基于Keras预训练词向量模型的文本分类方法
本文语料仍然是上篇所用的搜狗新闻语料,采用中文预训练词向量模型对词进行向量表示。上篇文章将文本分词之后,采用了TF-IDF的特征提取方式对文本进行向量化表示,所产生的文本表示矩阵是一个稀疏矩阵,本篇采用的词向量是一个稠密向量,可以理解为将文本的语义抽象信息嵌入到了一个具体的多维空间中,词之间语义关系可以用向量空间中的范数计算来表示。本文代码在GitHub上。
1. 读取语料
读取语料与上一篇略有区别,这里读取原始语料,划分训练集和测试集,放在了后面预处理部分。
texts, labels = load_raw_datasets()
label: C000008, len: 1990
label: C000010, len: 1990
label: C000013, len: 1990
label: C000014, len: 1990
label: C000016, len: 1990
label: C000020, len: 1990
label: C000022, len: 1990
label: C000023, len: 1990
label: C000024, len: 1990
Done. 9 total categories, 17910 total docs. cost 224.0759744644165 seconds.
注意到,所有文本读入到texts列表中,标签信息读入到labels列表中。每个文本所在目录名称作为分类标签,在创建labels列表时,代码中做了一步处理,读入目录时的序号存入labels列表中(第一个标签为0,第二个标签为1,依次类推),后面在使用keras对文本进行预处理的过程中,将调用to_categorical将整数类别标签转为向量分类编码,这是为了使用分类交叉熵损失函数categorical_crossentropy。这里可以了解一下关于各类统计变量间的区别:Difference between categorical and ordinal variables。
下表是转换后的标签表示:
| 序号 | 标签 | 名称 | 分类编码 |
|---|---|---|---|
| 0 | C000008 | Finance | [1, 0, 0, 0, 0, 0, 0, 0, 0] |
| 1 | C000010 | IT | [0, 1, 0, 0, 0, 0, 0, 0, 0] |
| 2 | C000013 | Health | [0, 0, 1, 0, 0, 0, 0, 0, 0] |
| 3 | C000014 | Sports | [0, 0, 0, 1, 0, 0, 0, 0, 0] |
| 4 | C000016 | Travel | [0, 0, 0, 0, 1, 0, 0, 0, 0] |
| 5 | C000020 | Education | [0, 0, 0, 0, 0, 1, 0, 0, 0] |
| 6 | C000022 | Recruit | [0, 0, 0, 0, 0, 0, 1, 0, 0] |
| 7 | C000023 | Culture | [0, 0, 0, 0, 0, 0, 0, 1, 0] |
| 8 | C000024 | Military | [0, 0, 0, 0, 0, 0, 0, 0, 1] |
分类编码其实就是one-hot编码,可以用代码解释一下这个转换过程:
def to_one_hot(labels):
one_hot = np.zeros((len(labels), len(labels)))
for i, label in enumerate(labels):
one_hot[i, label] = 1.
return one_hot
print(to_one_hot([0,1,2,3,4,5,6,7,8]))
在keras有内置函数
from keras.utils import to_categorical
print(to_categorical([0,1,2,3,4,5,6,7,8]))
如果想要将向量分类编码转回整数类别标签,可以用numpy中的argmax函数:
from numpy import argmax
argmax(labels[0])
2. 加载预训练词向量模型
解压之后的中文预训练词向量模型的文件格式是文本文件,首行只有两个空格隔开的数字:词的个数和词向量的维度,从第二行开始格式为:词 数字1 数字2 …… 数字300,形式如下:
364180 300
人民文学出版社 0.003146 0.582671 0.049029 -0.312803 0.522986 0.026432 -0.097115 0.194231 -0.362708 …
…
# 读取预训练模型
import numpy as np
embeddings_index = {}
with open('Embedding/sgns.sogou.word') as f:
num, embedding_dim = f.readline().split()
for line in f:
values = line.split()
word = values[0]
coefs = np.asarray(values[1:], dtype='float32')
embeddings_index[word] = coefs
print('Found %s word vectors, dimension %s' % (len(embeddings_index), embedding_dim))
Found 364180 word vectors, dimension 300
3. 使用Keras对语料进行处理
在上篇文章中,我们使用了TfidfVectorizer,将训练语料转换为TFIDF矩阵,每个向量的长度相同(等于总语料库词汇量的大小)。本文将使用Keras中的Tokenizer对文本进行处理,每个向量等于每个文本的长度,这个长度在处理的时候由变量MAX_SEQUENCE_LEN做了限制,其数值并不表示计数,而是对应于字典tokenizer.word_index中的单词索引值,这个字典是在调用Tokenizer时产生。
长度超过MAX_SEQUENCE_LEN的文本序列会被截断,长度小于这个值的文本序列则需要补零来达到这个长度,Keras中的pad_sequence()就是用零来填充向量序列。形式如下:
pad_sequences([[1,2,3,4,5],[6,7,8,9]], maxlen=10)
array([[0, 0, 0, 0, 0, 1, 2, 3, 4, 5],
[0, 0, 0, 0, 0, 0, 6, 7, 8, 9]], dtype=int32)
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
import numpy as np
MAX_SEQUENCE_LEN = 1000 # 文档限制长度
MAX_WORDS_NUM = 20000 # 词典的个数
VAL_SPLIT_RATIO = 0.2 # 验证集的比例
tokenizer = Tokenizer(num_words=MAX_WORDS_NUM)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
print(len(word_index)) # all token found
# print(word_index.get('新闻')) # get word index
dict_swaped = lambda _dict: {val:key for (key, val) in _dict.items()}
word_dict = dict_swaped(word_index) # swap key-value
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LEN)
labels_categorical = to_categorical(np.asarray(labels))
print('Shape of data tensor:', data.shape)
print('Shape of label tensor:', labels_categorical.shape)
indices = np.arange(data.shape[0])
np.random.shuffle(indices)
data = data[indices]
labels_categorical = labels_categorical[indices]
# split data by ratio
val_samples_num = int(VAL_SPLIT_RATIO * data.shape[0])
x_train = data[:-val_samples_num]
y_train = labels_categorical[:-val_samples_num]
x_val = data[-val_samples_num:]
y_val = labels_categorical[-val_samples_num:]
263284
Shape of data tensor: (17910, 1000)
Shape of label tensor: (17910, 9)
list(word_index.items())[90]
('儿童', 958)
代码中word_index表示发现的所有词,得到的文本序列取的是word_index中前面20000个词对应的索引,文本序列集合中的所有词的索引号都在20000之前:
len(data[data>=20000])
0
我们可以通过生成的词索引序列和对应的索引词典查看原始文本和对应的标签:
# convert from index to origianl doc
for w_index in data[0]:
if w_index != 0:
print(word_dict[w_index], end=' ')
昆虫 大自然 歌手 昆虫 口腔 发出 昆虫 界 著名 腹部 一对 是从 发出 外面 一对 弹性 称作 声 肌 相连 发音 肌 收缩 振动 声音 空间 响亮 传到 5 0 0 米 求婚 听到 发音 部位 发音 声音 两 张开 蚊子 一对 边缘 支撑 两只 每秒 2 5 0 ~ 6 0 0 次 推动 空气 往返 运动 发出 微弱 声 来源 语文
category_labels[dict_swaped(labels_index)[argmax(labels_categorical[0])]]
'_20_Education'
4. 定义词嵌入矩阵
下面创建一个词嵌入矩阵,用来作为上述文本集合词典(只取序号在前MAX_WORDS_NUM的词,对应了比较常见的词)的词嵌入矩阵,矩阵维度是(MAX_WORDS_NUM, EMBEDDING_DIM)。
矩阵的每一行i代表词典word_index中第i个词的词向量。这个词嵌入矩阵是预训练词向量的一个子集。语料中很可能有的词不在预训练词向量中,这样的词在这个词向量矩阵中对应的向量元素都设为零。在本例中,20000个词有92.35%在预训练词向量中。
EMBEDDING_DIM = 300 # embedding dimension
embedding_matrix = np.zeros((MAX_WORDS_NUM+1, EMBEDDING_DIM)) # row 0 for 0
for word, i in word_index.items():
embedding_vector = embeddings_index.get(word)
if i < MAX_WORDS_NUM:
if embedding_vector is not None:
# Words not found in embedding index will be all-zeros.
embedding_matrix[i] = embedding_vector
nonzero_elements = np.count_nonzero(np.count_nonzero(embedding_matrix, axis=1))
nonzero_elements / MAX_WORDS_NUM
0.9235
Embedding Layer
下面代码中用keras构建神经网络文本分类模型时,用到了嵌入层Embedding。关于嵌入层(Keras Embedding Layer API),这篇文章有比较详细的介绍。嵌入层的目的是将输入序列中的整数索引转换成一个稠密的向量,嵌入层的输入是一个2D张量,形状为(batch_size, sequence_length),输出是3D张量,形状为(batch_size, sequence_length, output_dim)。
嵌入层的输入数据sequence向量的整数元素对应词的编码,前面看到这个获取序列编码的步骤使用了Keras的Tokenizer API来实现,如果不使用预训练词向量模型,嵌入层是用随机权重进行初始化,在训练中将学习到训练集中的所有词的权重,也就是词向量。在定义Embedding层,需要至少3个输入数据:
input_dim:文本词典的大小,本例中就是MAX_WORDS_NUM + 1output_dim:词嵌入空间的维度,就是词向量的长度,本例中对应EMBEDDING_DIMinput_length:这是输入序列的长度,本例中对应MAX_SEQUENCE_LEN
本文中用到了另外两个输入参数weights=[embedding_matrix]和trainable=False,前者设置该层的嵌入矩阵为上面我们定义好的词嵌入矩阵,即不使用随机初始化的权重,后者设置为本层参数不可训练,即不会随着后面模型的训练而更改。这里涉及了Embedding层的几种使用方式:
- 从头开始训练出一个词向量,保存之后可以用在其他的训练任务中
- 嵌入层作为深度学习的第一个隐藏层,本身就是深度学习模型训练的一部分
- 加载预训练词向量模型,这是一种迁移学习,本文就是这样的示例
5. 构建模型
Keras支持两种类型的模型结构:
- Sequential类,顺序模型,这个仅用于层的线性堆叠,最常见的网络架构
- Functional API,函数式API,用于层组成的有向无环图,可以构建任意形式的架构
为了有个对比,我们先不加载预训练模型,让模型自己训练词权重向量。Flatten层用来将输入“压平”,即把多维的输入一维化,这是嵌入层的输出转入全连接层(Dense)的必需的过渡。
input_dim = x_train.shape[1]
model1 = Sequential()
model1.add(Embedding(input_dim=MAX_WORDS_NUM+1,
output_dim=EMBEDDING_DIM,
input_length=MAX_SEQUENCE_LEN))
model1.add(Flatten())
model1.add(Dense(64, activation='relu', input_shape=(input_dim,)))
model1.add(Dense(64, activation='relu'))
model1.add(Dense(len(labels_index), activation='softmax'))
model1.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
history1 = model1.fit(x_train,
y_train,
epochs=30,
batch_size=128,
validation_data=(x_val, y_val))
Train on 14328 samples, validate on 3582 samples
Epoch 1/30
14328/14328 [==============================] - 59s 4ms/step - loss: 3.1273 - acc: 0.2057 - val_loss: 1.9355 - val_acc: 0.2510
Epoch 2/30
14328/14328 [==============================] - 56s 4ms/step - loss: 2.0853 - acc: 0.3349 - val_loss: 1.8037 - val_acc: 0.3473
Epoch 3/30
14328/14328 [==============================] - 56s 4ms/step - loss: 1.7210 - acc: 0.4135 - val_loss: 1.2498 - val_acc: 0.5731
......
Epoch 29/30
14328/14328 [==============================] - 56s 4ms/step - loss: 0.5843 - acc: 0.8566 - val_loss: 1.3564 - val_acc: 0.6516
Epoch 30/30
14328/14328 [==============================] - 56s 4ms/step - loss: 0.5864 - acc: 0.8575 - val_loss: 0.5970 - val_acc: 0.8501
每个Keras层都提供了获取或设置本层权重参数的方法:
layer.get_weights():返回层的权重(numpy array)layer.set_weights(weights):从numpy array中将权重加载到该层中,要求numpy array的形状与layer.get_weights()的形状相同
embedding_custom = model1.layers[0].get_weights()[0]
embedding_custom
array([[ 0.39893672, -0.9062594 , 0.35500282, ..., -0.73564297,
0.50492775, -0.39815223],
[ 0.10640696, 0.18888871, 0.05909824, ..., -0.1642032 ,
-0.02778293, -0.15340094],
[ 0.06566656, -0.04023357, 0.1276007 , ..., 0.04459211,
0.08887506, 0.05389333],
...,
[-0.12710813, -0.08472785, -0.2296919 , ..., 0.0468552 ,
0.12868881, 0.18596107],
[-0.03790742, 0.09758633, 0.02123675, ..., -0.08180046,
0.10254312, 0.01284804],
[-0.0100647 , 0.01180602, 0.00446023, ..., 0.04730382,
-0.03696882, 0.00119566]], dtype=float32)
get_weights方法得到的就是词嵌入矩阵,如果本例中取的词典足够大,这样的词嵌入矩阵就可以保存下来,作为其他任务的预训练模型使用。通过get_config()可以获取每一层的配置信息:
model1.layers[0].get_config()
{'activity_regularizer': None,
'batch_input_shape': (None, 1000),
'dtype': 'float32',
'embeddings_constraint': None,
'embeddings_initializer': {'class_name': 'RandomUniform',
'config': {'maxval': 0.05, 'minval': -0.05, 'seed': None}},
'embeddings_regularizer': None,
'input_dim': 20001,
'input_length': 1000,
'mask_zero': False,
'name': 'embedding_13',
'output_dim': 300,
'trainable': True}
可以将模型训练的结果打印出来
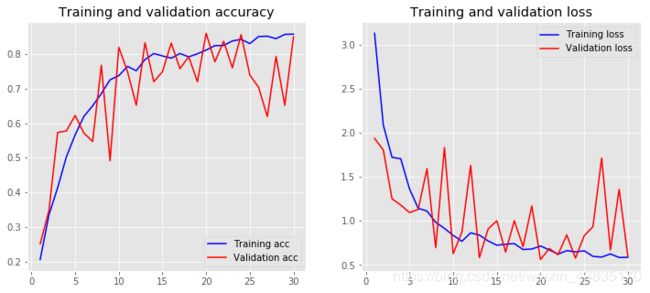
第一个模型训练时间花了大约30分钟训练完30个epoch,下面第二个模型在第一个模型基础上加载词嵌入矩阵,看是否可以提高训练的效率。
model2 = Sequential()
model2.add(Embedding(input_dim=MAX_WORDS_NUM+1,
output_dim=EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LEN,
trainable=False))
model2.add(Flatten())
model2.add(Dense(64, activation='relu', input_shape=(input_dim,)))
model2.add(Dense(64, activation='relu'))
model2.add(Dense(len(labels_index), activation='softmax'))
model2.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
history2 = model2.fit(x_train,
y_train,
epochs=10,
batch_size=128,
validation_data=(x_val, y_val))
Train on 14328 samples, validate on 3582 samples
Epoch 1/10
14328/14328 [==============================] - 37s 3ms/step - loss: 1.3124 - acc: 0.6989 - val_loss: 0.7446 - val_acc: 0.8088
Epoch 2/10
14328/14328 [==============================] - 35s 2ms/step - loss: 0.2831 - acc: 0.9243 - val_loss: 0.5712 - val_acc: 0.8551
Epoch 3/10
14328/14328 [==============================] - 35s 2ms/step - loss: 0.1183 - acc: 0.9704 - val_loss: 0.6261 - val_acc: 0.8624
Epoch 4/10
14328/14328 [==============================] - 35s 2ms/step - loss: 0.0664 - acc: 0.9801 - val_loss: 0.6897 - val_acc: 0.8607
Epoch 5/10
14328/14328 [==============================] - 35s 2ms/step - loss: 0.0549 - acc: 0.9824 - val_loss: 0.7199 - val_acc: 0.8660
Epoch 6/10
14328/14328 [==============================] - 35s 2ms/step - loss: 0.0508 - acc: 0.9849 - val_loss: 0.7261 - val_acc: 0.8582
Epoch 7/10
14328/14328 [==============================] - 35s 2ms/step - loss: 0.0513 - acc: 0.9865 - val_loss: 0.8251 - val_acc: 0.8585
Epoch 8/10
14328/14328 [==============================] - 35s 2ms/step - loss: 0.0452 - acc: 0.9858 - val_loss: 0.7891 - val_acc: 0.8707
Epoch 9/10
14328/14328 [==============================] - 35s 2ms/step - loss: 0.0469 - acc: 0.9865 - val_loss: 0.8663 - val_acc: 0.8680
Epoch 10/10
14328/14328 [==============================] - 35s 2ms/step - loss: 0.0418 - acc: 0.9867 - val_loss: 0.9048 - val_acc: 0.8640

从第二个模型训练结果可以看到预训练模型的加载可以大幅提高模型训练的效率,模型的验证准确度也提升的比较快,但是同时发现在训练集上出现了过拟合的情况。
第三个模型的结构来自于Keras作者的博客示例,这是CNN用于文本分类的例子。
embedding_layer = Embedding(input_dim=MAX_WORDS_NUM+1,
output_dim=EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LEN,
trainable=False)
sequence_input = Input(shape=(MAX_SEQUENCE_LEN,), dtype='int32')
embedded_sequences = embedding_layer(sequence_input)
x = Conv1D(128, 5, activation='relu')(embedded_sequences)
x = MaxPooling1D(5)(x)
x = Conv1D(128, 5, activation='relu')(x)
x = MaxPooling1D(5)(x)
x = Conv1D(128, 5, activation='relu')(x)
x = MaxPooling1D(35)(x) # global max pooling
x = Flatten()(x)
x = Dense(128, activation='relu')(x)
preds = Dense(len(labels_index), activation='softmax')(x)
model3 = Model(sequence_input, preds)
model3.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['acc'])
history3 = model3.fit(x_train,
y_train,
epochs=6,
batch_size=128,
validation_data=(x_val, y_val))
Train on 14328 samples, validate on 3582 samples
Epoch 1/6
14328/14328 [==============================] - 77s 5ms/step - loss: 0.9943 - acc: 0.6719 - val_loss: 0.5129 - val_acc: 0.8582
Epoch 2/6
14328/14328 [==============================] - 76s 5ms/step - loss: 0.4841 - acc: 0.8571 - val_loss: 0.3929 - val_acc: 0.8841
Epoch 3/6
14328/14328 [==============================] - 77s 5ms/step - loss: 0.3483 - acc: 0.8917 - val_loss: 0.4022 - val_acc: 0.8724
Epoch 4/6
14328/14328 [==============================] - 77s 5ms/step - loss: 0.2763 - acc: 0.9100 - val_loss: 0.3441 - val_acc: 0.8942
Epoch 5/6
14328/14328 [==============================] - 76s 5ms/step - loss: 0.2194 - acc: 0.9259 - val_loss: 0.3014 - val_acc: 0.9107
Epoch 6/6
14328/14328 [==============================] - 77s 5ms/step - loss: 0.1749 - acc: 0.9387 - val_loss: 0.3895 - val_acc: 0.8788
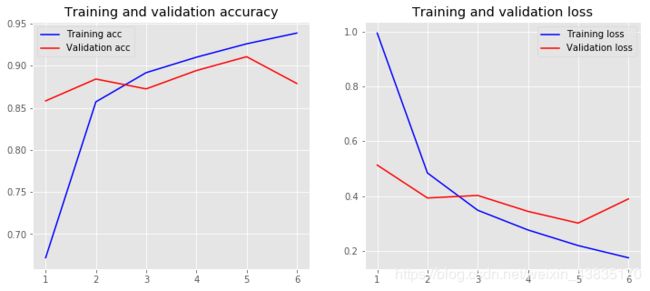
通过加入池化层MaxPooling1D,降低了过拟合的情况。验证集上的准确度超过了前两个模型,也超过了上篇文章中介绍的传统机器学习方法。
完整代码在GitHub.
6. 参考资料
- Deep Learning, NLP, and Representations
- Keras Embedding Layers API
- How to Use Word Embedding Layers for Deep Learning with Keras
- Practical Text Classification With Python and Keras
- Francois Chollet: Using pre-trained word embeddings in a Keras model