return in;
}
// 快速幂
long long quickpow(long long a, long long b)
{
long long d = 1, t = a;
while (b > 0)
{
if (t == 1)
return d;
if (b % 2)
d = d * t;
b /= 2;
t *= t;
}
return d;
} 高精度测试>>
int main( ){
hp a , b; a = 100, b = 0;
cin >> a >> b;
hp result = a + b;
cout <<"+ " << result << endl;
result = a - b;
cout <<"- " << result << endl;
result = a * b;
cout <<"* " << result << endl;
result = a / b; // 被除数不能为0
cout <<"/ " << result << endl;
result = a == b ? true : false;
cout << "== " << result <-
竞赛测试提交模板
#include
#include
#include
#include
#include
using namespace std;
#define DEBUG
int n,m;
int a[100000];
int main()
{
ios::sync_with_stdio(false); // 取消cin与stdin同步,提高读取速度。数据规模超过几千时,不使用流来输入输出
std::cin.tie(0); // 可以通过tie(0)(0表示NULL)来解除cin与cout的绑定,进一步加快执行效率
freopen("file_name.in","r",stdin);
freopen("file_name.out","w",stdout);
cin>>n;
for(int i=0; i> a[i];
/* 调试代码在不用时,不应该直接删除,而是应该注释掉,以免给重新使用带来麻烦。不过,忘记把调试代 码删除,竞赛就不美好了 */
// 所以把调试代码放到#ifdef 块中
#ifdef DEBUG
//调试代码
#endif
return 0;
} 在 IDE 的编译选项中加一个参数: -DDEBUG
 在竞赛的时候就不会因为忘记删除调试代码而丢分了
在竞赛的时候就不会因为忘记删除调试代码而丢分了
-
程序计时/卡点测试
C++ 程序性能吞吐量计算
double start = clock( );
//******************************
//放要测定运行时间的函数 function()
//******************************
double end = clock( );
cout << ( end - start ) / (CLOCKS_PER_SEC) << "秒" << endl;
// CLOCKS_PER_SEC * 60 就是以分钟为单位
/*
卡点:设一个计数器 cnt,表示程序进行运算的次数。
把ta放到循环或递归中,判断,如果超过某一个
数(小于 5,000,000),就说明 "超时",应该立刻结束程序。
*/-
自制调试器
OI简易调试器
#include
// DIY _DeBug带参数
#define _DeBug(demo) demo ? 0 : fprintf(stdout, "Passing [ file: %s ] in [ function: %s ] in [ line: %d ]\n", __FILE__, __FUNCTION__, __LINE__)
// DIY _DEBUG无参数
#define _DEBUG printf("Pass failed:[ file xyz %s ] in (line nnn %d)\n", __FUNCTION__, __LINE__)
int main( )
{
int a = 0, b = 3;
a ? _DEBUG : _DeBug(b/a); // 被除数不能为0
return 0;
}
/*
ANSI C 规定了以下几个预定义宏,ta们在各个编译器下都可以使用:
__LINE__:表示当前源代码的行号;
__FUNCTION__:表示当前源代码的函数名;
__FILE__:表示当前源文件的名称;
__DATE__:表示当前的编译日期;
__TIME__:表示当前的编译时间;
__STDC__:当要求程序严格遵循ANSI C标准时该标识被赋值为1;
__cplusplus:当编写C++程序时该标识符被定义。
*/
软件开发简易调试器
#ifndef __dbg_h__
#define __dbg_h__
// 防止文件重复包含
#include
#include
#include
#ifdef NDEBUG
// 如果有定义 NDEBUG,那么所有的 宏都不会有效
#define debug(M, ...)
// debug第一种实现,
#else
// 如果没有定义 NDEBUG,就会得到下面的 debug...
#define debug(M, ...) fprintf(stderr, "DEBUG %s:%d: " M "\n",\
__FILE__, __LINE__, ##__VA_ARGS__)
// debug第二种实现,接受可变参,利用##VA把多余的参数放入 (...)
#endif
#define clean_errno() (errno == 0 ? "None" : strerror(errno))
/* 给终端用户看 */
#define log_err(M, ...) fprintf(stderr,\
"[ERROR] (%s:%d: errno: %s) " M "\n", __FILE__, __LINE__,\
clean_errno(), ##__VA_ARGS__)
#define log_warn(M, ...) fprintf(stderr,\
"[WARN] (%s:%d: errno: %s) " M "\n",\
__FILE__, __LINE__, clean_errno(), ##__VA_ARGS__)
#define log_info(M, ...) fprintf(stderr, "[INFO] (%s:%d) " M "\n",\
__FILE__, __LINE__, ##__VA_ARGS__)
#define check(A, M, ...) if(!(A)) {\
log_err(M, ##__VA_ARGS__); errno=0; goto error; }
// 用于判断,确保A为真,如果不是就记录错误 M,接着跳转到函数的 error 去清理, error标签定义在处理函数末尾
#define sentinel(M, ...) { log_err(M, ##__VA_ARGS__);\
errno=0; goto error; }
// 放到函数中不该运行的位置(类似 default),运行了就打印一个错误的消息,也跳转到 error ...
#define check_mem(A) check((A), "Out of memory.")
// 确认指针是否有效,如果无效会报告 "内存不足"
#define check_debug(A, M, ...) if(!(A)) { debug(M, ##__VA_ARGS__);\
errno=0; goto error; }
#endif
/* 教程链接: http://ewm.ptpress.com.cn:8085/preview?qrCode=qr2018001493&verified=true
测试代码在ex19: https://github.com/zedshaw/learn-c-the-hard-way-lectures
*/ -
分治算法
void solve(p) // p表示问题的范围、规模或别的东西。
{
if( finished /* p的规模够小 */ ){
// 用简单的办法解决
}
// 分解: 将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题
// 一般把问题分成规模大致相同的两个子问题。
for(int i=1; i<=k; i++) // 把p分解,第i个子问题为pi
// 解决: 若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
for(int i=1; i<=k; i++)
solve(pi);
// 合并: 将各个子问题的解合并为原问题的解。
......
}基础算法设计
算法设计,这里说的是设计其实是设计能力,而不是设计原则。
以我们上面的 锲子 为例子,
问题 :BOSS 让我们帮助设计工业机器人(机械臂)的Tool - path , 已完成各种事情。
上面我们分析了问题,并学术表达出来(集合):
分析问题,除了搞定问题表达的意思外,还有对应的输入输出,从而函数原型就确定了。
分析问题的水平,是需要不断训练,同时对计算机知识也需要广泛涉猎。 对编程而言,分析问题的能力比解决问题的能力重要。
- 输入:集合P,包含n个点
- 输出:访问集合P中所有点的最短路径(花费时间最少), 再回到P1
根据上面的分析,得到了输入输出从而确定算法的函数原型。
1. 原型设计
一个函数的原型如,void print( void ){ ... } 是由返回值、函数名、形参、函数体组成。
- 传什什么参数给函数
以什么数据作为结果返回,如果函数返回一个指针或引用,您是否天真地返回了函数内部的变量?
为算法取一个好的函数名 (猛击 命名法则,即可学习)
现在为工业机器人设计以函数实现的最短路径的算法。那么我们该选择什么算法 or 算法思想解决最短路径问题。
资料: 最短路径漫画指南
看了资料后您可能已经打算采用 Dijkstra 算法。可,回想一下,我们从任意点P1开始,也许ta左右俩边都有 Pa 和 Pb,那么在左边的 Pa, 在机器人数轴上与P1的距离是负数,右边的Pb与P1的距离才是正数。这里,安利一个解决负权边的算法: Bellman-Ford
/* n 为顶点个数, m 为边的个数 */
#define T int
T dis[n] // 存储源点P1 到 P2、3、4、... 、n 的距离...
T u[m], v[m], w[m] // 存储边的信息,u[i]是第i条边的起始顶点,v[i]是第i条边的终止顶点,w[i]是第i条边的距离
for i in [0, n-1): // n-1 次
for j in [0, m): // m 次,枚举每一条边
if ( dis[ v[j] ] > dis[ u[j] ] + w[j] )
// 松弛操作,如果从其ta顶点到第 v[j] 点比直接从源点到第 v[j] 点更近,就更新其ta顶点的距离
dis[ v[j] ] = dis[ u[j] ] + w[j] 那么,你能不能为这个算法设计一个函数原型呢,名字叫 Bellman-Ford ?回想之前分析的输入和输出。
bool Bellman_Ford ( int begin );
// 因为 Bellman-Ford 还可以用来检测是否有负权回路,所以可用 bool, 不检测用 void 也行, 参数begin 是源点P1
- 输入:输入边数、顶点数,读入所有边的长度
- 输出: dis[m] ,最短路径保存在dis[m]里了
对一道题完全没想法时,多半是没有分析好,这时候反复要读题。分析好以后,知道就知道该用什么知识对答,这时候考验的是编程能力了,分析考验的是算法能力,当写好了主函数模版,接下来就思考实现某个算法ta的原型是怎样的,反复练习让其成为一种习惯, 后面我还会讲 DP ...
如果编写函数时,名字类似于这样的,
strlen_(...);
_strlen(...);
// 为了提高可读性,应把函数名用括号围起来,
( strlen_ )(...);
( _strlen )(...);因为,人有时候比较粗心,就是看不到下划线。
2. 参数设计
我觉得参数设计是在原型设计里最主要的,设计的好,程序简洁,递归可以避免因多层函数参数入栈而引起的爆栈。
比如,二分查找。
bool binary_search( ... );
原型如上,因为要返回是否找到要么直接返回数的下标,要么就返回一个布尔值。千万不要在这个子函数里面输出,找到没找到,这样会提高模块化的耦合性,这样相当于告诉别人,我是新手中的新手。
设计参数,
#define T int
bool binary_search ( T arr[], T key, int len )
// 被查找的数组 查找的值 被查找数组的长度参数虽然正确,不过也并不好。因为查找是不需要修改目标数据(被查找的数组),没有保护数据。key和len,运行时,因为是传值,会创建(占空间)副本给形参,我们可以改成传引用减少不必要的空间。但如何数据量巨大,采用引用影响效率因为引用是间接寻址,传值是直接寻址所以速度比引用、指针快。
#define T int
bool binary_search ( const T arr[], const T& key, const int& len );
// 算法不需要修改数据时,都应设计为 不可修改类型,这样的设计原则其实非常敏捷
// 传引用避免形参拷贝还可以把数组长度的参数去掉,
#define T int
const int len = 10;
bool binary_search ( /* const T (&arr)[len], const T& key */ );传引用,如果把函数形参的len 换为 10 , 就可以检查数组是否溢出,如果传进来的数组长度不等于[len],编译就不过。
3. 边界设计
- 形参指针是否为NULL,处理字符串时,指向的是不是 '\0'。 p.s. '\0' == 0
-
ptr == NULL || *ptr == '\0‘ - 函数参数中缓存的⻓长度是否在合理理范围
-
len <= 0如果类型是浮点数,因为实数在计算和存储时会有误差,因此本来是零的值,由于误差的原因判断为非零。所以,判定方法要改。
-
// 采用绝对精度判断, 原理:判断ta的绝对精度是否小于一个很小的数,如 0.000 001 double eps = 1e-6 if ( fabs(a) <= eps ) // 等于0 if ( fabs(a) - fabs(b) <= eps ) // 俩个数相等 // 当变量 a、b 在 eps 精度附近时,判断失误。还有 相对精度 和 绝对精度+相对精度 的判断方法还可以用C++中的RTTI对参数的类型进⾏行行检查。依然以二分查找为例,判断边界。
#define T int
bool binary_search ( const T arr[], const T& key, const int& len )
{
if ( len <= 0 || arr == NULL || *arr == '\0' )
// 短路表达式优化,一真必真,避免不必要的判断, 所以把最高频的放在最左边,其余同理
return false
}
参数的设计,当设计到模版参数即通用类型时,要把所有类型情况都考虑进来。
乘高铁时,保安检查的非常严格,人和物品都要扫描,检查一切违禁物品,哪怕带的刀是切橡皮的,检查人员也会没收并登记不良信息。这就是我们学习的榜样。
避免程序在运⾏中出错,避免各种漏洞的产生。如,
曾经的SSL协议中的心脏流血漏洞,就是因为服务端程序在处理时,没有验证来⾃客户端对应的缓存⻓度有效性,造成了该漏洞的产⽣。
被号称漏洞核弹的 微软CVE-2017-0290漏洞,也只因在扫描引擎MsMpEng的NScript模块中没有对输入的参数类型进⾏检查,默认当做字符串来处理造成的。
更加全面的边界设计:
数据类型与数据结构的区别,
我准备盖栋房子,需要各种已经做好并组合的物件,ta是房子的骨架,ta也是程序中的数据结构;当使用各种不同尺寸和标号的钢筋,如,按直径分,钢丝(直径3~5mm)、细钢筋(直径6~10mm)、粗钢筋(直径大于22mm),这些钢筋即程序中的数据类型,做横梁也许用10mm的钢筋,做楼梯也许用22mm的钢筋,这和程序的 int 与 unsigned int 类似。
所以,数据类型是边界设计必须考虑的。
数据类型有:数值、字符、位置、数量、速度、地址、尺寸等,都包含确定的边界。
考虑的特征:第一个/最后一个、开始/完成、空/满、最慢/最快、相邻/最远、最小值/最大值、超过/在内、最短/最长、最早/最迟、最高/最低。这些都是可能出现的边界条件。边界条件测试通常是对最大值简单加1或者很小的数和对最小值减少1或者很小的数,如:
-
第一个减1/最后一个加1; 开始减1/完成加1; 空了再减/满了再加; 慢上加慢/快上加快; 最大数加1/最小数减1; 最小值减1/最大值加1; 刚好超过/刚好在内; 短了再短/长了再长; 早了更早/晚了更晚; 最高加1/最低减1。 - 隐式类型装换,
#include
void demo( int a )
{
std::cout << a; // a = 255
}
int main( ){
char a = -1;
demo(a);
} 若比较有符号和无符号时,C/C++编译器会把有符号类型转换为无符号类型,但不会 "溢出"。
- 溢出
俩个相同类型相加或相乘产生的 "溢出" ,如 :
#include
int main( )
{
int a = 2147483647; // 2的31次方
int b = 1;
a += b;
if ( a + b < 0 ) // a + b = -2147483648, 溢出
do something...
} 4. 性能设计
算法性能,我们在算法分析一起学习,这里是代码优化 !
程序通常由 顺序、选择、循环 三大结构构成,对程序性能影响最大是循环。我们在循环结构下功夫,性能会好很多。
非扩展循环的实现:
int a[1000];
// 要求: a[1000] 所有元素赋值为 3
// 基本操作,循环1000次
for (int i = 0; i < 1000; i ++ )
a[i] = 3;
// 花里胡哨, 但大大提高性能的循环
for (int i = 0; i < 1000; i += 5 )
a[i+0] = a[i+1] = a[i+2] = a[i+3] = a[i+4] = 3;
// 判断结束条件i<1000 和 计数器i频率 都减少了 4/5, 效率提高了80% 。使用第二种循环,判断结束条件i<1000 和 计数器i频率 都减少了 4/5, 效率提高了80% 。
- 循环总次数 / 单次循环 赋值次数 = 实际循环次数
选择合适的尺寸,盖房子,钢筋选长了会浪费,短了,也不合适。数据类型也如是。
使用单精度浮点数代替双精度浮点数,可以提高单次运行时间的 2.5 倍。
定义一个单精度浮点数时,初始化或赋值在数后加 f,
-
float x = 1.732f;
不加f,1.732是一个双精度浮点数,而后给 x 还会隐式转换。不信,你看看汇编语言生成的代码。另外,无符号数后缀 + u。
定义结构体或者类时,变量按照顺序定义。越小的放在越前。
-
typedef struct stu{ char a; // 1 byte short b; // 2 bytes int c; // 4 bytes long long d; // 8 bytes }S;
循环中,避免不必要的计算,如
-
for (int i = 0; i < sqrt(100); i ++ ) do something...
sqrt(100) 提前算好,保存到一个变量里面。 i < 存储变量 就好,这样就少了 100 次计算。
从快到慢相对速度排序,加法 >> 减法 >> 乘 >> 除 >> 取模 >> 函数调用入栈出栈,使用位运算,资料: 位操作
一部分除法、求余可以用位运算,也可以自己实现。
-
/* 取模优化,a % b = c */ // 如果被模数 b 是 2次幂,可以运用位运算 a & (b-1) = c // 使用更相减损术 while(a >= n) a -= n; r = a; // 余数 r, 要考虑 a == n 的情况
打开O2优化,下面代码放到程序开头即可
-
#pragma GCC optimize(2)
数据量成千上万,使用读入、输出优化模板
-
void read(int &x){ int f = 1; x = 0; char s = getchar(); while( s < '0' || s > '9' ){ if( s == '-' ) f = -1; s = getchar(); } while( s >= '0' && s <= '9' ){ x = x*10+s-'0'; s = getchar(); } x *= f; } -
void print(int x) { if( x < 0 ){ putchar('-'); x = -x; } if(x > 9){ print( x/10 ); putchar( x%10+'0' ); } }
使用位运算:资料
5. 出错设计
C++、Python ... 这些语言在解决出错的时候多通过异常处理,不过异常在 C语言 里有一些问题。在C语言中,我们只有一个返回值,但异常是一个基于栈的返回系统,ta返回的东西是不确定的。很多编程语言直接把所有边量都放在了堆。
我最喜欢的出错处理方式就是 goto 了。想起来,就开心。优美,简洁,适合小白。
-
#includeint fun(void) { if( finshied ) goto err_1; // 一定是往 return 方向跳 if( finshied ) goto err_2; /* goto语句 和 err的标签 之间 不能有 定义变量的操作 e.g. int a = 9, 但声明可 int a */ return 1; err_1: do something; // 只能调到当前函数, err 一般在函数分界处 err_2: do something; }
使用 goto 还可以定义程序通用宏,具体方法参见上面自制调试器模版。
6. 算法技巧设计
呀哈,昊滋。心理学的课上,你填的什么?一下课我就迫不及待的问。
诶,你填了三个股票... 以后打算炒股吗 ?
昊滋很随意道,是啊,每月我都有余额打算用来买股票。
一想起这家伙每个月都留有 500 块RMB,ta老妈有时候直接向ta拿钱。我就非常郁闷了,同九义汝何秀!!
我也不知道,ta具体每个月有多少钱。倒也不会太多,因为ta很会使用资源。比如,和ta一起吃饭,ta从来吗剩过几粒饭,饭吃完了盘子就像瓷器一样,光洁。ta点的菜不会没油吧...
突然侧过脸和我说了一句:"Debroon,最近在研究公司股票,需要找股票最长的增长期,能不能写一个程序帮我计算出来。"
啊,哈,你,说。尽管对股票一无所知,但我最近也在学习编程,再说万一我会呢。
我已经说了呀,股票最长的增长期。
...... ? ! !
我已经手算了,一部分增长净值。我看公司的数据有几千个点,以后还会增加,我算不过来所以想找你帮忙。
" 行,先解释解释, 最长增长期 ?",云淡风轻大师应该具备的样子。
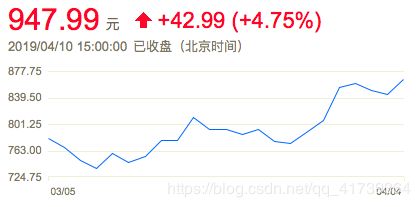
最长增长期啊,股票涨的最快的部分。你看一下这是茅台的股票曲线图,把ta们的数据记录下来,接着分析这些数据作为分母来衡量投资人的表现,这样大概就能推演出现在的茅台股票记不记得我投资。
 贵州茅台
贵州茅台
这是一个月份的曲线图,最长增长期就是曲线最低点到曲线最高点,不过最高点必须在最低点右边。因为没买这么卖呢?而有效增长期是比大盘涨的快的那部分。当一只股票涨速超过股指时,购买和持有ta才有意义。因此,扣除整个市场对股票价格的影响,当股票每天上涨的速度超过股票指数,有效增长是正数,低于就是负数,看看我计算的,使用差分即可。
| 天 | 参照数 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 价格 | 100 | 101.5 | 89.2 | 92.4 | 86.9 | 110.1 | 113.3 | 111.9 | 99.7 | 133.9 | 139.3 | 131.5 | 132.6 | 127.7 |
看到第 1 天的有效增长是 1.5,单位是基本点(万分之一)。表示第 1 天比大盘多涨了 1.5 个基本点 ?,第 2 天又比大盘多跌了 12.3 个基本点 ?。上面只记录了 13 天,还有几千天呢!最长有效增长期是,第 5 天买入,第 10 天卖出。
哦哦,我明白了。如果我把这些基本点放入数组中,那么最长有效增长期本质上就是数组的最大子数组。
第一步 爬取数据,采集公司的数据所有基本点并存到文件里,资料:爬虫专题
-
double arr[] = { 100, 101.5, 89.2, 92.4, 86.9, 110.1, 113.3, 111.9, 99.7, 133.9, 139.3, 131.5, 132.6, 127.7 }; // 部分基本点 size_t len = sizeof(arr)/sizeof(arr[0]); // 数组长度
接着,放到数组里面,求这个数组的 最大连续子数组和。哦对了,爬下来的数据都是正数,需要提前处理,否则整个数组就是最大值因为没有负数。解决也简单,使用差分,与前一天比较再存储到数组里。
-
for (int i = 1; i < len; i ++ ) // len 是所有基本点的数量, 从第1天开始 差分 arr[i-1] = arr[i] - arr[i-1];
现在看看,计算结果是不是上面有效增长期,
-
for (int i = 0; i < len-1; i ++ ) // len - 1 是因为有一个参照数不能算进去 printf("%.1lf ",arr[i]);
![]()
算法设计:
最长有效增长期是由起始日期和终止日期组成,那么我需要俩个循环找到这俩个日子,比较的就是俩个日子之间的有效期,选出一个最大的即可。
起始日可以是第 1 天到 最后一天选,可以使用循环枚举,
-
for (int i = 0; i < len; i ++ )
终止日因为不能早于起始日,所以最早只能等于当前起始日 到 最后一天中选,也可以循环枚举,
-
for (int j = i; j < len; j ++ )
接着,比较出起始日第 i 天到终止日第 j 天的有效增长期,定义一个变量,持续与之前最大数比较,
-
for (int x = i; x < j; x ++ ) sum += arr[x]; if (max < sum) max = sum;
和着这个逻辑,写好完整的代码,
#include "stdio.h"
int main(){
double arr[] = { 100, 101.5, 89.2, 92.4, 86.9, 110.1, 113.3, 111.9, 99.7, 133.9, 139.3, 131.5, 132.6, 127.7 };
size_t len = sizeof(arr)/sizeof(arr[0]);
for (int i = 1; i < len; i ++ ) // 差分
arr[i-1] = arr[i] - arr[i-1];
double max = 0.0, sum = 0.0;
size_t begin_day = 0, end_day = 0; // 记录起始日和终止日
for (int i = 0; i < len-1; i ++ ){ // len - 1 是因为有一个参照数不能算进去
for (int j = i; j < len-1; j ++ ){
sum = 0; // 当前区间叠加完毕,需要清空
for (int x = i; x <= j; x ++ ) // 起始日到终止日 x 天的有效增长
sum += arr[x];
if (max < sum)
max = sum, begin_day = i, end_day = j;
}
}
printf("最长有效增长期是: %.2lf, 在第 %u 天 买, 第 %u 天卖\n",max, begin_day+1, end_day+1);
// 数组下标是从 0 开始,但日期是从 1 开始,所以 起始日期 + 1,终止日期 + 1
}
简单分析一下,最长有效增长期的起始日共 n 种选择,终止日共 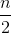 种选择,渐近复杂度即 n * =
种选择,渐近复杂度即 n * = 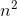 ,后来我们用一个循环累加了,起始日到终止日 x 天的有效增长,所以 * n =
,后来我们用一个循环累加了,起始日到终止日 x 天的有效增长,所以 * n =  。昊滋说,公司有上千基本点,那么
。昊滋说,公司有上千基本点,那么 ![]() = 1000 000 000,大概会有几十亿,计算机每秒运算10亿次,等几秒就好。
= 1000 000 000,大概会有几十亿,计算机每秒运算10亿次,等几秒就好。
不过。。。ta好像说,基本点还会增加。啊呀,万一哪天到上万了,那岂不是要计算上万秒!!
那么还可以继续改进不 ?
啊哈,灵机一动。发现在确定终止日时就可以统计 起始日到终止日的有效增长了。
-
for (int i = 0; i < len-1; i ++ ){ sum = 0; // 当前区间叠加完毕,需要清空 for (int j = i; j < len-1; j ++ ){ sum += arr[j]; // 确定终止日时就可以统计 起始日到终止日的有效增长 if (max < sum) max = sum, begin_day = i, end_day = j; } }
这是一个 的算法,嗷嗷~ 研究算法已经上瘾了,请问还能更好吗 ?
当然当然,敬请期待下一节分治思想导出的 n * log n 算法
7. 设计思想小百科
"销售",推动经济的发展。
这个礼拜,我逃课了。找了一份销售的工作,这是我的一个习惯,"空挡时间"。
- 连续健身几个礼拜之后,会有一个礼拜空着,
- 连续七日一日三餐的吃饭,会有一个日不吃晚饭,
- ......
所以,我跑过来专心销售。那么为什么选销售 ?
因为我被销售人员说服了,ta说: "你不是在学习计算机吗,有没有听过 分治策略" ?
"知道啊 分治是计算机科学本质之一。",遇到一个沦落人有点兴奋的道。
"那你听说过 "杜邦分析" 吗 ?",眼中带着光泽的问我。
0.0
"并不知道!很 NX 吗 ?", 望着手表回答。
那我和你说说,"杜邦分析",提出ta的人是杜邦公司的员工布朗,采用的就是 "分治思想",我也是后来才知道这个思想应用如此广泛。1912年以前,财务管理非常复杂,当杜邦分析出来后,很多周转财务变成机械计算,如净资产收益率。

你看,ta的公式是分解后为 3 个部分的,这样就凸显出 最主要的东西,销售利润率、资金周转率、权益乘数。
销售利润率代表的是企业卖的产品是否赚钱,利润高不高。要提高利润率,可以提高销售价格。
我们想一想,这个方法对房地产企业来说可行吗?现在房价已经很高了,再提高售价能买得起房子的人就更少了,对 销售额 定有负面影响。再加上地产行业的调控,行业平均利润率的总体下滑趋势非常明显,所以这不是一个可能的路径。权益乘数,权益乘数和负债率有关。资产负债率越高,权益乘数越大,净资产收益率就越高。房地产公司擅长用客户的钱来赚钱,所以负债率比其他行业的企业都高,没什么空间继续增加负债了。另外,现在政策导向是“去杠杆”,地产企业也需要控制负债风险,所以这个提升收益率的路径似乎也不可能。
资产周转率的核心是,一个字——“快”。周转率越高,说明公司资产运用效率越高,每块钱的资产,能带来更多收入。
这就是房地产企业这两年突然转型,开始推行高周转模式背后的财务逻辑。
当外部销售不能增加时,提升周转速度是内部提升收益,也就是在企业内部找钱的一个重要方法。这就是 "杜邦分析" NP的地方之一。
嗷呜嗷呜,江涵秋影雁初飞,与客携壶上翠微,不是在准备英语考试吗!
如果采用分治策略,先定一个输入,即考试分数提高 40 分。这时候,看着英语试卷是没有意义的,我们要拆分,把ta分成 "阅读理解"、"口语"、"听力"、"写作"。而后,把各个点 可提高的概率 排序,并按照排序级数高的点努力即可。
现在,我可以用 "分治"算法,解决股票最长的有效增长期。
哦,股票。有兴趣我加入。
好,我们先看看分治算法的模板...
-
void solve(p) // p表示问题的范围、规模或别的东西。 { if( finished /* p的规模够小 */ ){ // 用简单的办法解决 } // 分解: 将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题 // 一般把问题分成规模大致相同的两个子问题。 for(int i=1; i<=k; i++) // 把p分解,第i个子问题为pi // 解决: 若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题 for(int i=1; i<=k; i++) solve(pi); // 合并: 将各个子问题的解合并为原问题的解。 ...... }
那么 模板的P 就是我们存储基本点的 数组,这样输入我们也就分析出来了即 一个数组。
结束条件:
思考一下,存储基本点的数组最小的情况是什么?
- 没有元素,是空数组
- 只有一个元素,只需要判断和 0 比谁大,选最大值
考虑最常见的情况,
数组P有俩个元素及以上,显然还需要计算,所以不是最小情况,最小情况是没有元素和只有一个元素。
| P |
分解后 :
分解为俩个子问题,俩个数组近似
| a | b |
Low Mid High
解决后:
在 a 区间,我们找到的最大子数组和,肯定是子数组 a 中的 某个区间,[Low, Mid]
在 b 区间,我们找到的最大子数组和,肯定是子数组 b 中的 某个区间,[Mid+1, High]
还有一种因分解而来的情况没考虑,如果子数组 a 的 终止日是a 的最后一个元素,那么子数组b的开始元素:
是正数还可以继续衔接呀,加一个正数自然大于之前的值;
相反是负数,也得继续扫描因为后面的正数可能会大于俩者之间的负数而形成新的最大子数组和,[Low, Mid]  [Mid+1, High]
[Mid+1, High]
| |
合并:
上面的分解,我们算出来了 3 种情况的最大数组和,现在比较这 3 个最大数组和,答案就出来了,不是吗?
#include
#define MAX(x,y,z) (x>y?x:y)>z?(x>y?x:y):z
#define max(x,y) x>y?x:y
double arr[] = { 100, 101.5, 89.2, 92.4, 86.9, 110.1, 113.3, 111.9, 99.7, 133.9, 139.3, 131.5, 132.6, 127.7 };
double max_array(int l, int u){
// 没有元素
if (l > u)
return 0;
// 有一个元素
if (l == u)
return max(arr[l],0);
double sum = 0.0;
int mid = l + ( (u - l) >> 1 ); // int mid = (l + u) / 2,这样写防溢出速度也比除法快
// 扫描 a 的最大子数组
double l_max = sum = 0.0;
for (int i = mid; i >= 1; i -- ){
sum += arr[i];
l_max = max(l_max, sum);
}
// 扫描 b 的最大子数组
double r_max = sum = 0.0;
for (int i = mid+1; i <= u; i ++ ){
sum += arr[i];
r_max = max(r_max, sum);
}
return MAX(max_array(l, mid), max_array(mid+1, u), l_max+r_max);
// 3 种情况的比较
}
int main(int argc, const char * argv[]) {
int len = sizeof(arr)/sizeof(arr[0]);
for (int i = 1; i < len; i ++ ) // 差分
arr[i-1] = arr[i] - arr[i-1];
double result = max_array(0, len-2);
// len-2是因为,一: 数组下标从 0 开始 二: 再 -1 是有一个参照数 100
printf("result : %.2lf", result);
return 0;
}
简单不简单,这比之前的算法更快,比第一个几个基本点时需要上万秒算出来,现在 1 秒都不需要。
我们去找昊滋一起讨论讨论,打算百度一下...
等等,我知道了,"逆向":
起始日可以是第 1 天到 最后一天选,可以使用循环枚举,
终止日因为不能早于起始日,所以最早只能等于当前起始日 到 最后一天中选,也可以循环枚举,
你们看,选择终止日在不确定起始日时,可以直接从头到尾扫描,这样就能找到股票开始跌的日期,
如果选起始日时,也是从头开始扫描,那有一种情况就解决不了即最高点在最低点左边。因为扫描的终止日是数组中的最高点,扫描的起始日是数组中的最低点,这样扫描并没有把顺序考虑进来。
从头扫描可以找到终止日期,那么我们为什么不反过来呢?
选择起始日时,从尾到头的扫描,就能回溯到股票涨幅的日期。这样即在
的(渐近意义上)线性时间里找到了答案,也解决了顺序的问题。
p.s. 在动态规划的博客里,也给出最大子段和
设计思想资料 : https://wx.zsxq.com/dweb/#,微信扫一扫可以加入,接着搜索设计模式与思想即可。
- 基础 DP 的基础(更新ing ...)
- 基础枚举的基础
- 基础分治的基础
- 基础迭代的基础
- 基础搜索的基础
- 基础递归的基础
8. 如何设计算法/解题
认知心理学说,人类最有效地解决问题方式,是 "目标-手段分析法"。
这是一种 确认目标,一层一层地分解,大问题变一组小问题,每一个小问题都有实现的手段,而后去做就完成哩✅。
如果 "目标-手段分析法" 用在算法设计上,流程大致是如此。
- 确认目标
- 分析过程
- 先面向过程
- 行行实现代码
- 代码封装
最重要的是确认目标,最难的是分析过程,因为这是脑力活;后面的代码一行行实现在封装,只是体力活。
数学说,弄懂定义的定义。
- 先读问题
- 反复确认定义
- 习惯 OO 指代 OO 的说法
- 用数学公式表达
- 思考这个问题的所有,是什么、有什么性质......
- 分析过程时,可以放宽约束和增加约束。给问题增加一些条件或删除一些次要条件使问题变得清晰。
现实:每天刷定量的OJ题目,刷完后看题解。
基础算法分析
算法分析,这里说的是分析其实是分析工具,而不是分析能力。
0. 数学归纳法
您,有没有听过一句话 : " 计算机科学家是只知道用归纳法来证明问题的数学家"!
说法基本属实,计算机科学家研究的算法大多是增量式和递归的,一种数学归纳法就够用了。因为数学归纳法通常是证明一个递归或增量式算法的正确思路。
若有命题 P(n),需要证明对正整数 n 成立。
- 步骤1: 基底证明
- 证明 P(最小情况) 成立
- 步骤2: 归纳证明
- 证明 P(k) 成立,那么 P(k+1) 也成立。
- 步骤3: 证毕
- 结合步骤 1、2,得出结论 P(n) 对 ba bala 成立。
e.g. 证明 0 到 n 的整数之和与 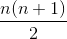 相等 。
相等 。
最小情况 P(0) 代进去,
, 0 = 0 ,P(1) 成立。
一般情况,把 0 以上的任意数 n 代入,若 P(n) 成立,则以下等式成立:
接着,代入 n+1。若 n+1 成立,则以下等式成立:
(n+1是增加了一项,公式需要末项+1)
n+1是因为增加了一项则归纳法的步骤1 和 步骤2 都得到了证明,则:
0 到 n 的整数之和与
是不是依然感觉不清不楚的,其实ta和程序的递归是一样的,有边界条件和一般条件。以一般条件一步步将问题分解为越来越小的子问题,直到达到边界条件会终止递归。懂递归自然就懂归纳了,所以把ta当成递归即可,看看程序。
#include
typedef int T;
void prove( T n )
{
T k = 0;
if( 0 == n ){
printf("根据步骤1(基底证明) 得出P(%d) 成立。\n\n",n);
} else {
prove( n-1 );
printf("根据步骤2(归纳证明) 可说“若 P(%d) 成立,则 P(%d)也成立”。\n\n", n-1, n);
printf("因此可说 “P(%d) 是成立的。”\n\n", n);
}
return;
}
int main(void)
{
T n;
scanf("%d",&n);
puts("证明断言 P(n) 对于给定的 0 以上的整数 n 都成立\n");
printf("现在开始证明 P(%d) 是否成立?\n\n",n);
prove(n);
puts("证明结束");
return 0;
}
数学归纳法,重点是 "归纳"。ta可以总结事物发展的规律,只有证明这个规律是对滴,就可以得到事物任意发展阶段的结果,这样可以节省时间和计算资源。证明一般良基结构,例如:集合论中的树。在计算机科学中的是一种特殊的数学归纳法,ta叫 "结构归纳法"。
- 递归,计算交给了计算机,以计算机计算成本换人的时间;
- 归纳,计算交给了人,以人的时间换计算机的计算成本;
- 递归的调用代码与数学归纳法的逻辑一致,俩者互通。
归纳法: 假设一条腿可以向前迈一步,而后假设另一条腿无论什么情况都可以迈过去,这样就可以到无限的远方。
1. 对数
 记忆对数的方法
记忆对数的方法
对数是由算法单词(algorithm)换位得到的,algorithm -> logarithm。也是初等函数中指数函数的逆运算,
![]() < - >
< - > ![]()
- 对数和三角函数一样,在天文学应用广泛。对数的计算工具有: 计算尺、计数表
与之相关的例子:
- 用于算法分析中如 二分查找:O(log n)、
- 在生活中如法庭的惩处表,惩罚随犯罪等级呈对数增长、
- 完全二叉树的深度(高度):
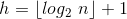 ,给出数学证明:
,给出数学证明:
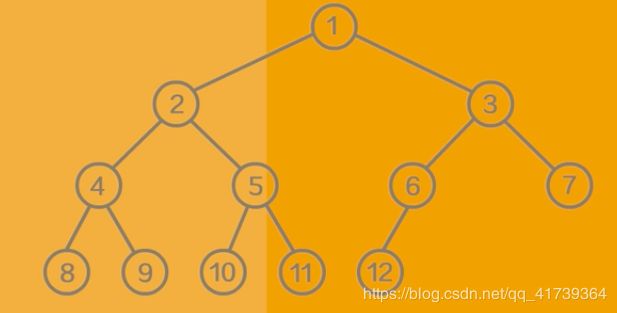 高度为 h = 4
高度为 h = 4
完全二叉树是除最底层之外其ta所有结点都是满的,还有最底层的所有结点都集中中最左边。
所以,除最底层(h = 4)之外的所有层(h = 1、2、3)结点数都满足
,如 第二层 h = 2,第一层结点数是
。
假设,一个完全二叉树有 n 个结点、高度为 h。
因为完全二叉树最底层结点数不确定,所以我们取一个范围讨论...
最小情况,以上图为例即 1 - 7 为满二叉数加一个结点 8 就是完全二叉数。结点数为
,
最大情况,第 4 层也是满的,这是一个满二叉数。结点数n为
同时取以 2 为底的对数
,
化简,
推出,
对数的特性
![]() < - >
< - > ![]() ,
,
二进制对数,广泛用于对数算法 即 (底) a = 2 时, 可简记为 ![]() 。
。
自然对数,(底) a = 2.71828... 简记为 ![]() 。
。
常用对数,(底) a = 10,简记为 ![]() 。
。
-
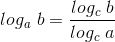 : 常用于换底 ,对数的底对数据的增长量级并没有实际影响,因此分析算法时通常忽略对数的底。
: 常用于换底 ,对数的底对数据的增长量级并没有实际影响,因此分析算法时通常忽略对数的底。 -
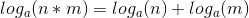 : 用于计算,上次考试这题写错了 真有点郁闷。
: 用于计算,上次考试这题写错了 真有点郁闷。 -
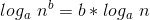 :任何多项式函数取对数后的增长量级都是
:任何多项式函数取对数后的增长量级都是 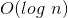 。
。
实现 ![]() :
:
size_t log_2( size_t n )
{
return n > 1 ? 1 + log_2( n >> 1 ) : 0;
}2. 主定理
掌握主定理最好先学会基本的递推式分析,逐步提高难度。
"主定理" 的快速记忆
......
3. 渐近记号
记录在渐进记号的博客里
4. 高等分析
5. 分治策略
6. 组合计数
记录在 多项式
7. 排序算法
8. 摊还分析
9. 概率论与多项式
多项式,记录在 多项式
概率论,记录在 概率论
10. 锻炼分析能力的逻辑谜题
趣味算法小集
记录在趣味算法小集中,注释会慢慢添上。
[ 更新ing... ]