Faster R-CNN Keras版源码史上最详细解读系列之运行源码
Faster R-CNN Keras版源码史上最详细解读系列之源码运行
- 源码介绍
- 数据集格式介绍
- 预训练模型
- 修改部分源码文件
源码介绍
我想大多数人跟我一样,而且肯定是想要把源码先跑起来,然后慢慢看里面细节。我用的是windwos,一些最基本的环境,用到的库这种我就不说啦,具体可以看项目里的requirements.txt文件,或者百度。
那就先说说keras版的源码,很多的源码是从yhenon克隆来的,但是这个貌似失效了,所以提供一个其他的,我网上找的,应该是跟原版一样的:https://github.com/moyiliyi/keras-faster-rcnn。
数据集格式介绍
然后我们准备数据,原文是用VOC2007和VOC2012的数据,但是这些数据比较大,训练和下载也比较慢,我给一个连接吧,后面可以用这个数据集训练,https://pjreddie.com/projects/pascal-voc-dataset-mirror/

为了方便我去找了一个细胞识别的数据集,几百张图,只有3个类别,训练相对快点,也是VOC格式的,https://github.com/Shenggan/BCCD_Dataset
我们先下下来看看数据集的结构,比如VOC2007:

其实对于这个项目来说,我们只要用Annotations,ImageSets,JPEGImages这三个文件就可以了,我们看看里面是什么。
Annotations:
某个000005.xml里面的内容:
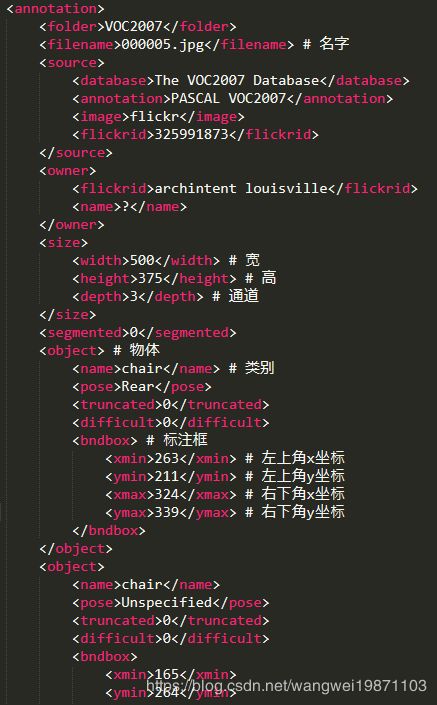
我们目标检测用的信息我基本上后面都用中文注释了,其实就是一张图片里有很多个物体,每个物体都用标注框标出来了。
ImageSets文件夹下的Main夹下我们主要关心的文件:

比如trainval.txt里面就是图片名字,包含训练集和验证集:

然后我们所选的细胞监测的数据集是这样的,相对简单点:


预训练模型
我们要运行还差一个预训练权重模型vgg16_weights_tf_dim_ordering_tf_kernels.h5,不导入会报错,当然也可以自己训练VGG16啦,不过最好还是下载预训练的,可以加快速度,模型下载。下载后建议就放项目根目录下。
修改部分源码文件
要让代码跑起来,还要修改一些参数。
首先是train_frcnn.py,其实我是改了一些参数,这样直接python train_frcnn.py,不用每次传参数,麻烦,当然你也可以每次传啦,看你喜欢。
修改训练路径:
# 训练路径,如果是voc格式,就给个目录,目录下有Annotations等,如果是简单的解析,就给解析文件,我这里改成了细胞检测的目录
parser.add_option("-p", "--path", dest="train_path", help="Path to training data.",
default="F:\AI\OpenSources\ComputerVision\dataset\BCCD_Dataset-master\BCCD")
用voc格式解析数据:
# 解析数据方式,就是VOC或者简单的解析,对应后面的keras_frcnn.pascal_voc_parser或者keras_frcnn.simple_parser
parser.add_option("-o", "--parser", dest="parser", help="Parser to use. One of simple or pascal_voc",
default="pascal_voc")
主干网络改VGG:
# 主干网络的选择,可以是vgg也可以是resnet50,resnet101,下面有对应的代码
parser.add_option("--network", dest="network", help="Base network to use. Supports vgg or resnet50.", default='vgg')
模型参数:
# 输入的预训练模型参数
parser.add_option("--input_weight_path", dest="input_weight_path",
help="Input path for weights. If not specified, will try to load default weights provided by keras.",
default='vgg16_weights_tf_dim_ordering_tf_kernels.hdf5')
然后是pascal_voc_parser.py这个文件,解析voc数据用的。
原来有data_paths = [os.path.join(input_path,s) for s in ['VOC2007','VOC2012']]
这个是将voc2007,和voc2012文件夹里面的数据一起训练:
因为我用细胞检测的数据集,所以我改成了data_paths = [os.path.join(input_path,s) for s in ['']],也就是不用加任何路径了:

最后config.py里也要改几个地方。
# 主干网络
self.network = 'vgg'
# 原图缩放时固定短边的大小,源码是600,太大可能GPU内存不够哦
self.im_size = 300
改完后在项目目录下直接运行python train_frcnn.py应该就可以了,比如我的:
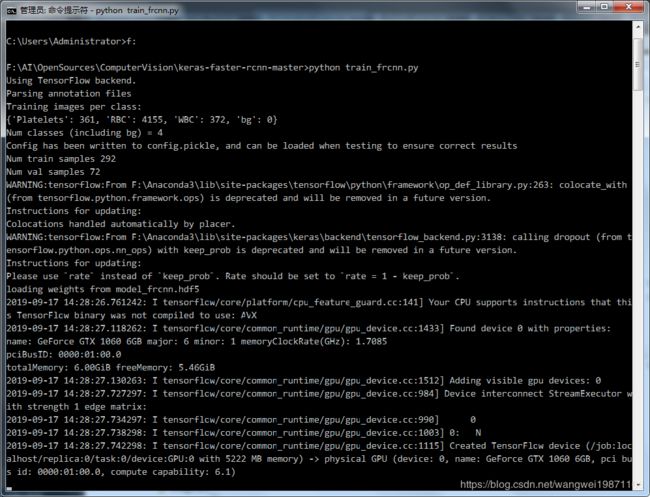
这样基本能运行起来了,但是貌似要训练好久,不过可以修改一些参数,比如训练轮次,每轮迭代多少张图,他是一次一张图训练的,其他具体的配置后面的文章会讲。

至此,这个项目应该可以运行起来啦,我们的第一步能否成功运行其实很重要,关系到我们的信心和兴趣,如果源码都跑不起来,可能会放弃去看里面的东西,毕竟要细看还是要跑起来debug的,这样是最有效率的。
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,部分图片来自网络,侵删。