VVC新技术(汇总中)
内容非原创
帧内预测:
简介https://blog.csdn.net/u012038173/article/details/90084591#2_CCLM_66
1. 扩展角度帧内模式 :65个帧内预测模式和WAIP预测模式 :https://cloud.tencent.com/developer/article/1430270
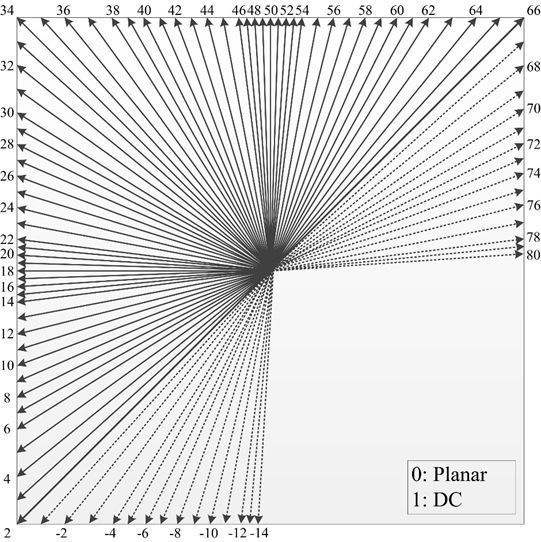
针对这个非对称问题,对于水平的预测单元,模式67~ 80被用来替换模式2~ 15;而对于垂直的预测单元,模式-1 ~ -14被用来替换模式53 ~ 66。并且VVC将MPM 列表的大小从3扩展到6 [7]。考虑到Planar 预测模式具有很高的选中概率,腾讯音视频实验室提出将Planar预测模式作为优先模式放置于MPM列表首位。
2. 跨分量线性模型预测(CCLM)
3. 位置自适应帧内联合预测(PDPC)
4. 多行预测模式(MRL)
5. 帧内子块划分技术(ISP):https://blog.csdn.net/Peter_Red_Boy/article/details/90707668
6.帧内预测MIP技术:https://blog.csdn.net/u012038173/article/details/90671165
该技术的整体框架(分为三步):
(1) 对亮度块上和左参考行进行平均操作获得采样点(4或8个)
(2) 对得到的样本进行矩阵向量乘法 ,并加上一个偏移,得到部分预测值(4×4,4×8,8×4,8×8).
(3) 进行双线性插值获得最终亮度预测值
帧间预测:
1、扩展的Merge模式 https://blog.csdn.net/baidu_28446365/article/details/88854316
VTM中的Merge模式在HEVC的基础上进行了扩展。现有的候选列表构建方式如下
1Spatial MVP from spatial neighbour CUs
2Temporal MVP from collocated CUs
3History-based MVP from an FIFO table
4Pairwise average MVP
5Zero MVs.
前两项与HEVC相同,第三项为基于历史的MV预测HMVP,第四项为Pairwise Average MVP(替代了原来的Combination)。
2、Combined inter and intra prediction (CIIP):https://blog.csdn.net/baidu_28446365/article/details/89428641
对编码块进行帧间预测Pred_inter和帧内预测Pred_intra,将两个预测块加权组合得到最终预测块。
3、亚CU级运动预测:https://blog.csdn.net/lin453701006/article/details/78924053
可选时域运动矢量预测(Alternative temporal motion vector prediction,ATMVP)
空时运动矢量预测(Spatial-temporal motion vector prediction,STMVP)
变换:https://blog.csdn.net/baidu_28446365/article/details/90174414
1.更大的变换尺寸&舍弃高频变换系数
在VTM中,允许变换的最大尺寸为64x64(原来只应用于1080p和4K)。对于长或宽等于64的大尺寸变换块,直接舍弃高频变换系数,仅保留低频变换系数。例如,对于长x宽为MxN的块,若M等于64,则只保留左边的32列,若N等于64,则只保留上方的32行。 如果当前为变换跳过模式,则保留所有变换系数。
2、多种变换核心(Multiple transform selection,简称MTS)
除了HEVC中的DCT-II变换,VVC引进了两种新的变换方式DST-VII 和DCT-VIII,帧内帧间编码块从这三种变换方式中进行选择。
量化:https://blog.csdn.net/baidu_28446365/article/details/89430095
Dependent Scalar Quantization
HEVC中,根据8bit信号的取值范围,量化参数QP取值为0~51,为了向解码端传输量化参数,编码器会首先在PPS中传输一个起始的QP,然后再在条和CU层传送增量QP值。而在VTM中,QP取值范围扩展到0 ~ 63(相应的,init_qp_minus26的取值范围变为-(26+QpBdOffsetY ) 到37),且相应的起始QP改为在slice层传输。
VTM中使用了与HEVC相同的标量量化(scalar quantization),但是对其进行了改进得到了一个新的概念——依赖性的标量量化(dependent scalar quantization,下文简称DQ)。在DQ中,重建过程中当前变换系数块的重建值(即反量化得到的值)取决于前一个变换系数块(反量化得到的值)的level(这里的前一个根据重建顺序决定)。与HEVC中传统的标量量化相比较,这个方法可以使得量化得到的用于变换的系数块在N维向量空间更紧密(N代表变换块中的变换系数的个数)。意味着对于固定大小的变换块,该方法减小了输入向量(量化前的块)和重建向量(反量化得到的块)之间误差,即减少了量化带来的失真。
为了达到上述目的,DQ主要做出了两点改进:1)定义了两种不同的标量量化器Q0和Q1,即对应了两种不同的重建像素;2)定义了两种不同的标量量化器之间的转换规则。
滤波:
VTM中环路滤波的顺序:LMCS,deblocking filter,SAO 和ALF。其中deblocking filter和SAO 与HEVC中的相同。
1、LMCS,位于环路滤波前,主要兼容HDR视频,映射。由两部分组成:1)基于自适应分段线性模型的亮度环路映射;2)基于亮度分量的色度残差伸缩。 https://blog.csdn.net/baidu_28446365/article/details/89430048
2、《Adaptive Loop Filtering for Video Coding》:ALF https://blog.csdn.net/baidu_28446365/article/details/89511554