Python中的凝聚层次聚类示例
https://www.toutiao.com/a6641489713536434695/
2019-01-01 19:32:04
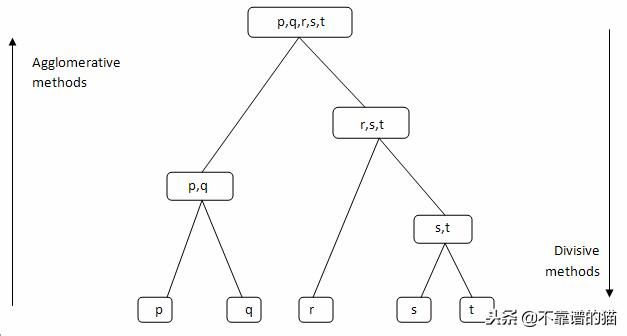
层次聚类算法将相似的对象分组到称为聚类的组中。层次聚类算法有两种:
- 凝聚(Agglomerative )-自下而上的方法。从许多小聚类开始,然后将它们合并到一起,创建更大的聚类。
- 分裂 (Divisive )- 自上而下的方法。从单个聚类开始,而不是将其拆分为更小的聚类。
层次聚类的一些优缺点
优点
- 不假设特定数量的聚类(即k均值)
- 可能对应于有意义的层次关系
缺点
- 一旦决定组合两个聚类,它就无法撤消
- 遇到大机器学习数据集时太慢,O(2log())
它时如何运作的
1.使每个数据点成为一个聚类

2.取两个最接近的聚类并使它们成为一个聚类
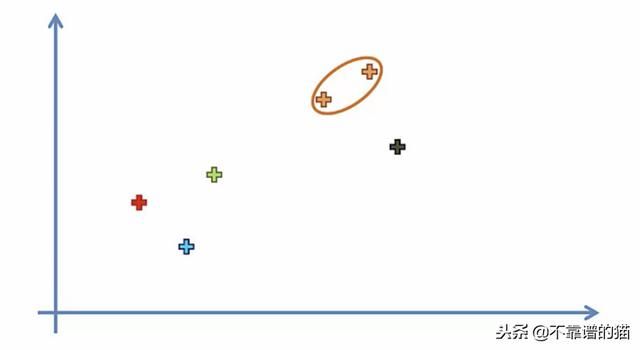
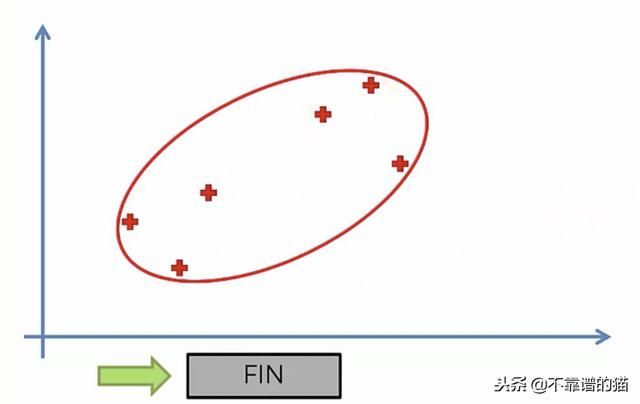
3.重复步骤2,直到只有一个聚类
树形图
我们可以使用树形图来显示分组的历史,并找出最佳的聚类数。
- 确定不与任何其他聚类相交的最大垂直距离
- 在两个末端画一条水平线
- 最佳聚类数等于通过水平线的垂直线数
例如,在下面的例子中,没有的最佳选择。集群将是4。

连接标准(Linkage Criteria)
与梯度下降类似,您可以调整某些参数以获得截然不同的结果。

连接标准指的是如何计算聚类之间的距离

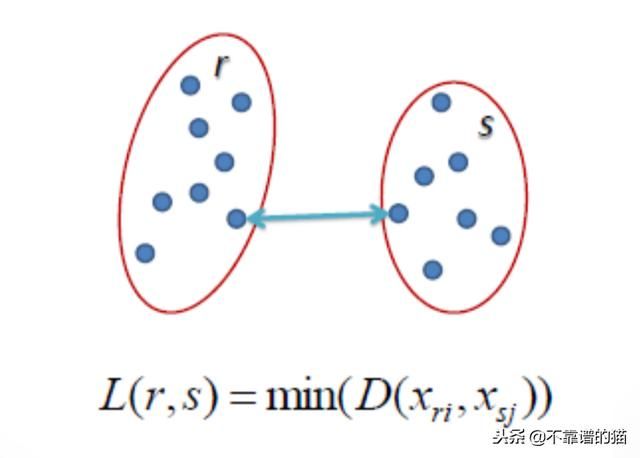
Single Linkage
两个聚类之间的距离是每个聚类中两点之间的最短距离
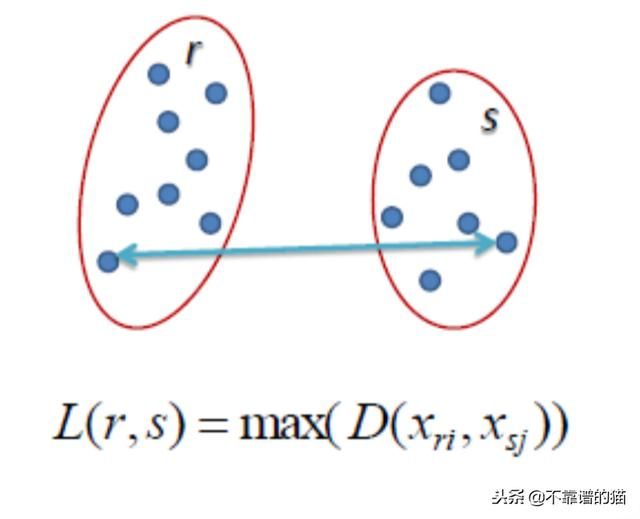
Complete Linkage
两个聚类之间的距离是每个聚类中两点之间的最长距离
Average Linkage
簇之间的距离是一个聚类中每个点与另一个聚类中每个点之间的平均距离

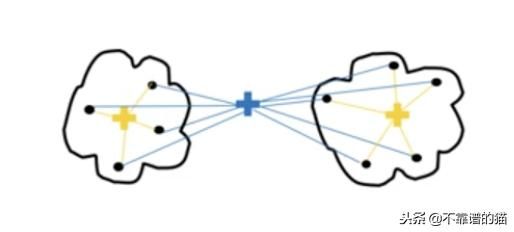
Ward Linkage
聚类之间的距离是所有聚类内的平方差的总和
距离度量
用于计算数据点之间距离的方法将影响最终结果。
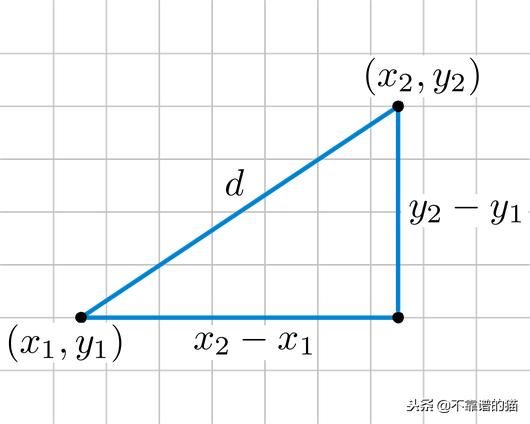
欧几里德距离
两点之间的最短距离。例如,如果x =(a,b)和y =(c,d),则x和y之间的欧几里德距离为√((a-c)²+(b-d)²)
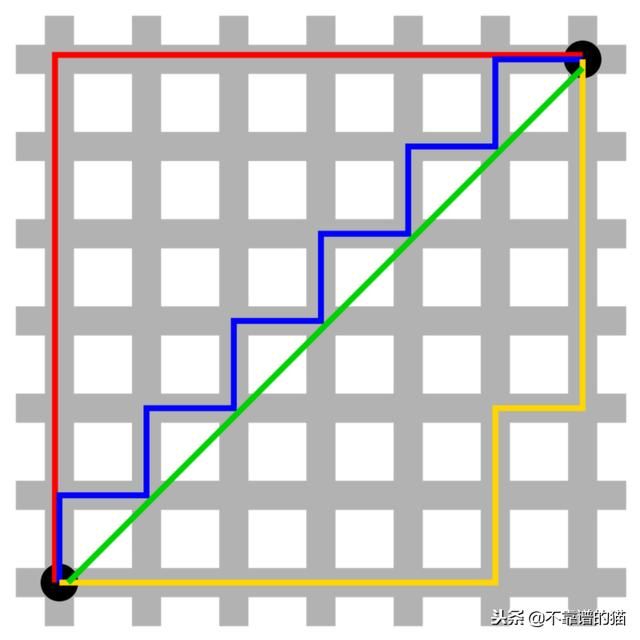
曼哈顿距离
想象一下,你在一个大城市的市中心,你想要从A点到达B点。你将无法跨越建筑物,而是你必须沿着各条街道行走。例如,如果x =(a,b)和y =(c,d),则x和y之间的曼哈顿距离是| a-c | + | b-d |。
python中的示例
让我们看看如何使用层次凝聚聚类来标记机器学习数据的具体示例。
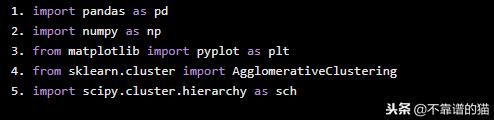
import pandas as pd import numpy as np from matplotlib import pyplot as plt from sklearn.cluster import AgglomerativeClustering import scipy.cluster.hierarchy as sch
在本教程中,我们使用包含客户列表的csv文件及其gender, age, annual income 和 spending score。机器学习数据库的下载地址:http://www.kankanyun.com/data/Mall_Customers.csv

为了在以后的图表上显示我们的数据,我们只能采用两个变量(annual income 和spending score)。
dataset = pd.read_csv('./data.csv')
X = dataset.iloc[:, [3, 4]].values

观察树状图,与任何聚类不相交的最高垂直距离是中间的绿色。假设5条垂直线超过阈值,则最佳聚类数为5。
dendrogram = sch.dendrogram(sch.linkage(X, method='ward'))

我们利用欧几里得距离来创建AgglomerativeClustering的实例,其中该欧几里得距离是指点之间的距离和用于计算聚类的接近度的距离。
model = AgglomerativeClustering(n_clusters=5, affinity='euclidean', linkage='ward') model.fit(X) labels = model.labels_

该labels_属性返回一个整数数组,其中值对应于不同的类。

我们可以使用简写表示法将属于某个类的所有样本显示为特定颜色。
plt.scatter(X[labels==0, 0], X[labels==0, 1], s=50, marker='o', color='red') plt.scatter(X[labels==1, 0], X[labels==1, 1], s=50, marker='o', color='blue') plt.scatter(X[labels==2, 0], X[labels==2, 1], s=50, marker='o', color='green') plt.scatter(X[labels==3, 0], X[labels==3, 1], s=50, marker='o', color='purple') plt.scatter(X[labels==4, 0], X[labels==4, 1], s=50, marker='o', color='orange') plt.show()
