2019独角兽企业重金招聘Python工程师标准>>> 
学习目标
1.掌握SOLR的搜索工作流程;
2.掌握solr搜索的表示语法及查询解析器
3.熟悉solr搜索的JSON格式 API
Solr搜索流程介绍
回顾,使用 lucene进行搜索的步骤:
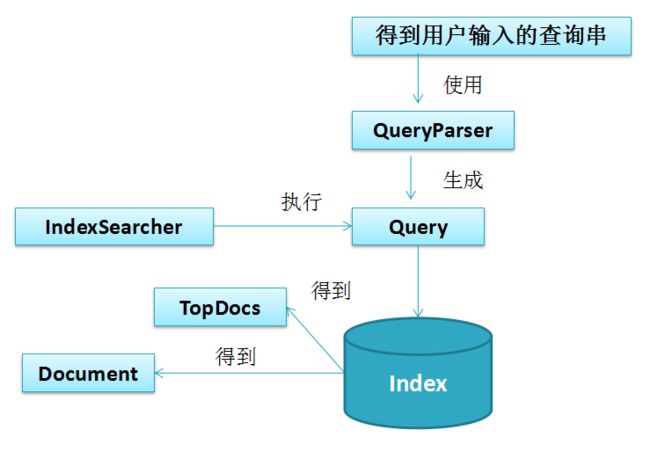
Solr搜索的工作流程

查看内核的solrconfig.xml文件,了解搜索的请求处理器配置
对比看_default、sample_techproducts_configs两种配置集的内核配置。
配置中的参数元素介绍见下一页。
仔细查看techproducts 内核的solrconfig.xml的
/select
/query
/browse
前面流程图中的各项工作都在哪里完成?
在SearchHandler
它是如何完成的?
参数元素说明

SearchHandler介绍
查询请求在SearcheHandler这个request handler中完成,各个步骤的工作由SearchHandler中组合的组件来完成了(可自定义,在该查询的requesthandler配置元素内配置)。示例,自定义组件组合:
query
facet
mlt
highlight
debug
someothercomponent
"query" (usually QueryComponent)
"facet" (usually FacetComponent)
"mlt" (usually MoreLikeThisComponent)
"highlight" (usually HighlightComponent)
"stats" (usually StatsComponent)
"debug" (usually DebugComponent)
还可在主组件组合前、后加入组件:
mycomponent
myothercomponent
详细了解: https://wiki.apache.org/solr/SearchHandler
问:SearchHandler中配置的 default是做什么用的?
默认参数设置,如果你有这样的默认查询参数需要,可这样配置。
查询语法及解析器详解

通用查询参数详解
1.defType
defType用来选择解析参数q指定的主查询串的查询解析器,如未给定默认使用solr的标准查询解析器(defType=lucene)。
Solr中提供了三种解析器供选择:
lucene: solr的Standard Query Parser 标准查询解析器
dismax: DisMax Query Parser
edismax: Extended DisMax Query Parser (eDismax)
2.sort
指定如何对搜索结果进行排序,asc 表示圣墟,desc 降序。Solr可根据如下部分对结果文档进行排序:
文档相关性得分
函数计算的结果
设置了docValues="true"的基本数据类型字段(numerics, string, boolean, dates, etc.)
存储了docValues的可排序分词索引字段(SortableTextFields)。
单值不分词索引的字段。
对于基本数据类型和SortableTextFields ,如果是多值的,排序规则:
升序:取最小值参与排序;
降序:取最大值进行排序;
如要指定用什么值:则在传参时用sort=field(name,max) or sort=field(name,min) 方式传参。
3.start
分页查询的起始行号(从0开始),没传默认为0。
4.rows
查询返回多少行,默认10(可配置)。
5.fq
Filter Query 用来在主查询的结果上进行过滤,不影响相关性评分。Fq对于提速复杂的查询非常有用。因为fq指定的过滤查询结果是独立于主查询被缓存起来的。对于下次查询,如果用到了该过滤查询,则直接从缓存中取出结果进行对主查询的结果进行过滤即可。
fq的传参说明:
可以一次传传多个fq:
fq=popularity:[10 TO *]&fq=section:0
也可将多个过滤条件组合在一个fq:
fq=+popularity:[10 TO *] +section:0
说明:几个fq就缓存几个过滤结果集
6.fl
fl(field list),指定结果中返回哪些字段,指定的字段必须是 stored="true" or docValues="true" 的。多个字段用空格或英文逗号间隔。需要评分时通过 score 指定。如果传人的值为*,则stored="true" or docValues="true" and useDocValuesAsStored="true"的字段都会返回。
7.debug
debug参数用于指定在结果中返回调试信息。
8.explainOther
在一个查询中附带解释另一个查询的评分,在结果中返回它的得分解释。这可以让我们在topN查询时理解为什么某个文档没有返回。
示例:
q=supervillians&debugQuery=on&explainOther=id:juggernaut
9.timeAllowed
限定查询在多少毫秒内返回,如果到时间了还未执行完成,则直接返回部分结果。
10.omitHeader
true/false ,如设为true,在则响应体中忽略表示查询执行状态信息(如耗时)的头。
11.wt
指定响应的内容格式:json、xml、csv…… SearchHandler根据它选择ResponseWriter。
12.cache
设置是否对查询结果、过滤查询的结果进行缓存。默认是都会被缓存的。如果不需要缓存明确设置 cache=false。
13.logParamsList
solr默认会日志记录所有的请求参数,如果不需要记录所有,则通过此参数指定要记录的参数名,如:
logParamsList=q,fq
如果都不记录:传入: logParamsList=
14.echoParams
指定在响应体的内容的头部中返回哪些查询参数,可选值:
explicit: 默认,返回显示传入的参数+
all: 应用到查询的所有参数.
none:不返回.
查询解析器介绍
Standard Query Parser
DisMax Query Parser
Extended DisMax Query parser
默认使用的是 Standard Query Parser 。通过defType参数可指定。
Standard Query Parser
solr标准查询解析器。关键优点:它支持一个健壮且相当直观的语法,允许我们创建各种结构的查询。这个我们在学习lucene时已学过。最大的缺点:它不能容忍语法错误。
Standard Query Parser 请求参数
除了通用参数外,标准查询解析器还支持的参数有:
q:用标准查询语法定义的查询表达式(查询串、主查询),必需。
q.op:指定查询表达式的默认操作, “AND” or “OR”,覆盖默认配置值。
df:指定默认查询字段
sow: Split on whitespace 按空格分割,如果设置为true,则会分别对分割出的文本进行分词处理。默认false。
Standard Query Parser 响应内容格式
请求:http://localhost:8983/solr/techproducts/select?q=id:SP2514N&wt=xml

Standard Query Parser 响应内容格式-练习
1、加上debug=all参数看看返回什么.
http://localhost:8983/solr/techproducts/select?q=cat:book&wt=xml&debug=all
2、加上explainOther参数看看返回什么
http://localhost:8983/solr/techproducts/select?q=cat:book&wt=xml&debug=all&explainOther=id:055357342X
3、把wt改为json看看与xml的不同
http://localhost:8983/solr/techproducts/select?q=cat:book&wt=json&debug=all&explainOther=id:055357342X
标准查询语法:
Term 词项表示:
单个词项的表示: 电脑
短语的表示: "联想笔记本电脑"
Field 字段:
字段名:
示例: name:“联想笔记本电脑” AND type:电脑
如果name是默认字段,则可写成: “联想笔记本电脑” AND type:电脑
如果查询串是:type:电脑 计算机 手机
注意:只有第一个是type的值,后两个则是使用默认字段。
Term Modifiers 词项修饰符:

范围查询:
mod_date:[20020101 TO 20030101] 包含边界值
title:{Aida TO Carmen} 不包含边界值
词项加权,使该词项的相关性更高,通过 ^数值来指定加权因子,默认加权因子值是1
示例:如要搜索包含 jakarta apache 的文章,jakarta更相关,则: jakarta^4 apache 短语也可以: "jakarta apache"^4 "Apache Lucene"
^= 固定分值,通过此字句匹配的文档使用固定的分值。
(description:blue OR color:blue)^=1.0 text:shoes
Boolean 操作符
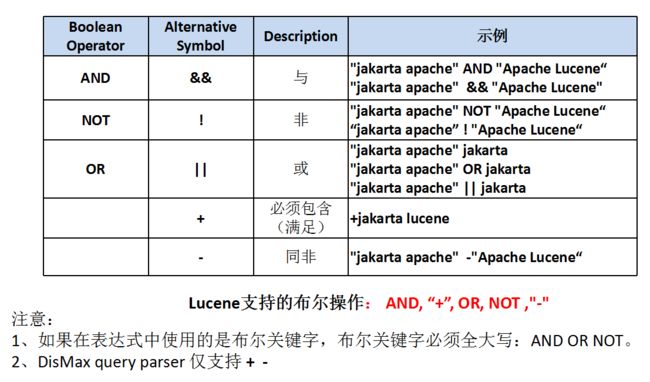
组合 ()
字句组合 (jakarta OR apache) AND website
字段组合 title:(+return +"pink panther")
转义 \
对语法字符: + - && || ! ( ) { } [ ] ^ “ ~ * ? : \ / 进行转义。 如要查询包含 (1+1):2 \(1\+1\)\:2
注释,支持C语言风格的注释
"jakarta apache" /* this is a comment in the middle of a normal query string */ OR jakarta
Solr Standard Query Parser 对传统 lucene语法的增强
在范围查询的边界两端都可以用*
field:[* TO 100] finds all field values less than or equal to 100
field:[100 TO *] finds all field values greater than or equal to 100
field:[* TO *] matches all documents with the field
允许纯非的查询(限顶级字节)
-inStock:false finds all field values where inStock is not false
-field:[* TO *] finds all documents without a value for field
支持嵌入solr查询(子查询),切入查询可以使用任意的solr查询解析器
inStock:true OR {!dismax qf='name manu' v='ipod'}
支持特殊的filter(…) 语法来说明某个字句的结果要作为过滤查询进行缓存
q=features:songs OR filter(inStock:true)
q=+manu:Apple +filter(inStock:true)
q=+manu:Apple & fq=inStock:true
如果过滤查询中的某个字句需要独立进行过滤缓存,也可用。
q=features:songs & fq=+filter(inStock:true) +filter(price:[* TO 100])
q=manu:Apple & fq=-filter(inStock:true) -filter(price:[* TO 100])
范围查询 (“[a TO z]”), 前缀查询 (“a*”), 统配符查询(“a*b”) 使用规定分值。
查询中的时间表示语法,遵守前面讲索引时的规范
createdate:1976-03-06T23\:59\:59.999Z
createdate:"1976-03-06T23:59:59.999Z"
createdate:[1976-03-06T23:59:59.999Z TO *]
createdate:[1995-12-31T23:59:59.999Z TO 2007-03-06T00:00:00Z]
timestamp:[* TO NOW]
pubdate:[NOW-1YEAR/DAY TO NOW/DAY+1DAY]
createdate:[1976-03-06T23:59:59.999Z TO 1976-03-06T23:59:59.999Z+1YEAR]
createdate:[1976-03-06T23:59:59.999Z/YEAR TO 1976-03-06T23:59:59.999Z]DisMax Query Parser
DisMax Query Parser 是设计用于处理用户输入的简单短语查询的,它的特点:
1 只支持查询语法的一个很小的子集:简单的短语查询、+ - 修饰符、AND OR 布尔操作;
2 简单的语法,不抛出语法错误异常给用户。
3 可以在多个字段上进行短语查询。
4 可以灵活设置各个查询字段的相关性权重。
5 可以灵活增加满足某特定查询文档的相关性权重。
DisMax:Maximum Disjunction 最大分离。
DisMax Query 定义:一个查询,可以为不同字段设置评分权重,在合并它的查询字句的命中文档时,每个文档的分值取各个字句中的最大得分值。
DisMax Query Parser参数说明
1.2查询参数说明
1.2.1q
指定主查询表达式。注意简单短语,不可使用通配符,+号会被当成或处理。
1.2.2q.alt
q.alt 提供一个备选语句,当q没有指定或为空时,执行这个查询。
1.2.3qf
qf指定要查询的字段及权重。
qf="fieldOne^2.3 fieldTwo fieldThree^0.4"
1.2.4mm (Minimum Should Match)
mm 用来指定当q中包含多个字句、各字句是或操作时,最少需多少个字句匹配才算匹配。mm支持非常灵活的表示方式:

mm的默认值是100%。
1.2.5pf (Phrase Fields)
pf用来设置当某个字段匹配所有查询字句的短语时,该字段的加权权重。定义格式同qf
pf="fieldOne^2.3 fieldTwo fieldThree^0.4"
1.2.6ps (Phrase Slop)
短语的移动因子。当查询给入多个词、短语时。对这些词进行短语匹配的移动因子。
1.2.7qs (Query Phrase Slop)
用户给入的q 主查询中包含短语时,通过qs可指定短语的移动因子。
1.2.8tie (Tie Breaker)
这个tie参数通常是一个小于1的浮点数,当查询命中多个field的时候,最终的score获得多少将由这个tie参数来进行调节。比如命中了field1,field2这2个field。如果field1.score= 10,field2.score=3。那么 score = 10 + tie * 3.也就是说,如果tie=1的话,最终的score就相当于多个字段得分总和;如果tie=0,那么最终的score就相当于是命中的field的最高分。通常情况下呢,官方推荐tie=0.1。
1.2.9bq (Boost Query)
bq指定一个加权查询,当主查询中命中的文档符合bq加权查询时,将获得更高的得分。
q=cheese
bq=date:[NOW/DAY-1YEAR TO NOW/DAY]AND ^5.0
bq=date:[NOW/DAY-1YEAR TO NOW/DAY]^5.0
bq=date:[NOW/DAY-1YEAR TO NOW/DAY]^5.0
可以指定多个bq参数。
1.2.10bf (Boost Functions)
bf用来定义加权函数,然后可在bq中使用加权函数
bf=recip(rord(creationDate),1,1000,1000)
...or...
bq={!func}recip(rord(creationDate),1,1000,1000)
1.3DisMax Query Parser使用举例
1.使用StandardRequestHandler查询”video” http://localhost:8983/solr/techproducts/select?q=video&fl=name+score
2.配置了查询字段:text、features、name、id、manu、cat。而且匹配上name和cat会有更高的得分 http://localhost:8983/solr/techproducts/select?defType=dismax&q=video
3.可以将score显示出来,看一下各个文档的得分 http://localhost:8983/solr/techproducts/select?defType=dismax&q=video&fl=*,score
4.覆盖查询字段,并设置features有更高的得分,而text有较低的得分 http://localhost:8983/solr/techproducts/select?defType=dismax&q=video&qf=features^20.0+text^0.3
5.希望某一字段在满足某一情况下有更高的得分 http://localhost:8983/solr/techproducts/select?defType=dismax&q=video&bq=cat:electronics^5.0
Extended DisMax Query Parser
扩展 DisMax Query Parse 使支标准查询语法(是 Standard Query Parser 和 DisMax Query Parser 的复合)。也增加了不少参数来改进disMax。
强烈建议:使用 edismax 来进行查询解析:
支持的语法很丰富;
很好的容错能力;
灵活的加权评分设置。
请求参数说明
1.sow
sow:Split on whitespace 按空格拆分。如果设置为true,则对每个单独的空格分隔的文本分别调用文本分析。默认是false;空格分隔的术语序列将一次性提供给文本分析,从而使分析筛选器的功能能够正常运行(如同义词处理)。
2.mm.autoRelax
如设置为true,当查询表达式的字句经分词过滤后在部分查询字段上(而非全部)减少字句了,最少匹配数自动放松。此参数用于解决因停用词过滤导致的查询不到文档的问题。
3.boost
加权函数查询,符合该查询的文档的得分=主查询得分 * 该加权查询得分。注意这里是乘。而 bq、bf是加
如根据各商品的热度对命中的商品文档加权
http://localhost:8983/solr/techproducts/select?defType=edismax&q=solr &pf=text&qf=text&boost=popularity
4.lowercaseOperators
true 支持 小写的 and or。
1.2.5ps (Phrase Slop)
作为短语加权匹配时的移动因子,会作为 ps2 ps3的默认值。
ps=5
6.pf2
指定要进行二元组短语加权的字段及权重,类似pf,不同之处:pf要求短语完整匹配,pf2是将查询的词分解为二元组进行短语匹配来加权。如查询的词为:solr based lucece java,pf2会对包含短语”solr based”或”based lucene”或”lucene java”的文档加权。
q= solr based lucece java&pf2=title^10 content^3&ps2=3
7.ps2
pf2使用的移动因子,如未给定则使用ps。
8.pf3
指定要进行三元组短语查询加权的字段及权重。
如查询的词为:solr based lucece java 会被分为” solr based lucece”、” based lucece java”,在pf3指定的字段上进行短语匹配、加权。
q= solr based lucece java&pf3=title^10 content^3&ps3=2
9.ps3
pf3使用的移动因子,如未给定则使用ps。
10.stopwords
控制是否在查询的分析器中开启停用词过滤,默认是true。
11.uf
指定允许用户可以查询哪些字段以及开启嵌入查询支持,默认是所有字段、不可嵌入查询: uf=* -_query_。uf值支持通配符,以空格间隔多个字段。
示例:
To allow only title field, use uf=title.
To allow title and all fields ending with '_s', use uf=title *_s.
To allow all fields except title, use uf=* -title.
To disallow all fielded searches, use uf=-*.
To allow embedded Solr queries (e.g. _query_:"…" or _val_:"…" or {!lucene …}), you must expressly enable this by referring to the magic field _query_ in uf
查询字段别名
有时我们在模式中定义的字段不适合直接给终端用户使用,如动态字段、很长的字段名(对用户使用不是很友好)。在eDismax中提供了查询字段别名机制,对用户更友好地写查询表达式,我们在默认补充别名定义。如模式中的字段名为: title_t_zh 希望以title 来给用户用。我们可以通过 f.alias.qf=realField参数来定义别名。
示例:
defType=edismax&q=title:”lucene solr”&f.title.qf=title_t_zh
因是对查询字段取别名,可以更灵活的使用:
&f.who.qf=name^20 author^30&f.what.qf=cat^5 job^10
用户在写q时可以这样写 q=who:(mike tony) what:(动脑)
defType=edismax&q=who:(mike tony) what:(动脑)&f.who.qf=name^20 author^30&f.what.qf=cat^5 job^10&debug=all
示例
根据文档的流行度提升查询词 “hello” 的结果:
http://localhost:8983/solr/techproducts/select?defType=edismax&q=ipod&pf=text&qf=text&boost=popularity
使用负的boost
http://localhost:8983/solr/techproducts/select?defType=edismax&q=ipod&pf=text&qf=text&boost=sub(0,popularity)
搜索 iPod 或视频:
http://localhost:8983/solr/techproducts/select?defType=edismax&q=ipod+OR+video
在多个字段中搜索,指定(通过 boosts)每个字段相对于彼此的重要性:
http://localhost:8983/solr/techproducts/select?q=video&defType=edismax&qf=features^20.0+text^0.3
您可以提高具有与特定值匹配的字段的结果:
http://localhost:8983/solr/techproducts/select?q=video&defType=edismax&qf=features^20.0+text^0.3&bq=cat:electronics^5.0
使用“mm”参数,1和2个单词查询要求所有可选子句匹配,但对于具有三个或更多子句的查询,允许使用一个缺失子句:
http://localhost:8983/solr/techproducts/select?q=belkin+ipod&defType=edismax&mm=2
http://localhost:8983/solr/techproducts/select?q=belkin+ipod+gibberish&defType=edismax&mm=2
http://localhost:8983/solr/techproducts/select?q=belkin+ipod+apple&defType=edismax&mm=2
函数
solr查询也可使用函数,可用来过滤文档、提高相关性值、根据函数计算结果进行排序、以及返回函数计算结果。在标准查询解析器、dismax、edismax中都可以使用函数。
函数可以是
常量:数值或字符串字面值,如 10、”lucene solr”
字段: name title
另一个函数:functionName(…)
替代参数:
q={!func}min($f1,$f2)&f1=sqrt(popularity)&f2=1
函数的使用方式有:
用作函数查询,查询参数值是一个函数表达式,来计算相关性得分或过滤
q={!func}div(popularity,price)&fq={!frange l=1000}customer_ratings在排序中使用:
sort=div(popularity,price) desc, score desc在结果中使用:
&fl=sum(x, y),id,a,b,c,score&wt=xml
在加权参数 bf、boost中使用来计算权重
q=dismax&bf="ord(popularity)^0.5 recip(rord(price),1,1000,1000)^0.3"
在设置评分计算函数的特殊关键字 _val_ 中使用
q=_val_:mynumericfield _val_:"recip(rord(myfield),1,2,3)"
Function Query 函数查询说明:
函数查询:指我们在查询参数q、fq中使用了函数来改变相关性得分或过滤的一类特殊查询。函数对所有匹配的文档分别进行计算得到一个值作为一个加分值,加入到文档的相关性得分中。
改变评分:
方式一:整个查询就是一个函数表达式,匹配所有文档,文档的得分就是函数值
q=*:*
q={!func}div(popularity,price)&debug=all
说明:{!func} 说明q参数需要用func查询解析器来解析,func:Function Query Parser
方式二:值挂接,加入一个评分项,文档的得分=其他关键字得分 + 函数值
q=ipod AND _val_:"div(popularity,price)"&debug=all
方式三:查询解析器挂接(显示嵌套查询)
q=ipod AND _query_:"{!func}div(popularity,price)"&debug=all
方式四:查询解析器挂接(隐式嵌套查询)
q=ipod AND {!func v ="div(popularity,price)"}&debug=all
通过函数来过滤文档:
如果需要对搜索结果进行过滤,只留下函数计算产生特定值的文档,可以选择函数区间解析器(Function Range query parser,简称frange)。在q/fq参数中应用frange 执行一个特定的函数查询,然后过滤掉函数值落在最低值和最高值范围之外的文档。
q={!frange l=0.01 u=0.1}div(popularity,price)&debug=all
q=ipod&fq={!frange l=0.05 u=0.1}div(popularity,price)&debug=all
Solr中提供的函数:
官网参考:https://lucene.apache.org/solr/guide/7_3/function-queries.html#product-function
1.数据转换函数

2.数学函数
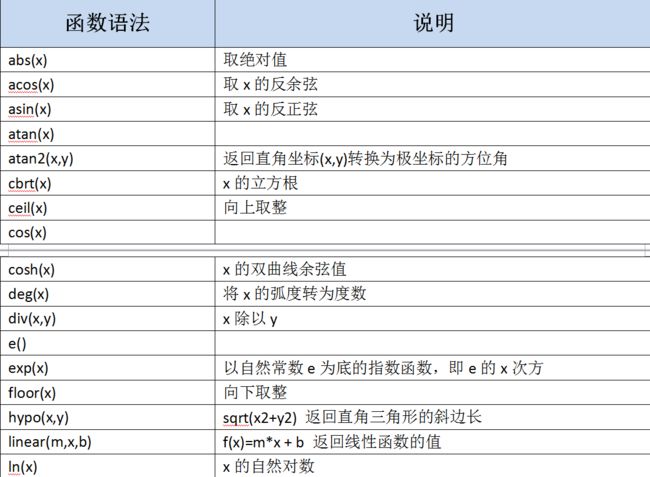
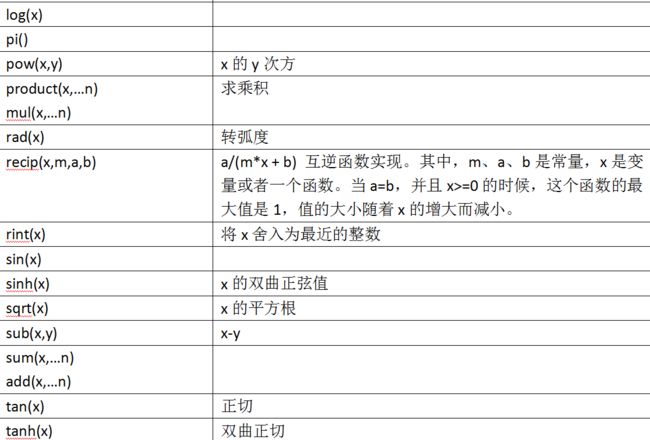
3.相关性函数
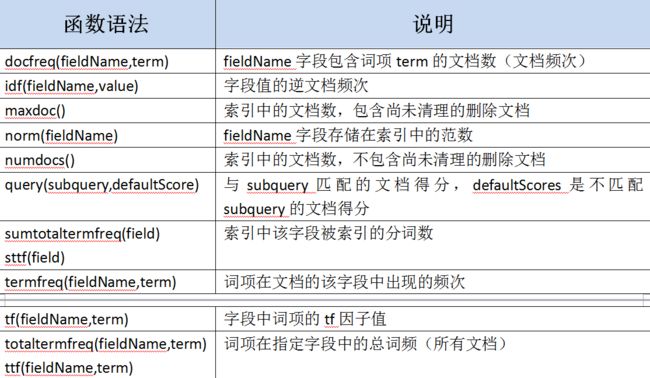
示例: doc1:(fieldX:A B C) and doc2:(fieldX:A A A A):
docFreq(fieldX:A) = 2 (A appears in 2 docs)
freq(doc1, fieldX:A) = 4 (A appears 4 times in doc 2)
totalTermFreq(fieldX:A) = 5 (A appears 5 times across all docs)
sumTotalTermFreq(fieldX) = 7 in fieldX, there are 5 As, 1 B, 1 C
利用函数查询和相关性函数,我们就可以自定义相关性计算模型。
4.布尔函数

4.距离函数


5.自定义函数
Solr中实现自定义函数非常简单。步骤如下:
1、编写一个函数类,这个类继承ValueSource类,保证在搜索索引中的每个文档都返回一个计算值。
2、编写ValueSourceParser类,它可以理解自定义函数的语法(在该类中你编写如何解析的逻辑),并将它解析成第1步自定义的ValueSource函数需要的变量。
3、向solrconfig.xml文件添加一个XML元素,定义自定义函数的名称及ValueSourceParser的类。当自定义函数通过函数名调用时,ValueSourceParser类将会解析ValuesSource中的输入。

什么是本地参数?
作为查询参数值的前缀,用来为查询参数添加元数据说明用的参数。看下面的查询:
q=solr rocks
如需要为这个查询说明是进行 AND 组合及默认查询字段是title:
q={!q.op=AND df=title}solr rocks
本地参数语法
作为查询参数值的前缀,用 {!key=value key=value} 包裹的多个key=value
本地参数用法示例
Query Type 的简写形式,type指定查询解析器
q={!dismax qf=myfield}solr rocks
q={!type=dismax qf=myfield}solr rocks通过v 关键字指定参数值
q={!dismax qf=myfield}solr rocks
q={!type=dismax qf=myfield v='solr rocks'}
参数引用
q={!dismax qf=myfield}solr rocks
q={!type=dismax qf=myfield v=$qq}&qq=solr rocks其他查询解析器
其他查询解析器,让我们可以在查询中灵活根据需要以本地参数的方式选用。
请参考官网: https://lucene.apache.org/solr/guide/7_3/other-parsers.html
小结
如何来写一个查询? 掌握语法 q
如何指定查询字段? Field: df qf
如何添加过滤条件?Fq {!frange}
如何指定返回字段? fl
如何指定排序? sort
如何为某个词项、短语加权?词项、短语^5
如何为字段加权? qf=title^10 pf pf2 pf3
如何用字段值来进行加权,如流行度、销量? _val_ _query_ 函数查询
如何查看某个查询的调试信息? debug